Introduction
Apache Spark is an open-source distributed general-purpose cluster computing framework. It provides an interface for programming entire clusters with implicit data parallelism and fault tolerance.
Spark was initially developed in 2009 at UC Berkeley and open-sourced in 2010 as an Apache project. Gradually, it gained popularity and quickly emerged as the preferred big data platform for businesses. A recent survey indicates that over 60% of enterprises dealing with data have implemented Spark.
Some key reasons for Spark's popularity are its ease of use, speed and unified architecture. Spark allows developers to quickly write applications in Java, Scala, Python or R and easily build data pipelines. It also runs workloads up to 100x faster than Hadoop MapReduce in memory or 10x faster on disk. Spark offers over 80 high-level operators to make parallel jobs easy.
In this comprehensive tutorial, we will understand what Spark is, its features, architecture and other related concepts in detail.
Overview of Spark Architecture
Spark has a well-defined layered architecture comprising the Spark Core and built-in libraries including SQL, DataFrames, MLlib, GraphX, and Spark Streaming.
The key components of the Spark architecture are:
- Cluster Manager - Manages the cluster and resources (e.g. YARN, Mesos)
- Spark Core - Provides distributed task dispatching, scheduling, and basic I/O functionalities
- DataFrames - Distributed collection of data organized into named columns
- Spark SQL - Module for structured data processing and relational queries
- Libraries - Packages for machine learning, graph processing and streaming
This separation of responsibilities allows each component to focus on only one function leading to a modular and versatile framework.
What is Spark SQL?
Spark SQL Tutorial:
Spark SQL is a Spark module used for structured data processing and relational queries. It provides a DataFrame API to write SQL-like queries in Python, Java, or Scala.
Spark SQL also includes a SQL parser and optimizer that allow running regular ANSI SQL statements. It can work with various data sources like Hive, Avro, Parquet, ORC, JSON, and JDBC.
Some key benefits of Spark SQL:
- Allows querying both structured and unstructured data using the same framework.
- SQL queries are optimized and translated into native Spark code for the best performance.
- Allows use of DataFrame API and SQL interchangeably in Spark applications.
Let's look at some simple spark code examples to highlight Spark's APIs.
1. We can create a DataFrame from JSON data:
data = [{"Category":"Fiction", "Title":"To Kill a Mockingbird", "Author":"Harper Lee", "Price":7.99},
{"Category":"Fiction", "Title":"1984", "Author":"George Orwell", "Price":9.99}]
df = spark.createDataFrame(data)
df.show()Output:
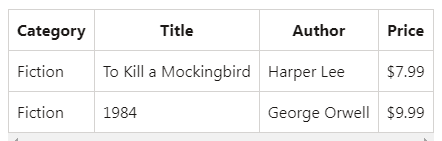
2. We can run SQL queries on DataFrames interactively:
df.createOrReplaceTempView("books")
spark.sql("SELECT * FROM books WHERE Price < 8").show()Output:
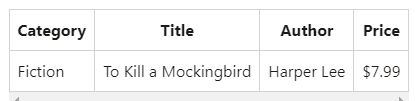
3. We can also create permanent tables, insert data and run SQL queries:
spark.sql("CREATE TABLE books (Category STRING, Title STRING, Author STRING, Price FLOAT)")
spark.sql("INSERT INTO books VALUES ('Fiction', 'To Kill a Mockingbird', 'Harper Lee', 7.99)")
spark.sql("SELECT * FROM books").show()Output:
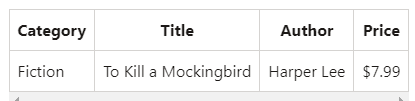
4. Spark SQL supports SQL join operations between DataFrames:
authors_df = spark.createDataFrame([
("1001", "Harper Lee", "To Kill a Mockingbird"),
("1002", "George Orwell", "1984")
], ["id", "name", "book"])
authors_df.show()
book_sales_df = spark.createDataFrame([
("To Kill a Mockingbird", 10),
("1984", 5)
], ["book", "quantity"])
book_sales_df.show()
joined_df = authors_df.join(book_sales_df, authors_df.book == book_sales_df.book, 'inner')
joined_df.show()
Output:
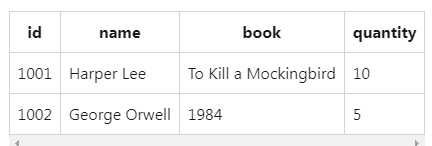
What is Apache Spark?
