All courses
Agentic AI
Agentic AI
Artificial Intelligence
Degree / Exec. PG

IIIT Bangalore
Executive Diploma in Machine Learning and AI
OPJ Global University
Master’s Degree in Artificial Intelligence and Data Science
Liverpool John Moores University
Master of Science in Machine Learning & AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIExecutive Certificate

IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
IIIT-B & IIM, Udaipur
Chief Data and AI Officer Programme
IIIT Bangalore
Executive Programme in Generative AI for Leaders
upGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentOffline Bootcamps

upGrad
Data Science and AI-MLDoctorate
For All Domains
IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
Swiss School of Business and Management
Global Doctor of Business Administration from SSBM
Edgewood University
Doctorate in Business Administration by Edgewood UniversityGolden Gate University
Doctor of Business Administration From Golden Gate University
Rushford Business School
Doctor of Business Administration from Rushford Business School, Switzerland-d9bdeff6165f4eb1ba2adcebde78e961.svg)
University of Waterloo
Chief Technology and AI Officer ProgramLeadership / AI
Golden Gate University
DBA in Emerging Technologies with a concentration in Generative and Agentic AIMachine Learning
Machine Learning
Data Science
Degree / Exec. PG
O.P Jindal Global University
Master’s Degree in Artificial Intelligence and Data ScienceIIIT Bangalore
Executive Diploma in Data Science & AILiverpool John Moores University
Master of Science in Data ScienceExecutive Certificate
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftIIIT-B & IIM, Udaipur
Chief Data and AI Officer ProgrammeupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceupGrad | Microsoft
Gen AI Mastery Certificate for Content CreationOffline Bootcamps
upGrad
Data Science and AI-MLMBA
Masters

Liverpool John Moores University
Master of Business Administration from Liverpool John Moores University (LJMU) with IIM Udaipur CertificationO.P.Jindal Global University
MBA (with Career Acceleration Program by upGrad)Edgewood University
MBA from Edgewood UniversityO.P.Jindal Global University
MBA from O.P.Jindal Global UniversityExecutive Certificate

IMT, Ghaziabad
Advanced General Management ProgramMarketing
Executive Certificate
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Content CreationOffline Bootcamps
upGrad
Digital MarketingManagement
Degree
O.P Jindal Global University
MSc in International Accounting & Finance (ACCA integrated)
Golden Gate University
Master of Arts in Industrial-Organizational PsychologyExecutive Certificate
IIIT-B & IIM, Udaipur
Chief Technology Officer & AI Leadership ProgrammeIIIT-B & IIM, Udaipur
Chief Data and AI Officer Programme
IIM Kozhikode
Human Resource Analytics Course from IIM-KupGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftEducation
Education

Northeastern University
Master of Education (M.Ed.) from Northeastern UniversityEdgewood University
Doctor of Education (Ed.D.)Edgewood University
Master of Education (M.Ed.) from Edgewood UniversityCertifications
Project Management
Certification

Knowledgehut
Leadership And Communications In ProjectsKnowledgehut
Microsoft Project 2007/2010-ae8d039bbd2a41318308f8d26b52ac8f.svg)
Knowledgehut
Financial Management For Project ManagersKnowledgehut
Fundamentals of Earned Value Management (EVM)Knowledgehut
Fundamentals of Portfolio ManagementKnowledgehut
Fundamentals of Program Management-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
Knowledgehut
CAPM® CertificationsKnowledgehut
Microsoft® Project 2016Certifications & Trainings
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)
Knowledgehut
PMP® CertificationKnowledgehut
PMI-RMP® CertificationKnowledgehut
PMP Renewal Learning PathKnowledgehut
Oracle Primavera P6 V18.8Knowledgehut
Microsoft® Project 2013Knowledgehut
PfMP® Certification CourseKnowledgehut
Project Planning and MonitoringPrince2 Certifications

Knowledgehut
PRINCE2® FoundationKnowledgehut
PRINCE2® PractitionerKnowledgehut
PRINCE2 Agile Foundation and PractitionerKnowledgehut
PRINCE2 Agile® Foundation CertificationKnowledgehut
PRINCE2 Agile® Practitioner CertificationManagement Certifications
Knowledgehut
Project Management Masters Certification ProgramKnowledgehut
