Introduction
Learn the power of regular expressions (regex) for pattern matching and text manipulation. From basics to advanced techniques, this regex tutorial breaks it down with practical examples. Master regex for tasks like data validation, information retrieval, and text alteration in various real-world scenarios. Enhance your text-processing skills today.
Leverage the power of regular expressions (regex) to efficiently manipulate and extract data from text. Master intricate patterns and enhance your text-processing skills in various contexts with this informative regex tutorial. Dive into the world of pattern matching!
Regular Expression Characters
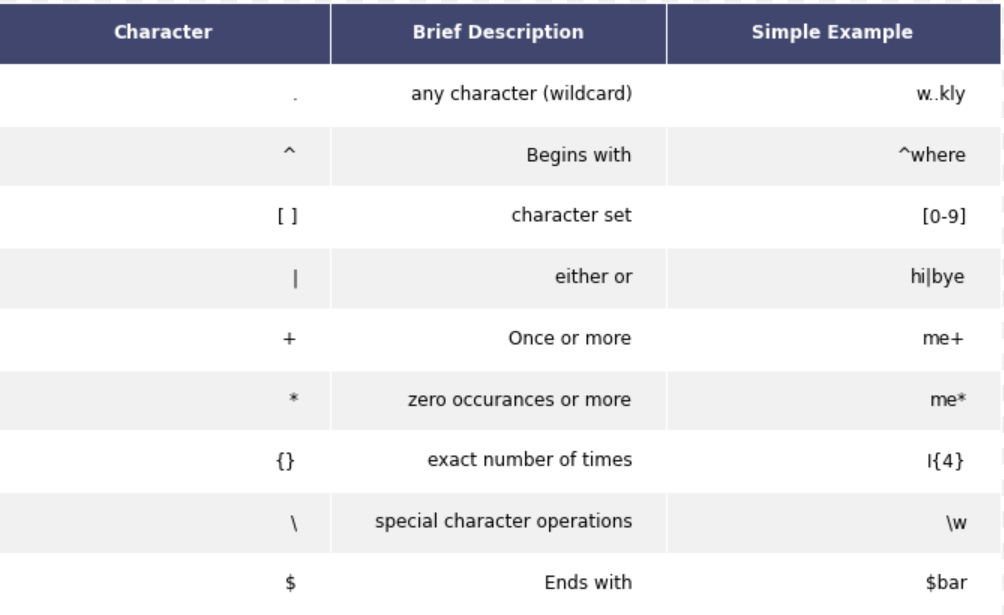
Explore regular expressions (regex) used to search and manipulate text strings. Learn common regex characters, usage, and optimization strategies with examples below.
1. Literal Characters:
- Brute Force: Matching exact characters.
Example: To match the word "hello", use the regex 'hello'.
2. Character Classes:
- Brute Force: Listing alternatives individually.
Example: To match vowels (a, e, i, o, u), use '[aeiou]'.
- Optimal: Using ranges within character classes.
Example: '[a-z]' matches any lowercase letter.
3. Metacharacters:
- Brute Force: Escaping metacharacters individually.
Example: To match a dot, use '\.'.
- Optimal: Using character classes to match metacharacters without escaping.
Example: '[.]' matches a dot.
4. Quantifiers:
- Brute Force: Repeating patterns explicitly.
Example: To match three digits, use '\d\d\d'.
- Optimal: Using quantifiers for repetition.
Example: To match three digits, use '\d{3}'.
5. Alternation:
- Brute Force: Listing alternatives separately.
Example: To match "apple" or "banana", use 'apple|banana'.
- Optimal: Using parentheses for grouping and alternation.
Example: '(apple|banana)'.
6. Anchors and Boundaries:
- Brute Force: Placing patterns at specific positions.
Example: To match "hello" at the start, use '^hello'.
- Optimal: Using word boundary '\b' to match entire words.
Example: '\bhello\b'.
7. Grouping and Capturing:
- Brute Force: Repeating capture groups.
Example: To match "abab", use '(ab)(ab)'.
