All courses
Agentic AI
Agentic AI
Artificial Intelligence
Degree / Exec. PG

IIIT Bangalore
Executive Diploma in Machine Learning and AI
OPJ Global University
Master’s Degree in Artificial Intelligence and Data Science
Liverpool John Moores University
Master of Science in Machine Learning & AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIExecutive Certificate

IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
IIIT Bangalore
Executive Programme in Generative AI for Leaders
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceOffline Bootcamps

upGrad
Data Science and AI-MLDoctorate
For All Domains
IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
Swiss School of Business and Management
Global Doctor of Business Administration from SSBM
Edgewood University
Doctorate in Business Administration by Edgewood UniversityGolden Gate University
Doctor of Business Administration From Golden Gate University
Rushford Business School
Doctor of Business Administration from Rushford Business School, SwitzerlandGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)-d9bdeff6165f4eb1ba2adcebde78e961.svg)
University of Waterloo
Chief Technology and AI Officer ProgramLeadership / AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIMachine Learning
Machine Learning
Data Science
Degree / Exec. PG
O.P Jindal Global University
Master’s Degree in Artificial Intelligence and Data ScienceIIIT Bangalore
Executive Diploma in Data Science & AILiverpool John Moores University
Master of Science in Data ScienceExecutive Certificate
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceupGrad | Microsoft
Gen AI Mastery Certificate for Content CreationOffline Bootcamps
upGrad
Data Science and AI-MLupGrad
Data AnalyticsMBA
Masters

Paris School of Business
Master of Science in Business Management and TechnologyO.P.Jindal Global University
MBA (with Career Acceleration Program by upGrad)Edgewood University
MBA from Edgewood UniversityO.P.Jindal Global University
MBA from O.P.Jindal Global UniversityGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)Executive Certificate

IMT, Ghaziabad
Advanced General Management ProgramMarketing
Executive Certificate
Offline Bootcamps
upGrad
Digital MarketingManagement
Degree
O.P Jindal Global University
MSc in International Accounting & Finance (ACCA integrated)Paris School of Business
Master of Science in Business Management and Technology
Golden Gate University
Master of Arts in Industrial-Organizational PsychologyExecutive Certificate

IIM Kozhikode
Human Resource Analytics Course from IIM-KupGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftEducation
Education

Northeastern University
Master of Education (M.Ed.) from Northeastern UniversityEdgewood University
Doctor of Education (Ed.D.)Edgewood University
Master of Education (M.Ed.) from Edgewood UniversityCertifications
Project Management
Certification

Knowledgehut
Leadership And Communications In ProjectsKnowledgehut
Microsoft Project 2007/2010-ae8d039bbd2a41318308f8d26b52ac8f.svg)
Knowledgehut
Financial Management For Project ManagersKnowledgehut
Fundamentals of Earned Value Management (EVM)Knowledgehut
Fundamentals of Portfolio ManagementKnowledgehut
Fundamentals of Program Management-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
Knowledgehut
CAPM® CertificationsKnowledgehut
Microsoft® Project 2016Certifications & Trainings
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)
Knowledgehut
PMP® CertificationKnowledgehut
PMI-RMP® CertificationKnowledgehut
PMP Renewal Learning PathKnowledgehut
Oracle Primavera P6 V18.8Knowledgehut
Microsoft® Project 2013Knowledgehut
PfMP® Certification CourseKnowledgehut
Project Planning and MonitoringPrince2 Certifications

Knowledgehut
PRINCE2® FoundationKnowledgehut
PRINCE2® PractitionerKnowledgehut
PRINCE2 Agile Foundation and PractitionerKnowledgehut
PRINCE2 Agile® Foundation CertificationKnowledgehut
PRINCE2 Agile® Practitioner CertificationManagement Certifications
Knowledgehut
Project Management Masters Certification ProgramKnowledgehut
Change ManagementKnowledgehut
Project Management TechniquesKnowledgehut
Product Management Certification ProgramKnowledgehut
Project Risk Management- Study abroad
- Offline centres
- uGSOT - B.Tech
More



49. Variance in ML
Learning Models in Machine Learning: 16 Key Types and How They Are Used
Did you know? In 2012, AlexNet blew the competition away by slashing the ImageNet error rate by over 10%! This game-changing breakthrough showcased the power of deep neural networks and sparked the rise of CNNs—now the backbone of technologies like computer vision, speech recognition, and NLP.