Change ManagementKnowledgehut
Project Management TechniquesKnowledgehut
Product Management Certification ProgramKnowledgehut
Project Risk Management- Study abroad
- Offline centres
- uGSOT - B.Tech
More
%20(2)-db0b6f38da9c485faf76e366793c9b9e.webp&w=128&q=75)



48. Variance in ML
A Comprehensive Guide to Overfitting in ML
Did you know? In machine learning, a model that achieves near-perfect accuracy on its training data can still perform poorly in the real world, a classic sign of overfitting. This happens because the model memorizes the training examples, including the noise, instead of learning the underlying patterns needed to make accurate predictions on new data |
Overfitting in ML occurs when a model learns the training data too well, capturing not just the underlying patterns but also the noise and anomalies. While the model may perform excellently on the training data, it struggles to generalize to new, unseen data, leading to poor actual performance. This is a common pitfall in machine learning projects, affecting the model’s ability to make accurate predictions on test or production data.
In this comprehensive guide, we will explore what overfitting in ML is, why it happens, and how it negatively impacts model performance. You’ll learn about the key causes of overfitting, how to detect it, and most importantly, the techniques to prevent overfitting.
Boost your career with Artificial Intelligence and Machine Learning - AI & ML courses. Learn from top faculty, cover everything from data science to deep learning, and access 1,000+ hiring partners. Gain practical skills, build smarter models, and achieve real career growth.
Understanding Overfitting in ML and Its Impact
Overfitting in ML is like memorizing answers for a test instead of understanding the concepts. In this analogy, the test represents unseen data, while the memorized answers are patterns the model learned from training data. The model may perform perfectly during training but struggles when faced with new inputs, just like a student who can’t adapt memorized answers to unfamiliar questions.
This happens because the model becomes overly complex, capturing noise and irrelevant details instead of general trends. As a result, it loses the ability to generalize and performs poorly on actual data. Understanding overfitting is essential to apply techniques like regularization and cross-validation, which help the model make accurate predictions on unseen data.
Key Concepts to Understand Overfitting:
- High Variance: When a model is overfitted, it exhibits high variance, meaning its performance is inconsistent when applied to different datasets.
- Noise Fitting: Overfitting in ML leads the models to often "learn" random fluctuations or noise from the data, which do not generalize well to new examples.
- Poor Generalization: The core problem with overfitting in ML is that the model becomes too specific to the training data, losing its ability to generalize to new, unseen data.
If you’re aiming to build strong expertise in overfitting in ML and learn practical techniques to prevent overfitting, these upGrad programs are designed to equip you with essential skills and applications:
- Executive Diploma in Machine Learning and AI with IIIT-B
- Generative AI Mastery Certificate for Managerial Excellence
- Generative AI Mastery Certificate for Software Development
Top Causes of Overfitting in ML
%20Top%20Causes%20of%20Overfitting%20in%20ML%20-%20visual%20selection-3da1fd7209dd4069b113fdc458df035c.png)
Several factors contribute to Overfitting in ML models. Understanding these causes is the first step toward mitigating them and ensuring that your models generalize well to new data.
- Small Datasets: When the dataset is too small, the model has limited examples to learn from and tends to memorize the training data rather than identifying general trends. This results in poor performance on new data, as the model has not been exposed to enough variability to generalize effectively.
- Overly Complex Models: Models with a large number of parameters, such as deep neural networks, can fit every nuance in the training data, including noise. While this may lead to high accuracy during training, it significantly increases the model's variance and reduces its ability to perform consistently on unseen data.
