Introduction
In Python, reading CSV files is a fundamental task for data processing and analysis. This tutorial offers an introduction and overview of the essential skill of how to read a CSV file in Python.
Overview
Reading CSV (Comma-Separated Values) files is fundamental for handling structured data. This process involves importing external data stored in CSV format and converting it into a usable data structure within Python. Python provides efficient methods to accomplish this task by leveraging libraries like pandas.
What Is a CSV File?
A CSV file, which stands for "Comma-Separated Values," is a specific file format consisting of tabular data. It serves as a medium for exporting data from various spreadsheet programs like Microsoft Excel, Apple Numbers, or Google Sheets, and is also capable of being imported back into them.
Differing from other spreadsheet file formats, CSVs are characterized by their single-sheet structure. In these files, data elements are primarily separated by commas, although other delimiters like tabs, semicolons, pipes, or carets can be utilized.
CSV files possess universal readability, making them compatible with a wide range of software applications. The delimiter, mostly a comma, acts as the separator between individual values within each row. The first row serves as the header, containing labels or identifiers for each column.
Subsequent rows in a CSV file represent the actual data for each respective column. While some CSV documents lack headers, others contain each data element within double quotation marks.
Why Is It Used in Pandas?
Pandas uses .csv files because of the following benefits:
Simplicity and readability: CSV files are plain-text files with rows and columns separated by commas, making them human-readable and straightforward to work with programmatically.
Widespread data storage: Countless datasets are shared online or exported from various applications in CSV format. This ubiquity positions CSV as a go-to choice for data import and export tasks.
Data structure compatibility: CSV's tabular format aligns seamlessly with pandas' DataFrames. Each CSV row corresponds to a DataFrame row, and each comma-separated value maps to a DataFrame cell. This inbuilt alignment simplifies the loading of CSV data into pandas.
Ease of sharing: CSV files are portable, platform-agnostic, and universally compatible. Since they are text-based and free from proprietary formats, they can be shared and processed across various data processing tools and platforms.
Lightweight: CSV files are light in terms of both file size and storage requirements. They lack complex formatting or metadata, making them efficient for data storage and transmission.
Flexibility: CSVs support various data types, including numeric, textual, and date/time values. Pandas are adept at automatically detecting and handling these diverse data types when reading CSV files.
Ease of use: Python's pandas' library provides the read_csv() function, a user-friendly tool for effortlessly importing CSV files into DataFrames. This function offers numerous customization options to accommodate various CSV file structures, such as varying delimiters or handling missing data gracefully.
Data transformation and analysis: After importing CSV data into a pandas DataFrame, many dominant utilities come into play, enabling effortless data refinement, exploration, and visualization, including tasks like data cleansing, filtering, aggregation, and visual representation.
Compatibility with various libraries: Pandas harmoniously meshes with vital Python data science and machine learning libraries such as NumPy, Matplotlib, and scikit-learn, fostering a harmonious ecosystem for tasks encompassing data preparation and exploratory analysis in the realm of data science projects.
Reading a CSV File using csv.reader()
The csv.reader() function in Python's csv module allows you to read and process CSV files.
import csv
# Open the CSV file for reading
with open('data.csv', 'r') as file:
csv_reader = csv.reader(file)
# Iterate through each row in the CSV file
for row in csv_reader:
print(row)
Explanation:
We open the CSV file named 'data.csv' in read mode using a context manager (with statement). csv.reader() is used to create a reader object for the CSV file. We iterate through the reader object, and each row represents a list of values from a CSV row.
Reading a CSV into a Dictionary
You can use the csv.DictReader() function to read a CSV file into a dictionary.
import csv
# Open the CSV file for reading
with open('data.csv', 'r') as file:
csv_reader = csv.DictReader(file)
# Iterate through each row in the CSV file
for row in csv_reader:
print(row)
Explanation:
csv.DictReader() is used to create a reader object that interprets the first row as column headers and maps each row to a dictionary with column names as keys.
Reading CSV Files with Pandas
Pandas is a powerful library for working with tabular data, including CSV files. Here's how to read a CSV file using Pandas:
import pandas as pd
# Read the CSV file into a DataFrame
df = pd.read_csv('data.csv')
# Print the first few rows of the DataFrame
print(df.head())
Explanation:
We use pd.read_csv() to read the CSV file into a Pandas DataFrame. df.head() is used to print the first few rows of the DataFrame.