In machine learning, learning models are algorithms designed to identify complex patterns, make data-driven predictions, and perform specialised tasks. Different models are suited to various problems—some excel at classification, while others are better for regression, clustering, or reinforcement learning.
These models vary by the underlying algorithm and their learning strategy, such as supervised or unsupervised learning.
In this blog, we will explore 16 key learning models in machine learning, dive into representative algorithms for each, and discuss their practical applications in real-world scenarios.
If you want to strengthen your machine learning skills, upGrad's AI and ML courses let you specialise in data science and AI. With these online programs, you'll learn from experts, gain practical experience, and take your career to the next level.
What Are Learning Models in Machine Learning? 16 Types of Models
Machine learning models are computational or mathematical systems that learn patterns from data and make predictions or decisions based on those patterns.
These models analyze data and adapt based on the information they process, helping to automate decision-making processes. The choice of model depends on the type of task, such as classification, regression, or clustering.
A learning model consists of algorithms that take input data, process it through various transformations, and output predictions or classifications.
The model is trained using a dataset, adjusting parameters and continuously improving performance through repeated iterations. These can be categorised into different types of models in machine learning based on the learning process and the task they are designed to solve.
If you're ready to enhance your skills and dive into advanced AI and ML techniques, here are some top-rated courses to help you get started:
- Master's in Artificial Intelligence and Machine Learning
- Executive Diploma in Machine Learning and AI
- Executive Post Graduate Certificate Programme in Data Science & AI
Now, let’s move on to the heart of the discussion and explore the different varieties of learning models.
Types of Learning Models in Machine Learning
Learning models in machine learning are generally classified into these three main types: supervised, unsupervised, and reinforcement learning. Each type uses different algorithms and has distinct real-world applications. Below, we'll look at each type, with examples and practical uses.
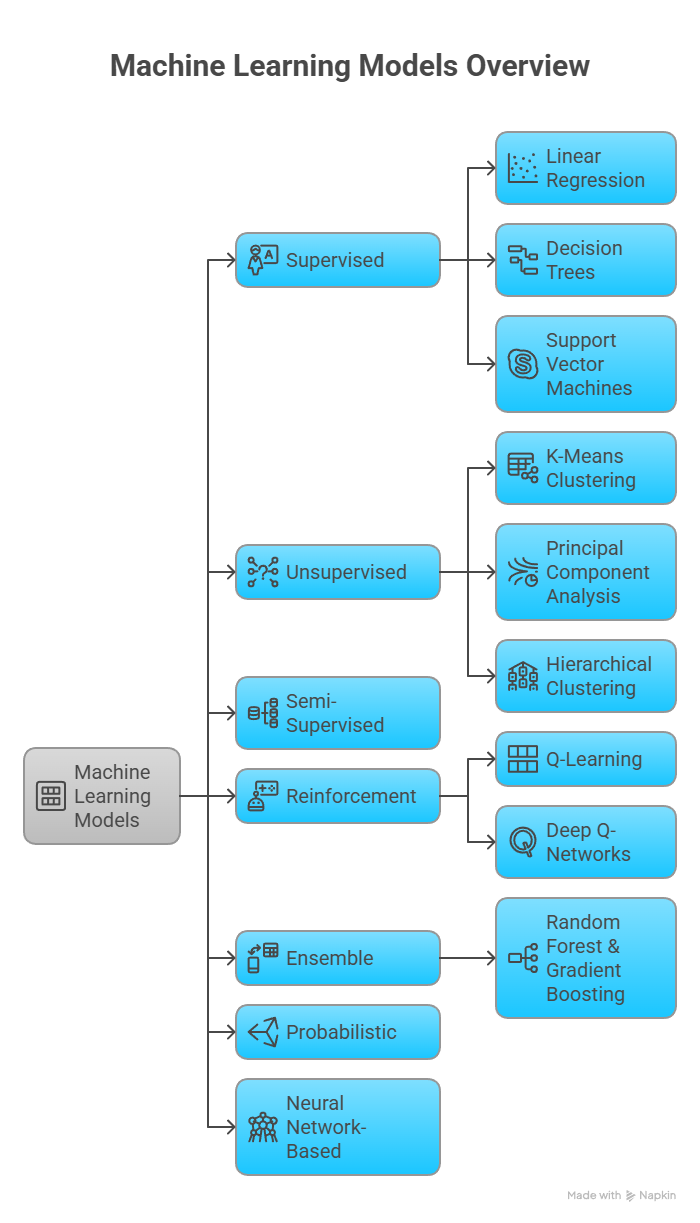
1. Supervised Learning Models
Supervised learning involves training a model on labeled data, where both the input and the desired output are provided. The model learns from this data to make predictions or classifications, adapting based on the feedback from the labeled examples.