- Lack of Regularization: Without regularization techniques like L1 (Lasso) or L2 (Ridge), models are free to grow in complexity and may overfit by assigning undue importance to minor patterns or noise. Regularization helps constrain the model, encouraging simpler representations that generalize better across different datasets.
- Noisy Data: Data that includes errors, irrelevant features, or random fluctuations can mislead the model into learning patterns that don’t hold in actual scenarios. This noise increases the risk of overfitting, especially in flexible models. However, applying preprocessing techniques such as noise filtering, feature selection, or outlier detection can help reduce its impact and improve model robustness.
Also read: What is Overfitting & Underfitting In Machine Learning? [Everything You Need to Learn]
Let’s explore how to detect overfitting in your machine learning models and the tools available to help you assess whether your model is generalizing well to unseen data.
How Can You Detect Overfitting in ML Models?
Detecting overfitting in ML models is crucial to ensure they perform well on unseen data rather than just memorizing the training set. A clear sign of overfitting is a noticeable gap between training and test performance, where the model achieves high accuracy on training data but performs poorly on validation or test data. This suggests the model has learned specific patterns or noise that do not generalize.
One effective method for identifying overfitting is k-fold cross-validation, where the data is split into k subsets (folds). The model is trained on k−1 folds and validated on the remaining one. This process repeats across all folds. If the model shows consistent performance across folds, it indicates good generalization. However, large variance in scores across different folds can point to overfitting.
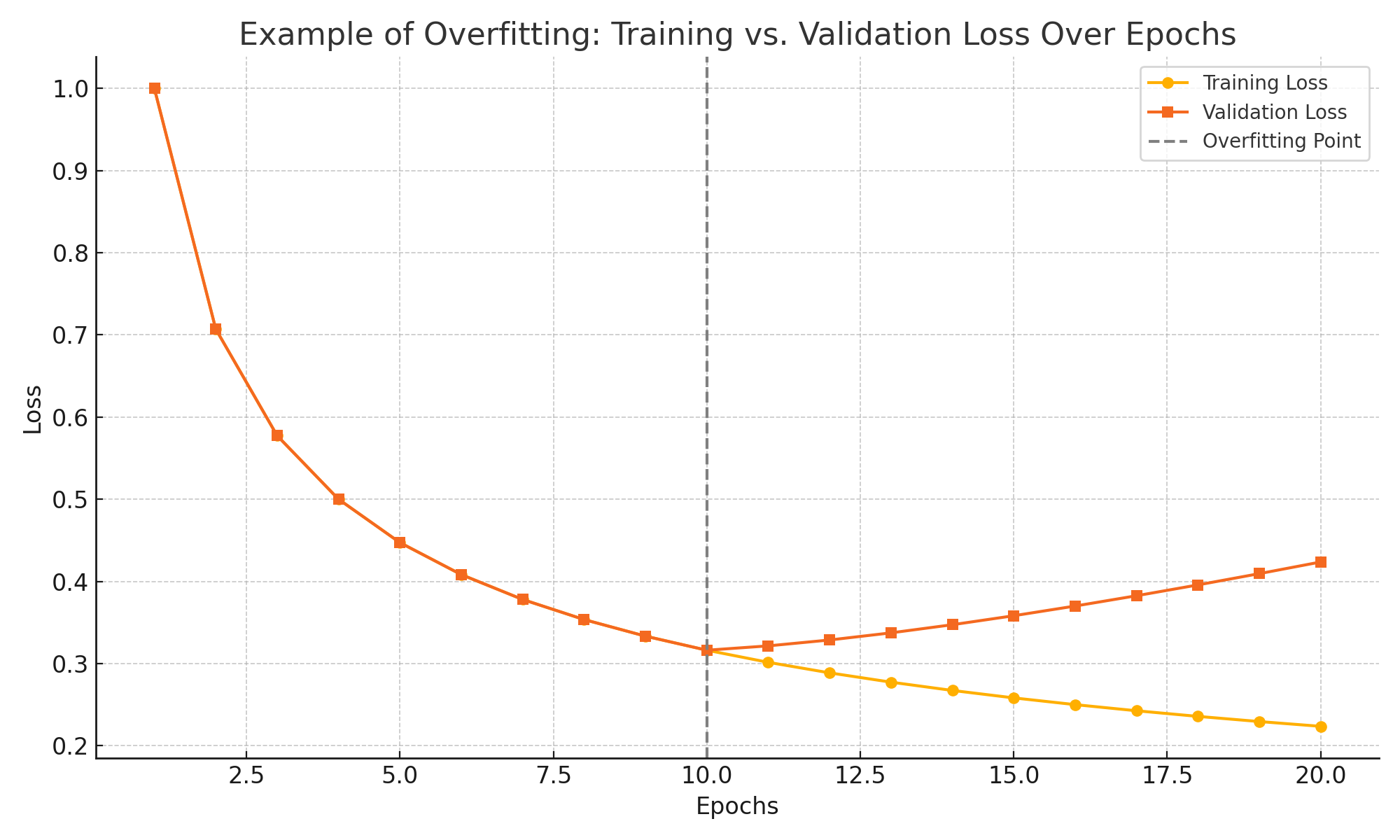
Figure: Overfitting occurs when the validation loss begins to rise while training loss continues to fall, a sign the model is learning noise instead of generalizable patterns.
Training vs. validation performance curves are another useful tool. By plotting training and validation loss over epochs, you can visually track how the model is learning. A classic sign of overfitting is when the training loss continues to decrease, but the validation loss starts increasing, indicating the model is beginning to memorize noise in the training set rather than learning useful, general patterns.
Common Signs of Overfitting:
- High accuracy on training data but low accuracy on validation/test data
- Training loss decreases while validation loss starts to rise after a point