Python's csv module provides functions like csv.reader() and csv.DictReader() for reading CSV files as discussed earlier. It also includes functions for writing CSV files like csv.writer() and csv.DictWriter(). Pandas' read_csv() function is a versatile tool for reading CSV files into DataFrames. You can customize it with various parameters to handle different file formats and configurations.
Writing Data into a Pandas DataFrame
import pandas as pd
# Sample data as a list of dictionaries
data = [
{"Name": "Alice", "Age": 30, "City": "New York"},
{"Name": "Bob", "Age": 25, "City": "Los Angeles"},
{"Name": "Charlie", "Age": 35, "City": "Chicago"},
]
# Create a DataFrame from the data
df = pd.DataFrame(data)
# Display the DataFrame
print(df)
Explanation:
We import the pandas library as pd. We define a list of dictionaries called data, where each dictionary represents a row of data. Using pd.DataFrame(data), we create a Pandas DataFrame from the data list. Finally, we print the DataFrame, which displays the data in tabular format.
Write Using csv.writer()
The csv.writer() class in Python's csv module is used to write data to a CSV file. You can write data row by row using this writer.
import csv
# Sample data
data = [
["Name", "Age", "City"],
["Alice", 30, "New York"],
["Bob", 25, "Los Angeles"],
["Charlie", 35, "Chicago"]
]
# Open a CSV file for writing
with open("output.csv", "w", newline="") as file:
csv_writer = csv.writer(file)
# Write data row by row
for row in data:
csv_writer.writerow(row)
print("CSV file 'output.csv' created successfully.")
Result:
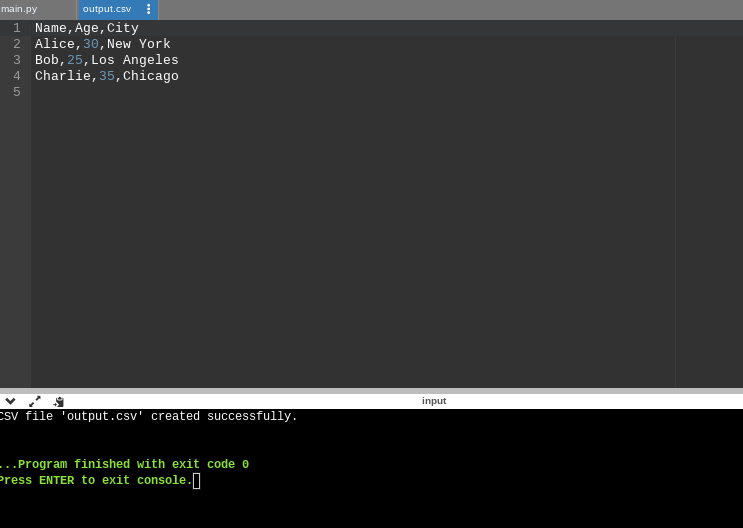
Write Using csv.DictWriter()
The csv.DictWriter() class is used when you have data in the form of dictionaries, where keys represent column headers.
import csv
# Sample data as a list of dictionaries
data = [
{"Name": "Alice", "Age": 30, "City": "New York"},
{"Name": "Bob", "Age": 25, "City": "Los Angeles"},
{"Name": "Charlie", "Age": 35, "City": "Chicago"}
]
# Define the CSV file's column headers
fieldnames = ["Name", "Age", "City"]
# Open a CSV file for writing
with open("output_dict.csv", "w", newline="") as file:
csv_writer = csv.DictWriter(file, fieldnames=fieldnames)
# Write the header row
csv_writer.writeheader()
# Write data row by row
for row in data:
csv_writer.writerow(row)
print("CSV file 'output_dict.csv' created successfully.")