- Optimal: Using backreferences to match repeated patterns.
Example: '(ab)\1' matches repeated "ab".
8. Lookaround Assertions:
- Brute Force: Matching with context and redundant captures.
Example: To match "apple" not followed by "pie", use 'apple(?! pie)'.
- Optimal: Using non-capturing groups and lookaheads.
Example: 'apple(?=.*pie)'.
9. Escape Sequences:
- Brute Force: Escaping special characters manually.
Example: To match a tab character, use '\t'.
- Optimal: Using predefined escape sequences.
Example: To match a tab, use '\t'.
Optimize regex with quantifiers, character classes, and efficient groupings to enhance performance while maintaining readability.

Metacharacters are special characters in regular expressions that carry a specific meaning. Here are some commonly used metacharacters, with examples:
1. Dot ( . )
- Meaning: Matches any single character except a newline.
- Example: The regex 'c.t' matches "cat", "cut", "cot" but not "cart" (due to the extra character).
2. Caret ( ^ )
- Meaning: Matches the start of a line or string.
- Example: The regex '^start' matches "start" at the beginning of a line.
3. Dollar Sign ( $ )
- Meaning: Matches the end of a line or string.
- Example: The regex 'end$' matches "end" at the end of a line.
4. Asterisk ( * )
- Meaning: Matches zero or more occurrences of the preceding element.
- Example: The regex 'ab*c' matches "ac", "abc", "abbc", "abbbc", and so on.
5. Plus ( + )
- Meaning: Matches one or more occurrences of the preceding element.
- Example: The regex 'go+l' matches "gol", "gool", "gooool", and so on.
6. Question Mark ( ? )
- Meaning: Matches zero or one occurrence of the preceding element.
- Example: The regex 'colou?r' matches both "color" and "colour".
7. Pipe ( | )
- Meaning: It acts like an OR operator, matching either the expression on its left or right.
- Example: The regex 'apple|banana' matches "apple" or "banana".
8. Parentheses ( ( ) )
- Meaning: Groups elements together and captures them for later use.
- Example: The regex '(ab)+' matches "ab" one or more times.
9. Square Brackets ( [ ] )
- Meaning: It defines a character class and matches any one of the characters within the brackets.
- Example: The regex '[aeiou]' matches any vowel.
10. Backslash ( \ )
- Meaning: Escapes the character that follows to be treated as a literal character.
- Example: The regex '\$10' matches "$10".
11. Curly Braces ( { } )
- Meaning: Specifies the number of repetitions of the preceding element.
- Example: The regex 'a{2,4}' matches "aa", "aaa", or "aaaa".
12. Escape Sequences ( \d, \w, \s )
- Meaning: Represents predefined character classes like digits, word characters, and whitespace.
- Example: The regex '\d{3}' matches any three digits.
Metacharacters add flexibility and power to regex patterns, allowing you to create sophisticated search and manipulation patterns. However, they also require careful understanding and usage to achieve the desired results.
Quantifiers
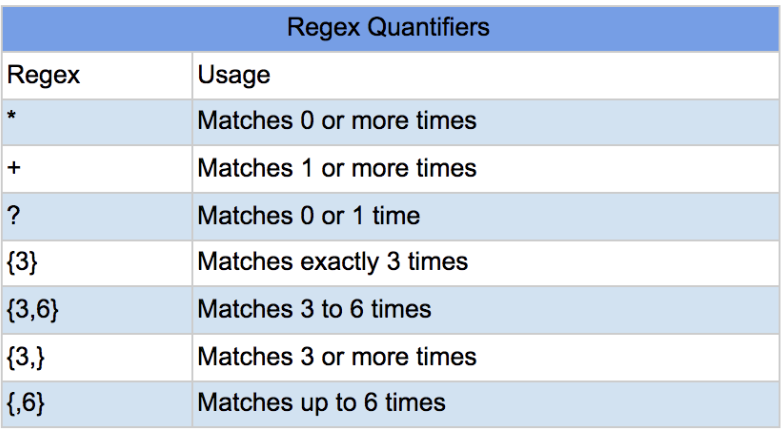
Quantifiers in regex specify element repetition, enhancing pattern flexibility and power.