- Significant performance variation across folds during cross-validation
- Models that perform well on training data but capture noise or outliers
Also read: Top 5 Machine Learning Models Explained For Beginners
How to Fix an Overfitted Model? Key Techniques
%20How%20to%20Fix%20an%20Overfitted%20Model_%20Key%20Techniques%20-%20visual%20selection-f9a7527aab8c401aa60a02ca0f30ba56.png)
Overfitting occurs when a machine learning model learns not only the underlying patterns in the training data but also the noise or random fluctuations, leading to poor performance on new, unseen data. Fortunately, several proven techniques can help you reduce overfitting and improve your model’s ability to generalize. Here’s a detailed look at the key strategies:
1. Regularization (L1 and L2)
Regularization techniques add a penalty term to the model’s loss function to discourage overly complex models. By constraining the size of the model’s parameters (weights), regularization forces the model to focus on the most important features rather than fitting noise or minor fluctuations.
- L1 Regularization (Lasso): Adds a penalty proportional to the absolute value of the coefficients. This tends to push some weights exactly to zero, effectively performing feature selection and encouraging sparsity in the model.
- L2 Regularization (Ridge): Adds a penalty proportional to the square of the coefficients. This encourages smaller, more evenly distributed weights rather than completely eliminating features, making the model less sensitive to noise.
By limiting the complexity of the model parameters, regularization helps prevent overfitting, especially when dealing with high-dimensional data.
2. Early Stopping
Early stopping is a technique commonly used in training iterative models such as neural networks. During training, the model’s performance is evaluated on a separate validation dataset at the end of each epoch. If the performance on this validation set starts to degrade or stagnate while training loss continues to improve, it’s a sign that the model is beginning to overfit.
By stopping training at this point, before the model starts memorizing noise, you ensure the model maintains good generalization to unseen data. Early stopping is an efficient and practical way to prevent overfitting without modifying the model architecture or adding complexity.
3. Dropout (Neural Networks)
Dropout is a regularization technique specific to neural networks that helps prevent neurons from co-adapting too strongly. During each training iteration, dropout randomly “drops” (sets to zero) a fraction of neurons in the network, temporarily disabling them.