- Linear Regression: Linear regression predicts continuous values by identifying the linear relationship between independent (predictor) and dependent (target) variables. This model is particularly effective when the data points exhibit a linear trend. Here's an example of linear regression:
Example: Predicting house prices is a common use case. For example, using data like house size, location, and number of rooms, a model learns how these features relate to price. It may predict that larger homes in certain areas tend to be more expensive. A dataset of 10,000 listings helps train the model to predict future prices or investments.
If you want to learn more about linear regression, try upGrad's free Linear Regression - Step by Step Guide. It will help you build a strong foundation in predictive modelling, and you will learn simple and multiple regression, performance metrics, and applications across data science domains.
- Decision Trees: A decision tree divides data into subsets based on binary decisions at each node, making them effective for both classification and regression tasks. The tree splits data using the most significant feature at each level.
- Example: In marketing, decision trees predict if a customer will purchase a product by first splitting data based on demographics like income, then predicting purchase likelihood. This method is common for customer segmentation in retail or e-commerce.
- Support Vector Machines (SVMs): SVMs are used to find the optimal hyperplane that separates data points of different classes, and are effective in high-dimensional spaces. SVMs can handle both classification and regression tasks, making them versatile models in supervised learning.
- Example: In handwritten digit recognition, SVMs distinguish digits (0-9) by finding a hyperplane that separates pixel data for each digit. SVMs also work for regression tasks, predicting continuous values by finding the best-fitting hyperplane.
Also read: 6 Types of Supervised Learning You Must Know About in 2025
2. Unsupervised Learning Models
Unsupervised learning models in machine learning work with data that has no labels. These models attempt to uncover hidden patterns or structures in the data without explicit output labels, allowing the model to explore relationships, clusters, and trends independently.
- K-Means Clustering: K-Means is a clustering algorithm that groups similar data points into clusters based on feature similarity. The algorithm assigns each data point to one of the pre-defined clusters, iterating until the cluster centres (centroids) stabilise.
Example: In market segmentation, K-Means can group customers by buying behavior. Retailers can segment customers into categories like "frequent buyers" or "first-time buyers," helping tailor marketing strategies.
- Principal Component Analysis (PCA): PCA is a dimensionality reduction technique that transforms large datasets into smaller ones while retaining most of the variance (important information). It helps simplify complex data while preserving key features, making it easier to process and visualise.
Example: In image processing, PCA extracts key features from high-resolution images, such as edges and textures, making it easier for machine learning models to analyze.
Also Read: Top 29 Image Processing Projects in 2025 For All Levels + Source Code
- Hierarchical Clustering: It builds a tree of clusters by merging or splitting them based on similarity, offering insights into data relationships without predefined cluster numbers. Unlike K-Means, it provides a detailed structure of the data.
- Example: In genomics, hierarchical clustering groups genes by expression levels. By analyzing cancer samples with similar patterns, it helps identify potential biomarkers or genes linked to cancer pathways, offering flexible clustering for complex biological data
Also read: Supervised vs Unsupervised Learning: Key Differences
3. Semi-Supervised Learning Models
- Semi-supervised learning: This technique combines labeled and unlabeled data to improve model performance, reducing the need for extensive labeled datasets. By using labeled data to guide learning from unlabeled data, it enhances the model’s ability to generalize while saving time and costs.
Example: In image classification, with 1,000 labeled images and 100,000 unlabeled ones, a semi-supervised model can learn from the labeled set and apply those insights to the unlabeled images, expanding its understanding without additional labeling effort.
4. Reinforcement Learning Models
Reinforcement learning models in machine learning are trained through interaction with an environment, receiving rewards or penalties based on their actions. These models learn to maximize long-term rewards by exploring different actions and adjusting based on feedback.
- Q-Learning: Q-Learning is a model-free algorithm that helps agents learn how to act optimally by knowing the value of actions in different states. The agent updates its knowledge of the environment by interacting with it and receiving rewards or penalties for each action, allowing it to make better decisions over time.
Example: Q-Learning trains self-driving cars to navigate traffic by rewarding successful actions and penalizing mistakes. Over time, the car learns the best actions, like stopping at red lights or making safe turns, improving decision-making.
- Deep Q-Networks (DQN): DQN is an extension of Q-Learning that uses deep neural networks to approximate the Q-value function. This method allows reinforcement learning to handle high-dimensional input spaces (e.g., images or sensor data), making it more suitable for complex environments where traditional Q-learning would struggle.