Result:
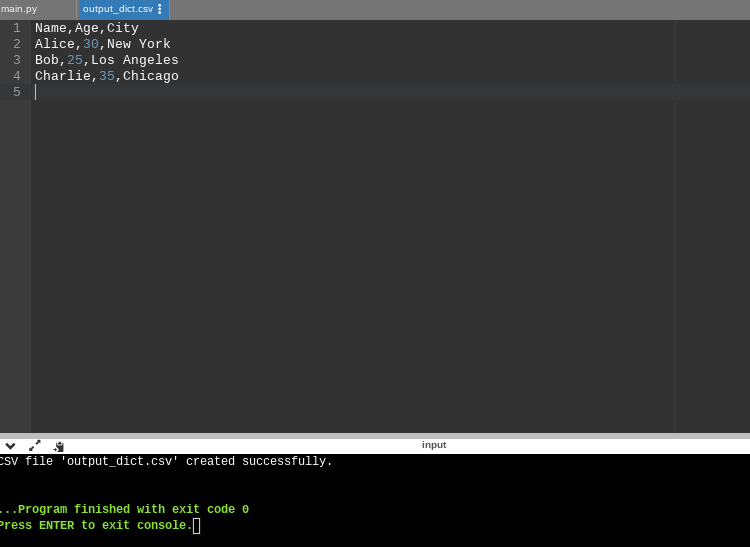
How to Print a DataFrame Without Using the to_string() Method
By default, Pandas prints DataFrames as tables, and you can simply use the print(df) statement to print the DataFrame without using to_string().
import pandas as pd
# Sample data as a list of dictionaries
data = [
{"Name": "Alice", "Age": 30, "City": "New York"},
{"Name": "Bob", "Age": 25, "City": "Los Angeles"},
{"Name": "Charlie", "Age": 35, "City": "Chicago"},
]
# Create a DataFrame from the data
df = pd.DataFrame(data)
# Print the DataFrame without using to_string()
print(df)
How to Check the Number of Maximum Returned Rows
You can control the maximum number of rows displayed when printing a DataFrame by setting the pd.options.display.max_rows option. Here's how to check and set it:
import pandas as pd
# Sample data as a list of dictionaries
data = [{"Name": f"Person {i}", "Age": i} for i in range(1, 21)]
# Create a DataFrame from the data
df = pd.DataFrame(data)
# Check the current maximum rows setting
current_max_rows = pd.options.display.max_rows
print(f"Current maximum rows setting: {current_max_rows}")
# Set the maximum rows to display (e.g., 10 rows)
pd.options.display.max_rows = 10
# Print the DataFrame (only 10 rows will be displayed)
print(df)
# Reset the maximum rows to the original setting
pd.options.display.max_rows = current_max_rows
We first check the current maximum rows setting using pd.options.display.max_rows. Then, we set the maximum rows to display to 10 using pd.options.display.max_rows = 10. When we print the DataFrame, only 10 rows are displayed. Finally, we reset the maximum rows to the original setting to avoid affecting future DataFrame printing.
Conclusion
CSV files are the backbone of structured data handling in Python, and using libraries like pandas, Python simplifies the process. Reading CSVs is vital for data work, and whether you're using Spyder or Visual Studio Code, Python's flexibility and simplicity make it a go-to tool for data professionals. By using CSV's readability and pandas' power, Python excels at importing, manipulating, and analyzing tabular data, making it a cornerstone in the world of data science.
FAQs
1. How to read a CSV file in Python Spyder?
To read a CSV file in Python with Sypder you need to import the Pandas library and then read the file using pd.read_csv(‘data.csv’).
2. How to use Python to extract specific data from a CSV file?
Python and the pandas' library enable data extraction from CSV files through file ingestion into a DataFrame, followed by the implementation of tailored filtering criteria on this DataFrame.
3. How to read a CSV file in Python VS code?
To open a CSV file in Python inside VS Code, start with importing the 'pandas' library, then use 'pd.Read_csv()' to get access to the CSV content, and finally, execute your script to engage with the data.
Take our Free Quiz on Python
Answer quick questions and assess your Python knowledge












-d9bdeff6165f4eb1ba2adcebde78e961.svg)







-ae8d039bbd2a41318308f8d26b52ac8f.svg)
-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)

%20(2)-db0b6f38da9c485faf76e366793c9b9e.webp&w=128&q=75)








-9cd0a42cab014b9e8d6d4c4ba3f27ab1.webp&w=3840&q=75)