This forces the neural network to learn more robust and distributed representations because it cannot rely on any single neuron. As a result, the model becomes less prone to overfitting and generalizes better on new data. Dropout is simple to implement and highly effective, especially in deep learning models.
4. Pruning (Decision Trees)
Decision trees are prone to overfitting because they can grow very deep and complex, fitting even the smallest variations in training data. Pruning is a method to reduce this complexity by cutting back parts of the tree that do not provide significant predictive power.
- Pre-pruning: Limits the growth of the tree during training by setting parameters like maximum depth or minimum samples per leaf. This prevents the tree from becoming too complex upfront.
- Post-pruning: Involves growing the full tree and then trimming back branches based on validation performance or complexity measures (though some libraries, like scikit-learn, do not support this).
Pruning results in simpler, more interpretable trees that generalize better to unseen data.
5. Data Augmentation
Overfitting is a common risk when working with limited datasets, especially in image or text domains, because the model sees only a small number of examples. Data augmentation tackles this by artificially expanding the training set through transformations and modifications of the existing data.
This could mean rotations, shifts, flips, or changes in brightness and contrast for images. Text could involve synonym replacement, paraphrasing, or random insertion of words. By exposing the model to a wider variety of examples, data augmentation helps improve robustness and reduces overfitting without collecting new data.
6. Ensemble Methods
Ensemble methods combine multiple models to make predictions, effectively averaging out their individual errors. This reduces variance and leads to better generalization.
Popular ensemble techniques include:
- Random Forests: Build multiple decision trees on random subsets of data and features, then aggregate their predictions.
- Gradient Boosting: Sequentially build models that correct errors made by previous ones.
Because ensembles leverage the “wisdom of the crowd,” they tend to be more robust to overfitting compared to individual models.
If you’re eager to master neural networks and deep learning, upGrad’s Fundamentals of Deep Learning and Neural Networks course is perfect for you. In just 28 hours, explore core concepts like perceptrons, neuron functions, and deep learning architectures. Plus, earn a verified e-certificate from upGrad to showcase your expertise.
Also read: Understanding 8 Types of Neural Networks in AI & Application
Next, let’s explore practical examples that illustrate overfitting in machine learning models.
Overfitting in ML: Practical Examples You Can Learn From
Understanding how overfitting shows up in practice and learning concrete ways to address it can help you build more reliable and accurate models. The following examples illustrate typical scenarios where overfitting occurs, along with proven solutions to fix the problem effectively.
Example 1: Linear Regression Overfitting and Ridge Regression Solution
Imagine you train a linear regression model on a dataset, and it achieves excellent accuracy on the training data but performs poorly on new data. This is a classic case of overfitting, where the model has learned noise or too-specific patterns that don’t generalize.
Scenario: A housing price prediction model fits the training data perfectly but fails to predict prices accurately for unseen houses.
Solution: Apply Ridge Regression (L2 regularization), which penalizes large coefficients and reduces model complexity, leading to better generalization.
from sklearn.linear_model import Ridge
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Split the dataset into training and test sets (80% train, 20% test)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train Ridge regression model with L2 regularization (alpha controls strength)
ridge = Ridge(alpha=1.0)
ridge.fit(X_train, y_train)
# Predict on training and test data
train_pred = ridge.predict(X_train)
test_pred = ridge.predict(X_test)
# Calculate Mean Squared Error for train and test sets
print("Train MSE:", mean_squared_error(y_train, train_pred))
print("Test MSE:", mean_squared_error(y_test, test_pred))
Expected Output (example):
Train MSE: 12.5
Test MSE: 18.7
Explanation: The training MSE is lower than the test MSE, indicating the model fits the training data well but generalizes less effectively to new data. Ridge regression helps by shrinking coefficients, which reduces overfitting and narrows this performance gap.
Example 2: Neural Network Overfitting and Solutions with Dropout and Early Stopping
Neural networks, especially deep ones, are highly prone to overfitting, particularly on small datasets. An overtrained network may achieve near-perfect training accuracy but fail to perform on validation or test data.