Apache Spark is a lightning-fast unified analytics engine for big data and machine learning. It was built to overcome the limitations of Hadoop MapReduce which was slow for iterative algorithms that visit data set multiple times.
Some key capabilities of Spark include the following:
- Speed: Spark runs up to 100x faster than Hadoop for iterative algorithms like k-means clustering and logistic regression.
- Ease of Use: Spark offers over 80 high-level operators like map, reduce, join, and window that makes parallel jobs easy. It also has built-in SQL, machine learning, graph processing and streaming modules.
- General Purpose: Spark provides a unified engine that can run batch, interactive, iterative and streaming workloads.
Simply put, Apache Spark is a framework designed to handle and analyze vast amounts of data. It offers speed, user-friendliness and adaptability, in processing datasets. It addresses the limitations of MapReduce by running workloads faster through in-memory computation.
This broad range of capabilities has made Spark an essential tool for data engineers, data scientists, analysts and more.
History of Apache Spark
Let's briefly look at how Apache Spark evolved:
- 2009 - Spark originated at UC Berkeley in 2009 as a research project in the AMPLab by Matei Zaharia. The goal was to create an open-source cluster computing framework that was fast and general purpose.
- 2010 - Spark was open-sourced in 2010 under a BSD license as an Apache project. It became Apache Spark later that year.
- 2013 - Spark grew in popularity in 2013 after the addition of Spark SQL. This allowed users to run SQL queries alongside Spark programs using DataFrames.
- 2014 - Spark became a top-level Apache project in 2014, indicating its success. Spark also added Spark Streaming for processing live data streams.
- 2015 - Spark continued to enhance its capabilities in 2015 by adding the Spark MLlib machine learning library and GraphX graph processing component.
- 2016 - Present - Apache Spark has seen further growth in users, contributors and meetups. Its speed, ease of use and unified architecture have made it the preferred choice for big data workloads. Spark also continues to add new Data Sources, SQL and ML features.
Features of Apache Spark
Spark offers many features, making it an ideal platform for processing big data workloads. Some of the key features are:
Speed
Spark utilizes in-memory computation and optimized execution for performance. It can run workloads up to 100x faster than Hadoop MapReduce. Spark achieves this speed through the following:
- In-memory data storage - Spark keeps data loaded in-memory by default in a distributed manner across the cluster.
- Lazy evaluation - Spark delays actual computation until it is required. This avoids unnecessary passes over the data.
Ease of Use
Spark offers over 80 high-level operators to parallelize data operations. This makes it easy to create parallel apps without writing boilerplate code.
Some of the key APIs are:
- Spark SQL - Allows running SQL queries alongside Spark programs. Queries can be written using either SQL or DataFrame API.
- DataFrames - Provides a Dataset organized into named columns for structured data processing. Similar to tables in a database.
- Spark Streaming - Enables processing of live streams of data in real-time using mini-batch processing.
- MLlib - Includes standard machine learning algorithms like classification, regression, clustering, collaborative filtering, etc.
- GraphX - Provides APIs for graph-parallel computation like Pregel.
General Purpose
Spark provides a unified engine that supports a broad range of data analytics tasks, including batch, interactive, iterative, and streaming workloads. This eliminates the need to use separate tools.
Some of the workloads Spark handles well:
- Batch processing - Spark is suitable for batch-processing jobs over massive datasets. E.g., ETL, data warehousing.
- Interactive queries - This queries data interactively using SQL or directly from Spark shell.
- Iterative algorithms - Spark efficiently runs iterative algorithms like k-means, PageRank, etc.
- Streaming analytics - It processes live data streams with sub-second latency using Spark streaming.
Runs Everywhere
Spark runs on a variety of environments, from on-premise data centers to public cloud platforms. Spark can access data from many sources:
- Standalone - Spark can run in standalone mode on your laptop or cluster. Useful during development.
- Hadoop YARN - Spark can run on top of YARN to access data from HDFS, HBase. No need to install Spark on all nodes.
- Apache Mesos - General cluster manager that also supports running Spark applications.