Example: DQN trains agents to play Atari games by observing pixel data and using deep learning to approximate Q-values for actions. The agent refines its strategy through repeated play based on rewards, learning to play optimally.
If you're eager to master neural networks and AI models, upGrad's Fundamentals of Deep Learning and Neural Networks course is perfect. In just 28 hours, you'll learn key concepts like perceptrons, neuron functioning, and deep learning architecture. Plus, earn a signed, verifiable e-certificate from upGrad.
5. Ensemble Models
Ensemble models combine multiple base learners to enhance prediction accuracy, making them more robust and reliable. By aggregating predictions from various models, they reduce variance and bias, improving generalization on new data.
- Random Forest: This ensemble method uses multiple decision trees built on random data samples. Predictions are averaged across trees, reducing overfitting, increasing stability, and improving accuracy compared to a single tree.
Example: In customer churn prediction, Random Forest combines decision trees focused on behaviors like usage patterns, improving reliability, and reducing outlier influence.
Also read: Random Forest Algorithm: When to Use & How to Use? [With Pros & Cons]
- Gradient Boosting: This method builds trees sequentially, with each tree correcting the previous one’s errors, improving accuracy iteratively. It’s ideal for complex datasets that require fine-tuning.
Example: For predicting loan defaults, Gradient Boosting uses financial data to refine predictions iteratively. Each tree corrects the previous one, improving accuracy and helping financial institutions assess default risks more reliably.
- AdaBoost: AdaBoost is an ensemble method that combines multiple weak learners into a strong learner by adjusting the weight of each data point based on previous models' performance. This emphasizes harder-to-classify points, making it effective for noisy data and classification tasks.
Example: AdaBoost in face detection combines weak classifiers to identify faces, adjusting weights on misclassified images. This process improves accuracy, making it suitable for real-time applications like video surveillance.
Also Read: Ensemble Methods in Machine Learning: Types, Applications, and Best Practices
6. Probabilistic Models
Probabilistic models in machine learning predict event likelihoods by modeling data as probability distributions. These learning models in machine learning estimate the probability of outcomes and are commonly used in classification and time-series analysis. Let’s look at two key types in this category:
- Naive Bayes: Naive Bayes is a simple probabilistic classifier that applies Bayes' theorem, assuming independence between features, to predict categories. It calculates the probability of each class given the input features and selects the class with the highest probability.
Example: In email classification, Naive Bayes determines if an email is spam by analyzing word frequencies (e.g., "free," "win," "offer") and calculating the probability of it being spam. While it assumes word independence, this approach works well for text classification tasks.
- Hidden Markov Models (HMMs): HMMs are used to model sequential data where the system has hidden states. These models are helpful for time-series analysis and capture the underlying sequence of events that drive observable data.
Example: HMMs model spoken words by assuming a hidden state (e.g., phoneme or word) that generates the speech signal at each moment. The system predicts the next word based on previous ones, enabling accurate language recognition. HMMs are especially effective for time-dependent data, like audio signals or video frames.
7. Neural Network-Based Models
Neural networks, inspired by the human brain, are used to model complex data patterns through layers of interconnected nodes.
These neural network-based models in machine learning have been instrumental in solving a wide range of problems, particularly those involving large datasets and intricate relationships.
Let’s explore three major types of models in machine learning that utilize neural networks:
- Feedforward Neural Networks (FNNs): FNNs are the simplest neural networks where data flows in a single direction, from input to output through hidden layers. They are useful for tasks like regression and classification, where the relationship between input and output is direct.
Example: FNNs can predict stock prices based on historical data, such as opening and closing prices, trading volume, and market indicators. After training, the model predicts future prices using learned patterns.
- Convolutional Neural Networks (CNNs): CNNs are designed for processing grid-like data, such as images, and use convolutional layers to learn spatial patterns. They excel at visual recognition tasks by detecting and combining local patterns to identify larger objects.
Example: CNNs are used in facial recognition. The model detects features like edges, eyes, and mouths across different layers to identify faces, regardless of angle or lighting.
- Recurrent Neural Networks (RNNs): RNNs handle sequential data, where the output depends on both current and previous inputs. They are ideal for tasks like time-series forecasting and natural language processing (NLP), as they maintain memory through feedback loops.
Example: RNNs are used in language translation, predicting words based on the context of previous words, improving as the model processes more data.
Also read: Understanding Recurrent Neural Networks: Applications and Examples
These learning models in machine learning are foundational, each excelling in different tasks. Selecting the right model is crucial for solving complex real-world problems effectively.