Scenario: A classification model trained on limited data perfectly classifies training samples but misclassifies many validation examples.
Solution: Incorporate dropout layers to prevent neurons from co-adapting, and use early stopping to halt training before the model begins to memorize noise.
Note on Validation Data: In this example, validation data (X_val, y_val) should be created explicitly by splitting the training set or by using a validation_split parameter during training. For clarity, here’s how to create it using a split:
from sklearn.model_selection import train_test_split
# Split the original training data into training and validation sets (e.g., 80% train, 20% val)
X_train, X_val, y_train, y_val = train_test_split(X_train_full, y_train_full, test_size=0.2, random_state=42)
Alternatively, you can use validation_split inside model.fit() (if using Keras) to automatically reserve part of the training data for validation.
model.fit(X_train, y_train, validation_split=0.2, epochs=100, callbacks=[early_stopping])
Here’s the full example with explicit validation split:
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.callbacks import EarlyStopping
from sklearn.model_selection import train_test_split
# Split training data into train and validation sets
X_train, X_val, y_train, y_val = train_test_split(X_train_full, y_train_full, test_size=0.2, random_state=42)
model = Sequential([
Dense(128, activation='relu', input_shape=(X_train.shape[1],)),
Dropout(0.3),
Dense(64, activation='relu'),
Dropout(0.3),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
early_stopping = EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True)
history = model.fit(X_train, y_train, validation_data=(X_val, y_val), epochs=100, callbacks=[early_stopping])
Expected Output: During training, you will see the loss and accuracy for both training and validation sets. Early stopping halts training once the validation loss stops improving, for example, after 15 epochs.
Epoch 15/100
loss: 0.15 - accuracy: 0.95 - val_loss: 0.20 - val_accuracy: 0.92
Early stopping triggered, restoring best model weights.
Explanation: The model initially improves on both training and validation data. When validation loss stops decreasing, early stopping prevents further training to avoid overfitting. Dropout layers reduce co-adaptation of neurons, helping the model generalize better.
These examples demonstrate how overfitting can appear in different models and highlight practical steps to address it, ensuring your machine learning models remain robust and generalize well to new data.
Ready to dive into NLP? Enroll in Introduction to Natural Language Processing Courses by upGrad and start building real-world skills in text processing, AI, and automation, completely free. Learn at your own pace and power your career with NLP today!
Also Read: What is Machine Learning and Why it matters
Now that you’ve seen how overfitting manifests in actual machine learning scenarios and the techniques used to tackle it, it’s time to put your understanding to the test. Let’s check how well you grasp the concepts with a quick quiz!
Test Your Understanding of Overfitting in ML
Test your knowledge with these 10 multiple-choice questions focused on overfitting in ML and techniques to prevent overfitting:
- What does Overfitting in ML indicate?
- The model performs well on both training and test data
- The model performs well on training data but poorly on unseen data
- The model is too simple to capture the data patterns
- The model generalizes perfectly to new data
- Which of the following is a common cause of overfitting?
- Large dataset size
- Using simple linear models
- Very complex models with many parameters
- High-quality, noise-free data
- How can K-fold cross-validation help in detecting overfitting?
- By training the model on only one subset of the data
- By evaluating model performance on multiple data splits
- By increasing the size of the training data
- By reducing the number of features
- What is the main purpose of regularization in ML models?
- To increase the number of features used
- To penalize model complexity and reduce overfitting
- To increase training time
- To remove data noise
- Which technique stops training when the validation loss stops improving?
- Dropout
- Early stopping
- Pruning
- Data augmentation
- How does dropout help prevent overfitting in neural networks?
- By increasing the number of neurons
- By randomly disabling some neurons during training
- By adding noise to the input data
- By stopping training early
- What is pruning used for in decision tree models?
- To increase tree depth
- To remove branches with little predictive power
- To add more features
- To speed up data augmentation
- Why is data augmentation useful in preventing overfitting?