Here are some common quantifiers, along with examples:
1. '*' (Asterisk): This quantifier indicates that the preceding element can appear zero or more times.
Example: The pattern ab*c would match strings like "ac", "abc", "abbc", "abbbc", and so on.
2. '+' (Plus): This quantifier indicates that the preceding element must appear at least once.
Example: The pattern a+b would match strings like "ab", "aab", "aaab", and so on, but not "b" or "ac".
3. '?' (Question Mark): This quantifier indicates that the preceding element can appear zero or one time, making it optional.
Example: The pattern ‘colou?r’ would match both "color" and "colour".
4. '{n}': This quantifier specifies an exact number of occurrences for the preceding element.
Example: The pattern a{3} would match "aaa" but not "aa" or "aaaa".
5. '{n,}': This quantifier indicates that the preceding element must appear at least n times.
Example: The pattern a{2,} would match "aa", "aaa", "aaaa", and so on.
6. '{n,m}': This quantifier specifies a range of occurrences for the preceding element, from n to m times.
Example: The pattern a{2,4} would match "aa", "aaa", and "aaaa", but not "a" or "aaaaa".
Here are a few more examples to illustrate the use of quantifiers in regular expressions:
- 'd{3,5}': Matches sequences of digits with a length between 3 and 5, like "123", "4567", and "89012".
- '[A-Za-z]+': Matches one or more consecutive uppercase or lowercase letters.
- '\d*\.?\d+': Matches decimal numbers, like "0.25", ".75", "100", and "3.14159".
- '[aeiou]{2,3}': Matches sequences of 2 to 3 consecutive vowels, like "ae", "iou", and "aae".
Quantifiers boost regex expressiveness and efficiency but avoid overuse to prevent unintended outcomes and performance problems.
Groups and Ranges
Groups:
Regex groups treat character sequences as single units for quantifiers and operations like alternations. It involves:
1. Basic Grouping: Using parentheses '(' and ')', you can group characters.
Example: Pattern '(ab)+' matches "ab", "abab", "ababab", and so on.
2. Grouping for Alternation: You can use groups to define alternatives using the '|' symbol.
Example: Pattern '(cat|dog)' matches either "cat" or "dog".
3. Capturing Groups: When you use parentheses to create a group, it also captures the matched text so you can reference it later.
Example: Pattern '(a|b)(\d+)' matches "a123", capturing "a" in Group 1 and "123" in Group 2.
4. Non-Capturing Groups: Sometimes you want to use groups for operations but don't need to capture the result. Use '(?: ... )' to create non-capturing groups.
Example: Pattern '(?:https?|ftp)://' matches URLs like "http://", "https://", "ftp://".
Character Ranges:
Character ranges allow you to define a set of characters that can match a certain position in the input text.
1. Basic Character Range: You can define a range of characters using a hyphen '-' within square brackets [ ].
Example: The pattern '[a-e]' matches any lowercase letter from "a" to "e".
2. Negated Character Range: By placing a caret '^' at the beginning of a character range, you can match any character not in the range.
Example: Pattern '[^0-9]' matches any non-digit character.
3. Character Range with Quantifiers: Combine character ranges with quantifiers to match multiple characters in a range.
Example: Pattern '[0-9]+' matches one or more digits.
4. Combining Ranges: You can combine multiple character ranges and individual characters within the same set.
Example: Pattern '[A-Za-z0-9]' matches any alphanumeric character.
5. Escaping Characters: Some characters like '[' , ']' , '(' , and ')' have special meanings. To match them literally, escape them with a backslash \.
Example: Pattern '[\(\)\[\]\{\}]' matches any of these: "(", ")", "[", "]", "{", "}".
6. Shorthand Character Classes: Regular expressions offer shorthand codes for common character ranges.
- '\d' matches any digit (same as '[0-9]').
