Introduction
This tutorial offers a deep exploration of two key concepts in SQL: clustered and non-clustered indexes. These indexes play a critical role in how data is organized, stored, and retrieved within database systems. Our guide will systematically elucidate the properties, distinctions, and appropriate use scenarios, plus the pros and cons associated with these indexes. This resource is particularly beneficial for professionals aiming to expand their knowledge and enhance their proficiency in SQL.
Overview
As SQL professionals, understanding and leveraging the power of indexes is crucial to enhance database performance. This comprehensive guide serves as a deep dive into the realm of clustered and non-clustered index, emphasizing their practical applications in real-world scenarios.
Clustered Index
A clustered index is a type of index in a relational database that defines the physical order of data rows in a table based on the values of the indexed columns. In other words, the rows of data in the table are physically stored on disk in the same order as the index key values. Each table can have only one clustered index because it determines the actual order of data storage.
Creating Clustered Index
To create a clustered index, you specify the columns on which you want to create the index. The database management system then rearranges the rows of the table to match the order of the index key values. This process can be resource-intensive, especially if the table contains a large amount of data, as the data needs to be physically reorganized on disk.
Let's say we have a table named Orders with the following structure:
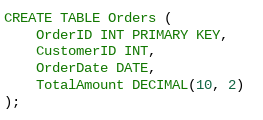
To create a clustered index on the OrderID column, we use:
CREATE CLUSTERED INDEX IX_Orders_OrderID ON Orders(OrderID);
In this example, the IX_Orders_OrderID clustered index is created on the OrderID column. The data in the Orders table will be physically sorted based on the values of the OrderID column.
Non-clustered Index
A non-clustered index is another type of index that creates a separate data structure containing a sorted list of index key values and pointers to the corresponding data rows in the table. Unlike a clustered index, a non-clustered index does not affect the physical order of data on disk; it's a separate structure that provides a way to quickly locate data based on the indexed columns.
Creating Non-Clustered Index
To create a non-clustered index, you also specify the columns on which you want to create the index. The database management system then creates a separate index structure containing the sorted key values and pointers to the actual data rows. This structure enables faster data retrieval based on the indexed columns.
Let's continue with the same Orders table and create a non-clustered index on the CustomerID column:
CREATE NONCLUSTERED INDEX IX_Orders_CustomerID ON Orders(CustomerID);
In this case, the IX_Orders_CustomerID non-clustered index is created on the CustomerID column. Unlike a clustered index, a non-clustered index creates a separate structure that contains the indexed values and pointers to the actual data rows.
Here's another example of creating a composite non-clustered index on multiple columns:
CREATE NONCLUSTERED INDEX IX_Orders_Date_Amount ON Orders(OrderDate, TotalAmount);
In this example, the IX_Orders_Date_Amount non-clustered index is created on the OrderDate and TotalAmount columns. This index allows for efficient retrieval of data based on the combination of these two columns.
Characteristics of the Clustered Index
A clustered index, a vital tool in database management, fundamentally determines the physical ordering of data in a table. Let's delve deeper into its key characteristics:
- Uniqueness: The most distinguishing feature of a clustered index is its uniqueness. Each table can have only one clustered index. This is because the data rows in the table are physically rearranged to match the order of the clustered index, hence having more than one would cause confusion.
- Storage Pattern: In a table with a clustered index, data rows are stored based on the clustered index key. This means that the data is physically ordered and stored in the way the index defines, facilitating faster data retrieval.
- Index Key: By default, clustered indexes use the primary key of a table as the index. The primary key is a unique identifier for each record in the table, making it the perfect choice for a clustered index.
- Performance: Clustered indexes can significantly improve the performance of large-range queries. This is because the data is stored contiguously, enabling the database management system to quickly locate the range's starting point and then retrieve the rest of the data in that range efficiently.
- Inserts Impact: The order of data insertions can affect the performance of a clustered index. If records are inserted in a non-sequential order, it could lead to page splits, negatively impacting the query performance.
Characteristics of the Non-Clustered Index
A non-clustered index is an alternative type of index with features distinct from a clustered index. Here's a more comprehensive examination of these features:
- Uniqueness: A table can have multiple non-clustered indexes. This flexibility allows for more precise data retrieval based on different search criteria.
- Storage Pattern: A non-clustered index does not affect the physical ordering of data rows in a table. Instead, it creates a separate object within the table that points back to the data rows. This structure means that a non-clustered index can lead to more storage usage as it maintains its own set of pointers to the table's records.
- Index Key: The index key for a non-clustered index can be chosen independently from the primary key. This ability is useful when there are frequent search queries based on non-primary key columns.
- Performance: Non-clustered indexes can speed up performance for specific search queries. These indexes can quickly locate and retrieve data without needing to scan the entire table, reducing the query time.
- Inserts Impact: The impact of data insertion order is less in the case of non-clustered indexes. Since the physical order of the data does not change, page splits are not an issue, which makes inserts and updates quicker than in clustered indexes.
To make it more concise, let's put the information in a table:
Characteristic | Explanation |
Uniqueness | Allows multiple indexes per table |
Storage Pattern | Creates a separate object pointing to data rows |
Index Key | Chosen independently from the primary key |
Performance | Boosts performance for specific search queries |
Inserts Impact | Less performance impact from data insertions |
Difference between Clustered and Non-Clustered index in SQL
Clustered and non-clustered indexes in SQL offer different ways to organize and access data within a database. Both have their own advantages and usage scenarios. Here's a more thorough examination of key differences between clustered and non clustered index:
- Storage Order: Clustered indexes directly impact the physical storage order of data in a table, arranging the data rows in the table based on the index key. On the other hand, non-clustered indexes do not rearrange the physical data. Instead, they maintain a separate index table that points back to the rows in the main table.
- Number of Indexes per Table: Each table can only have a single clustered index because the data rows can only be sorted in one way. However, a table can support multiple non-clustered indexes. This feature provides more flexibility when handling various search queries.
- Performance: Clustered indexes can significantly improve performance for large-range queries because they can access the data rows directly. In contrast, non-clustered indexes are more effective for specific search queries, especially those targeting non-primary key columns. This is because non-clustered indexes can directly point to the relevant data rows without having to scan the entire table.
- Storage Usage: Non-clustered indexes generally require more storage space. This is because they maintain their own set of pointers to the table's records, effectively creating a separate object within the table. On the other hand, clustered indexes require less storage since they directly rearrange the physical data rows in the table.
- Index Key: By default, a clustered index uses the primary key of a table as its index key, ensuring uniqueness in the data rows. In contrast, non-clustered indexes allow developers to choose any column as an index key, including non-primary key columns. This provides greater flexibility but also introduces the risk of duplicate entries.
- Inserts and Updates: In a clustered index, the process of inserts and updates can be more time-consuming. This is because maintaining the data rows in a sorted order might require shifting existing rows. In contrast, inserts and updates in a non-clustered index are generally faster and less resource-intensive, as they only involve updating the separate index table.
When to Use a Clustered or Non-Clustered Index?
Knowing when to implement a clustered or non-clustered index involves considering several factors: the volume of data, the types of queries typically run, available storage space, and the uniqueness of data values. A clustered index is generally recommended for dealing with large datasets due to its superior performance in handling range queries.
However, if your work involves running specific search queries more often, a non-clustered index would provide faster results. If you are working with limited storage, a clustered index, due to its lower storage requirement, would be the better choice. Finally, the clustered index works most effectively when key values are unique, making it an ideal choice when data uniqueness is high.
Factor | Clustered Index | Non-Clustered Index |
Data Volume | Suitable for large datasets due to efficient range query performance | Not as efficient for large datasets |
Query Type | More efficient for range queries | Quicker results for specific search queries |
Storage Space | More efficient as it requires less storage space | Requires more storage space due to a separate object creation |
Data Uniqueness | Most effective when the key values are unique | Can work effectively even when key values are not unique |
Advantages of Clustered and Non-Clustered Index
Clustered and non-clustered indexes are powerful tools in managing and retrieving data within a database. Their unique characteristics contribute to the efficiency and performance of database operations.
Key advantages include:
- Speed: They enhance the speed of data retrieval by avoiding full table scans.
- Efficiency: They permit more efficient data retrieval, thereby saving computational resources.
- Performance Boost: Properly configured indexes can significantly enhance overall database performance.
- Scalability: They allow databases to handle larger data volumes more effectively, accommodating growing data needs.
Disadvantages of Clustered and Non-Clustered Index
Despite the considerable benefits, using clustered and non-clustered indexes also introduces certain complications that should be kept in mind:
- Complexity: They introduce added complexity to the database schema, increasing the learning curve for database management.
- Maintenance Overhead: Indexes require regular updates whenever data is inserted, deleted, or modified, creating additional overheads.
- Storage Requirements: Non-clustered indexes, in particular, require additional storage space as they create a separate object in the database, which may be a concern in systems with limited storage capacity.
Conclusion
In this tutorial, we have taken a deep dive into the world of clustered and non-clustered index, dissecting their unique characteristics, practical applications, and the crucial differences between them. Armed with this knowledge, you can make informed decisions about when and how to use these indexes for maximum performance and efficiency. Remember that upGrad offers many more resources for professionals seeking to upskill in SQL and other relevant areas.
FAQs
1. How does the difference between clustered and non-clustered index in SQL server affect performance?
The choice of index can significantly impact query performance. Clustered indexes are typically faster for range queries, while non-clustered indexes are more efficient for specific search queries. Can you give a clustered and non-clustered index example to illustrate their usage?
2. Can you give a clustered and non-clustered index example to illustrate their usage?
In a library database, a clustered index could be based on the Book ID (unique identifier), while a non-clustered index might be created on the Genre field to quicken genre-specific searches. What are the best scenarios for using clustered and non-clustered index in SQL server?
3. What are the best scenarios for using clustered and non-clustered index in SQL server?
A clustered index is best used when dealing with large volumes of data and range queries. In contrast, a non-clustered index is preferable for specific search queries and when the key values aren't unique. Could you clarify the difference between clustered and non-clustered index in terms of data retrieval?
4. Could you clarify the difference between clustered and non-clustered index in terms of data retrieval?
A clustered index defines the storage order of data in the table, making it faster for range queries. A non-clustered index, on the other hand, points back to the data rows, making it efficient for specific queries. What are some common misconceptions about the clustered and non-clustered index?
5. What are some common misconceptions about the clustered and non-clustered index?
A common misconception is that non-clustered indexes are always slower than clustered ones. While clustered indexes can be faster for range queries, non-clustered indexes can outperform them for specific search queries.











-d9bdeff6165f4eb1ba2adcebde78e961.svg)







-ae8d039bbd2a41318308f8d26b52ac8f.svg)
-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)

%20(2)-db0b6f38da9c485faf76e366793c9b9e.webp&w=128&q=75)