If you want to deepen your understanding of learning models in machine learning and their real-world applications, upGrad offers excellent programs like the Master’s in Artificial Intelligence and Machine Learning and the Executive Diploma in Machine Learning and AI with IIIT-B. These programs provide practical learning and equip you for high-demand AI and machine learning roles.
Now, each model performs differently, so it's important to evaluate them using the right metrics to determine which one best suits your specific task and data.
Comparing the Performance of Different Learning Models
When comparing the performance of various learning models in machine learning, it is essential to evaluate them using appropriate metrics to ensure they are learning effectively and making accurate predictions.
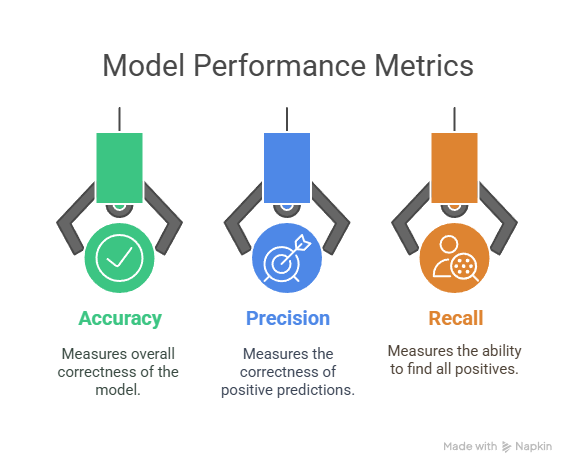
Different models may excel in other areas depending on the task, and choosing the right evaluation metrics can help determine which model is best suited for your problem.
- Accuracy, Precision, and Recall
Choosing the right performance metric is crucial for evaluating model effectiveness. Different metrics provide insights into other aspects of a model's prediction capability. Below is a more detailed look at three key metrics: accuracy, precision, and recall.
- Accuracy: Accuracy is the ratio of correct predictions to total predictions, indicating how often the model is right. However, it can be misleading in imbalanced datasets, where a model may achieve high accuracy by predicting the majority class but fail to identify the minority class.
Use Case: Accuracy works well in balanced datasets where false positives and false negatives have similar costs. For example, predicting customer churn in a balanced dataset can reliably use accuracy as a performance metric.
- Precision: Precision measures the correctness of optimistic predictions, calculating the ratio of true positives to the sum of true positives and false positives. It's essential when false positives have a high cost.
Use Case: Precision is crucial when false positives are costly, such as in medical diagnoses. High precision in cancer detection reduces unnecessary tests or treatments. The F1 Score is often used here to balance precision and recall, especially when there's a class imbalance.
- Recall: Recall calculates the ratio of true positives to the sum of true positives and false negatives, measuring how well the model identifies positive instances. It is vital when missing positive cases is especially harmful.
Use Case: Recall is crucial in fraud detection to ensure most fraudulent activities are caught, even if it leads to more false positives. It's also important in disease screening, where missed positives can have serious consequences. The F1 Score helps balance precision and recall in imbalanced datasets.
- Overfitting and Underfitting Risks
Model complexity plays a crucial role in a model's generalization ability, which refers to how well it performs on unseen data.
The balance between overfitting and underfitting is key to achieving a model that can effectively predict real-world scenarios. Both overfitting and underfitting are common risks during model training, each with its challenges.
Let’s take a look at it in the table below:
Concept | Description | Impact | Example |
Overfitting | The model learns noise and outliers from training data, not just patterns. | Performs well on training data but poorly on unseen data. | A decision tree with too many branches that overfits the training data. Cross-validation can help identify overfitting by evaluating the model on different data subsets during training. |
Underfitting | The model is too simple to capture data patterns, leading to poor performance. | Performs poorly on both training and test data due to insufficient complexity. | A linear regression model predicting housing prices based only on square footage, missing other influential factors. |
Also read: Regularization in Machine Learning: How to Avoid Overfitting?
- How Does Model Complexity Impact Generalization?
The complexity of a model—its number of parameters, layers (for deep learning models), or splits (for decision trees)—directly impacts its ability to generalize to unseen data.
Choosing the right model complexity is critical, as selecting a model with the appropriate balance helps prevent underfitting and overfitting. The goal is to ensure the model captures the most relevant patterns in the data without memorising irrelevant details or noise.
- Balancing Model Complexity
Simple learning models in machine learning, like linear regression, are preferred for tasks with linear relationships but can underfit complex data, missing important patterns. For example, predicting customer churn with limited features might lead to inaccurate predictions.