- Kubernetes - Spark can run on top of Kubernetes for container orchestration.
- Cloud platforms - Spark is available on all major cloud platforms like AWS, Azure, GCP.
Usage of Spark
Spark is a general-purpose framework for data analytics that offers ease of development. Let's look at some examples of how Spark is commonly used:
Spark is utilized for large batch processing workloads such as ETL pipelines, data warehousing, and log processing. Batch jobs are well suited for Spark as they can efficiently handle large amounts of data through distributed processing.
For example, an e-commerce company processes clickstream logs of 100 GB per day. Using Spark, this data can be loaded and cleaned using Spark SQL. We can then analyze this data with Spark MLlib to generate user behavior insights.
Interactive Data Analysis
Spark allows querying data interactively through Spark SQL or directly from Spark shell. Analysts can connect BI tools like Tableau to Spark to generate reports and dashboards from the latest data.
For example, a retail bank loads HDFS data into Spark hourly. Analysts then query this data interactively to analyze customer trends and generate daily reports.
Spark MLlib provides commonly used machine learning algorithms that can be applied to large datasets. Tasks like fraud detection, product recommendations, predictive maintenance, etc., can leverage Spark's distributed processing.
For example, an insurance firm builds Spark ML models to predict fraudulent claims by analyzing past claim data. These models are retrained nightly as new claims come in.
Machine Learning Example
We can use Spark MLlib to build a logistic regression classifier:
Code:
from pyspark.ml.classification import LogisticRegression
# Load training data
training = spark.read.format("libsvm")\
.load("data/mllib/sample_libsvm_data.txt")
lr = LogisticRegression(maxIter=10, regParam=0.3, elasticNetParam=0.8)
# Fit model
model = lr.fit(training)
# Print coefficients and intercept
print("Coefficients: " + str(model.coefficients))
print("Intercept: " + str(model.intercept))
Output:
Coefficients: [0.5144343718982989,-0.22079497603262063,-0.4756967403873508,1.0316237691599358,-0.3059612781510368,-0.013700513924638212,-0.41385474153683273,-0.2784643572432388]
Intercept: -1.768966151113195
Stream Processing
Spark Streaming allows mini-batch processing on live streams of data. This enables real-time analytics for digital ad clicks, IoT sensors, financial trades, etc.
For example, a ride-sharing company uses Spark Streaming to process real-time trip data. The stream data is analyzed to identify frequent locations and surge pricing opportunities.
Graph Processing
Spark GraphX allows graph parallel computation for tasks like social network analysis, fraud detection, recommendations, etc. The graph algorithms use graph abstraction with automatic optimization.
For example, a bank uses GraphX to analyze money transfer graphs and identify potentially fraudulent transactions and accounts in real time.
In summary, Spark is a versatile framework used for batch processing, interactive analysis, machine learning, streaming, and graph workloads on big data. The unified API makes it easy to combine these capabilities.
Conclusion
In this comprehensive Spark tutorial for beginners, we covered the following:
- What is Spark - A fast unified analytics engine for large-scale data processing
- History of Spark - Evolved from a UC Berkeley research project to a widely used open-source framework
- Features of Spark - Speed, ease of use, versatility, and environment support make Spark powerful
- Usage of Spark - Commonly used for batch, interactive, machine learning, streaming, and graph workloads
Spark is transforming big data analytics by enabling fast distributed processing on a versatile platform. Its adoption will continue to grow exponentially as data volumes explode. This makes it a must-learn skill for data professionals looking to supercharge their careers.
FAQs
1. What languages does Apache Spark support?
Spark code can be written in Java, Scala, Python, R. Scala is the most commonly used.
2. How does Spark achieve speed?
Spark uses in-memory computing, lazy evaluation and code optimization to run workloads up to 100x faster than MapReduce.
3. What are some Spark use cases?
Spark is used for ETL, data analysis, machine learning, fraud detection, and recommendations on large datasets.











-d9bdeff6165f4eb1ba2adcebde78e961.svg)







-ae8d039bbd2a41318308f8d26b52ac8f.svg)
-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)

%20(2)-db0b6f38da9c485faf76e366793c9b9e.webp&w=128&q=75)