- '\w' matches any word character (alphanumeric plus underscore, equivalent to '[A-Za-z0-9_]').
- '\s' matches any whitespace character (spaces, tabs, line breaks).
Groups and character ranges enhance regex precision and efficiency, enabling accurate text data extraction.
Regular Expression in Different Languages
Python:
In regex python, regular expressions are available through the built-in 're' module. Regular expressions are patterns that allow you to match and manipulate text strings based on specific rules.
import re
# Search for a pattern in a string
pattern = r'\b\w+'
text = "Hello, this is a sample text."
matches = re.findall (pattern, text)
print(matches) # Output: ['Hello', 'this', 'is', 'a', 'sample', 'text']
#Replace using regular expression
new_text = re.sub(r'\b\w+', 'word', text)
print(new_text) # Output: "word, word word word word word word."
- 're.findall()': Finds all occurrences of the pattern in the text.
're.sub()': Replaces occurrences of the pattern with a specified string.
JavaScript:
Regex JavaScript has built-in support for regular expressions using the 'RegExp' object. Regular expressions are patterns enclosed in slashes.
const text = "Regex is awesome!";
const pattern = /\b\w+/g;
const matches = text.match(pattern);
console.log(matches);
const new_text = text.replace(/\b\w+/, 'Regular Expression');
console.log(new_text);
Java:
Java provides regular expression functionality through the 'java.util.regex' package. Regular expressions are patterns compiled into 'Pattern' objects.
import java.util.regex.*;
String text = "Regular expressions are powerful.";
String pattern = "\\b\\w+";
Pattern p = Pattern.compile(pattern);
Matcher m = p.matcher(text);
while (m.find()) {
System.out.println(m.group());
"are", "powerful"
}
String new_text = m.replaceAll("Regex");
System.out.println(new_text);
Ruby:
Ruby incorporates regular expressions directly into its syntax. Patterns are often used with string methods.
text = "Regular expressions are versatile."
pattern = /\b\w+/
# Find all matches in the str matches text.scan(pattern)
puts matches # Output: ["Regular", "expressions", "are", "versatile"]
# Replace using regular expression
new_text = text.gsub(/\b\w+/, 'Regex')
puts new text # Output: "Regex expressions Regex Regex."
PHP:
PHP provides regular expression support through functions like 'preg_match()' and 'preg_replace()'. Patterns are enclosed in delimiters.
Stext = "Matching patterns in PHP.".
Spattern = /\b\w+/';
preg_match_all($pattern, $text,matches); print_r($matches[0]);
$new_text = preg_replace($pattern, 'Regex', $text); echo $new text;
Conclusion
By the end of this regex tutorial, it must be clear to you that regular expressions are a versatile toolkit for pattern matching and text manipulation across various programming languages. Understanding their core components, like metacharacters and quantifiers, simplifies complex string operations. These tools empower you to locate, extract, and modify text patterns, enhancing programming efficiency and accuracy. Mastery of regular expressions is invaluable in a text-rich world, regardless of the programming language or industry.
FAQs
1. What is a regular expression?
A regular expression is a sequence of characters defining a pattern used for matching and manipulating text.
2. How can I match any character using regex?
The dot (.) metacharacter matches any character except a newline.3. Which programming languages support regular expressions?A. Common programming languages like Python, Java, and JavaScript support regular expressions.
3. What's the purpose of the regex cheat sheet?
The regex cheat sheet provides a quick reference for metacharacters used in regular expressions. These characters help you define patterns for finding, validating, and manipulating text efficiently in programming.
4. What is a regex generator?
A. A regex generator is a tool that automatically generates regular expressions based on user-provided examples or criteria. It helps simplify the process of creating complex regex patterns for tasks like data validation and extraction.












-d9bdeff6165f4eb1ba2adcebde78e961.svg)






-ae8d039bbd2a41318308f8d26b52ac8f.svg)
-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)

%20(2)-db0b6f38da9c485faf76e366793c9b9e.webp&w=128&q=75)