Complex models, such as deep neural networks or decision trees, can capture intricate patterns but may overfit if not regulated, memorizing noise rather than learning trends. Overfitting results in high training accuracy but poor performance on unseen data.
- Managing Model Complexity
- Cross-Validation: Cross-validation is a technique used to assess how well a model generalizes to unseen data by testing it on different subsets of the dataset. It provides a more accurate performance estimate, helping to detect overfitting and improve model reliability.
- Regularization: Regularization methods like L1 (Lasso) and L2 (Ridge) add penalty terms to the model's objective function, reducing the impact of large weights. This prevents overfitting by discouraging the model from relying too heavily on any single feature, ensuring it generalizes well without becoming too complex.
- Early Stopping: Early stopping is used in deep learning to prevent overfitting by monitoring model performance during training. If performance on the validation set starts to decline, training halts, preventing the model from learning noise after capturing the main data patterns.
Example Scenario: Customer Churn Prediction
In this scenario, you're predicting customer churn for a telecom company using two models: a decision tree and logistic regression.
Decision Tree Model
- Accuracy: 85% (high on training data but low on test data due to overfitting).
- Precision: 75% (high false positives).
- Recall: 95% (good at identifying churned customers but includes noise).
Problem: The decision tree overfits, performing well on the training data but failing to generalize to new data, resulting in poor predictions for unseen customers.
Also read: How to Perform Cross-Validation in Machine Learning?
Logistic Regression Model
- Accuracy: 80% (consistent across training and test data).
- Precision: 80% (balanced performance).
- Recall: 80% (misses some churners).
Problem: Logistic regression underfits, as it doesn’t capture all complex relationships. However, it generalizes better, maintaining consistent performance across both training and test sets.The decision tree model captures more churners but overfits, while logistic regression, though less accurate, offers better generalization. For deployment, logistic regression strikes a better balance between accuracy and complexity.
Boost your career with upGrad’s Executive Post Graduate Certificate in Data Science & AI. In 6 months, master Python, deep learning, and AI through real-world case studies and capstone projects. Offered by IIIT Bangalore, this course equips you with practical, job-ready skills. Plus, get 1 month of Microsoft Copilot Pro to enhance your learning.
Also Read: Top 5 Machine Learning Models Explained For Beginners
Now that you know the different types of ML models, let’s look at how you can choose the best one for your task.
Choosing the Right Learning Model for a Task: Considerations
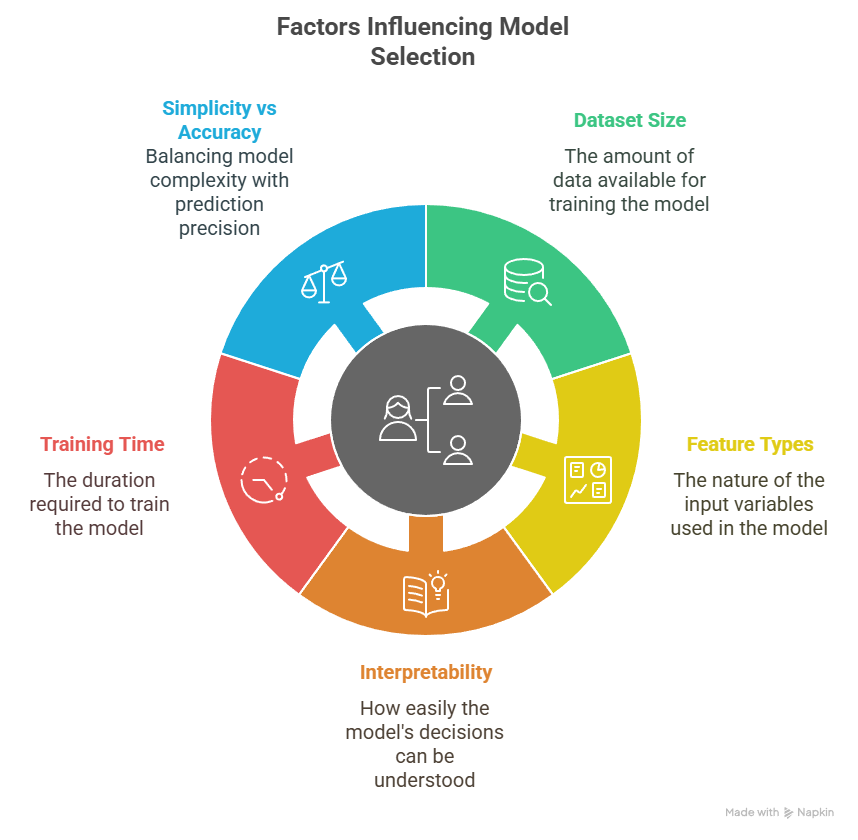
Selecting the right learning models in machine learning for a task is crucial in machine learning, as it directly impacts performance and efficiency. The model you choose will depend on several factors, including the nature of the data, the desired outcome, and computational constraints. Below, we outline key considerations that can guide your decision-making process.
- Factors Influencing Model Selection
Here are some crucial factors that you should consider when making your decision about which model is best suited for your data:
- Dataset Size: The size of your dataset influences model selection. Models like Decision Trees or Random Forests perform well with smaller datasets, while Neural Networks need larger datasets for optimal performance. For limited datasets, simpler models may be better.
- Feature Types: The type of features—continuous, categorical, or mixed—affects model choice. SVMs and Logistic Regression work best with numerical features, while Random Forests and K-Means handle mixed features well.
- Interpretability: Some tasks require easy-to-interpret models. Linear Regression or Decision Trees offer clear insights, which is crucial in fields like healthcare or finance, whereas complex models like Neural Networks prioritize accuracy over interpretability.
- Training Time: Available training time impacts model choice. Neural Networks deliver high accuracy but require significant computational resources, while simpler models like Logistic Regression or SVMs train faster and are effective for less complex tasks.
- Trade-Offs Between Simplicity and Accuracy
Choosing between simple and complex learning models in machine learning often involves balancing accuracy and model interpretability. Here's how different model complexities can influence decision-making:
- Simple Models: Models like Linear Regression, Logistic Regression, and Naive Bayes are fast, resource-efficient, and easy to interpret. They work well when speed and clarity matter, but may fall short on accuracy with complex data.
- Complex Models: Neural Networks, Deep Learning, and Ensemble methods excel at accuracy, especially with large, unstructured data like images or text. However, they require more time, computational power, and may lack interpretability, making them suited for high-performance tasks.
To level up your skills, consider upGrad's Job-Linked Data Science Advanced Bootcamp. With 11 live projects and mastery of 17+ industry tools, this program offers hands-on experience and certifications from Microsoft, NSDC, and Uber. Build a strong portfolio and stay ahead in the evolving field of AI and machine learning.
Also Read: Types of Machine Learning Algorithms with Use Cases Examples
Test Your Knowledge on Types of Models in Machine Learning
1. What does supervised learning require?
a) Labeled data
b) Unlabeled data
c) Both labeled and unlabeled data
d) None of the above
2. Which of the following is a regression algorithm?
a) K-Means
b) Linear Regression
c) Decision Trees
d) Naive Bayes
3. Which learning model is used for clustering?
a) Neural Networks
b) K-Means
c) Support Vector Machines
d) Gradient Boosting
4. Which model is most suitable for sequential data?
a) Convolutional Neural Networks
b) Feedforward Neural Networks
c) Recurrent Neural Networks
d) Logistic Regression
5. In reinforcement learning, what is the primary objective of an agent?
a) Maximize reward
b) Minimise data loss
c) Generalize across data
d) Optimise for computational power
6. Which of the following is a key characteristic of ensemble methods?
a) Single model prediction
b) Combining multiple models to improve accuracy
c) Using unstructured data
d) Non-interpretable models
7. What is the primary advantage of using Support Vector Machines (SVM)?
a) High interpretability
b) Handles large datasets with high dimensionality
c) Low computational cost
d) None of the above
8. Which of the following is an example of a probabilistic model?
a) Naive Bayes
b) Linear Regression
c) Convolutional Neural Networks
d) Random Forest
9. What type of data does Principal Component Analysis (PCA) deal with?
a) Categorical data
b) Structured numerical data
c) Time-series data
d) Image data
10. Which type of model would you use to predict customer churn based on various customer metrics?
a) Clustering model
b) Regression model
c) Reinforcement learning model
d) Probabilistic model
Also Read: The Ultimate Guide to Deep Learning Models in 2025: Types, Uses, and Beyond
Now that you've tested your knowledge on different types of models in machine learning, let's explore how upGrad can further enhance your understanding and skills in mastering machine learning techniques.
Master Learning Models in Machine Learning with upGrad!
Choosing the right learning models in machine learning can be challenging with so many options. Start by defining your problem: classification, regression, or clustering. Then, test models suited for your task, like decision trees for classification or linear regression for prediction.
Use performance metrics like accuracy, precision, recall, and F1 score to assess your models and adjust parameters for better results. Iterating based on real-world data will enhance your model's performance.
If you're finding it tough, upGrad can help. Whether you're a beginner or looking to refine your skills, upGrad's machine learning programs can guide you every step of the way.
Explore these additional upGrad professional programs:
- Master's Degree in Artificial Intelligence and Data Science
- Executive Diploma in Data Science & AI with IIIT-B
- Master's in Data Science Degree
Besides the above courses, you can also check out these free courses to jumpstart your learning:
For personalized guidance, schedule a counselling session with our experts at upGrad Counselling or visit one of our offline centres for a more hands-on experience.
Similar Reads:
- Deep Learning Tutorial: Master AI & Neural Networks
- Artificial Intelligence Tutorial
- Machine Learning Tutorials
- Top 10 Machine Learning Applications in 2025 and the Role of Edge Computing
- Bagging in Machine Learning: Overview, Steps, Benefits & Applications
- Cost Function In Machine Learning
- Isolation Forest Algorithm for Anomaly Detection
- Image Annotation in Machine Learning
- Quantum Computing
- Time Series Forecasting with ARIMA Models: Components, Advantages & Steps
- Bootstrap Aggregation
- Mahalanobis Distance: Formula, Python Code, Applications & Best Practices
- Exponential Smoothing Method in Forecasting: Techniques and Applications
- Support Vector Machine Svm For Anomaly Detection
FAQs
1. What are the key differences between supervised and unsupervised learning models?
Supervised learning models in machine learning require labeled data to learn from, meaning the algorithm learns from input-output pairings to predict outputs for new data. On the other hand, unsupervised learning works with unlabeled data and seeks to uncover hidden patterns or structures, such as clustering or dimensionality reduction.
2. How do I choose between a linear regression model and a decision tree?
Linear regression is ideal for predicting continuous values with a linear relationship between input and output variables. Decision trees, however, are better for classification tasks or when handling non-linear relationships and feature interactions.
3. What is K-Means clustering used for in machine learning?
K-Means clustering is an unsupervised learning algorithm for grouping similar data points into clusters. It helps identify patterns or relationships within the data, such as segmenting customers based on purchasing behavior.
4. How is reinforcement learning applied in real-world scenarios?
Reinforcement learning is used when an agent interacts with an environment to maximize rewards. Common applications include robotics, gaming, recommendation systems, and autonomous vehicles, where the agent learns optimal strategies through trial and error.
5. How do I avoid overfitting in machine learning models?
To prevent overfitting, you can use cross-validation, regularization (L1 or L2), simplifying the model, and gathering more training data. Early stopping, where training halts once performance on the validation set degrades, can also be effective.
6. How do precision and recall help evaluate a model's performance?
Precision measures the accuracy of positive predictions, while recall evaluates how many actual positives were correctly identified. Balancing these metrics is crucial in tasks where the cost of false positives or false negatives is high.
7. How do ensemble models improve machine learning accuracy?
Ensemble models, like Random Forest and Gradient Boosting, combine the predictions of multiple models to improve accuracy. These methods reduce bias and variance by averaging predictions or correcting errors from individual models, leading to better generalization.
8. When is it best to use Support Vector Machines (SVM) in classification tasks?
SVMs are particularly useful when the data has a clear margin of separation and for binary classification tasks. They are effective in high-dimensional spaces, like text classification and image recognition, where other models might struggle.
9. What sets neural networks apart from decision trees in machine learning?
Neural networks excel at learning complex patterns in unstructured data, like images and text, through multiple layers of interconnected nodes. Decision trees, in contrast, are simpler, making decisions based on hierarchical input data splits, and are easier to interpret.
10. What are the main advantages of using Random Forest over a single decision tree?
Random Forest improves upon a single decision tree by averaging predictions from multiple trees built on random data samples. This reduces overfitting, improves accuracy, and increases robustness, making it more reliable for complex datasets.
11. What are the challenges of using deep neural networks for small datasets?
Learning models in machine learning, particularly deep learning models, are designed to handle large datasets by learning intricate patterns and representations through multiple layers of neural networks. These models benefit from the data volume, allowing them to perform tasks such as image recognition or natural language processing more effectively than traditional models.





upGrad Learner Support
Talk to our experts. We are available 7 days a week, 10 AM to 7 PM
Indian Nationals
Foreign Nationals
Disclaimer
The above statistics depend on various factors and individual results may vary. Past performance is no guarantee of future results.
The student assumes full responsibility for all expenses associated with visas, travel, & related costs. upGrad does not .