- It reduces the size of the training data
- It artificially increases the diversity of training samples
- It simplifies the model architecture
- It removes irrelevant features
- Ensemble methods help reduce overfitting by:
- Combining predictions from multiple models to improve robustness
- Using a single complex model
- Ignoring validation data
- Increasing training data noise
- What is a clear sign that a model is overfitting?
- High test accuracy and low training accuracy
- High training accuracy and low test accuracy
- Equal accuracy on both training and test data
- Low accuracy on both training and test data
Also Read: 50+ Must-Know Machine Learning Interview Questions for 2025
Now that you’ve tackled key concepts and practical challenges around overfitting, it’s time to take the next step in your ML journey with upGrad’s expert-led learning programs.
How Can upGrad Help You Become an Expert in ML?
Overfitting in machine learning occurs when a model learns the training data too well, including its noise and outliers, resulting in poor generalization to new data. It’s often caused by overly complex models, insufficient data, or lack of regularization. To prevent overfitting, use techniques like cross-validation, early stopping, pruning, and applying dropout or L1/L2 regularization. Always validate performance using unseen data.
If you want to deepen your data skills and apply such functions effectively, upGrad offers tailored programs designed for all levels—from beginners to advanced learners.
Explore these courses to build your expertise:
- Master’s Degree in Artificial Intelligence and Data Science
- Advanced Generative AI Certification Course
Curious which courses can help you excel in machine learning in 2025? Contact upGrad for personalized counseling and valuable insights. For more details, you can visit your nearest upGrad offline center.
FAQs
1. What are overfitting and underfitting in machine learning, and how does cross-validation help?
Overfitting happens when a model learns both the signal and the noise in training data, reducing its ability to generalize to new data. Underfitting occurs when a model is too simplistic to capture the underlying patterns, resulting in poor performance on both training and test datasets. Cross-validation, particularly k-fold, helps evaluate model performance across different data splits, providing insights into generalization. It reduces the likelihood of overfitting by validating the model on multiple subsets of the data.
2. How does dataset size influence overfitting in ML?
Small datasets increase the risk of overfitting because the model has fewer examples to learn from, often leading to memorization of noise. With limited data, the model captures patterns that are not representative of the overall population. Larger datasets provide broader variability and context, helping the model learn more generalizable patterns. As a result, training on more data usually enhances robustness and reduces overfitting.
3. What is the impact of model complexity on overfitting in ML?
High model complexity allows the algorithm to fit intricate details of the training data, including noise, which results in overfitting. Complex models often have more parameters, which can memorize the training data instead of learning underlying trends. This leads to poor generalization when the model is exposed to unseen examples. To control this, complexity can be managed with techniques like regularization, feature selection, and architectural simplification.
4. Are there cases when some degree of overfitting is acceptable?
Yes, in high-risk domains such as medical diagnosis or fraud detection, slight overfitting can be tolerated to prioritize sensitivity. In these scenarios, missing a true positive (e.g., failing to detect a disease) can have more serious consequences than a false positive. Therefore, models are sometimes allowed to err on the side of caution, even if that means overfitting slightly. However, this trade-off must be made carefully, with constant monitoring and domain knowledge.
5. What role does noise in the dataset play in overfitting?
Noise includes irrelevant, incorrect, or random variations in data that do not represent meaningful patterns. When models learn this noise as if it were signal, they become less effective on new data. Overfitting due to noise leads to decreased generalization and higher test error. Cleaning the data and using regularization or dropout techniques can help mitigate this issue.
6. How do regularization techniques differ from data augmentation in preventing overfitting?
Regularization techniques such as L1 and L2 reduce overfitting by penalizing complex models and discouraging large weights, effectively simplifying the model. These methods work internally by altering the loss function to constrain the model’s capacity. In contrast, data augmentation works externally by increasing the size and variability of the training dataset through transformations. Both aim to improve generalization, but from different angles—one by simplifying the model, the other by enriching the input data.
7. Can feature selection help in reducing overfitting?
Yes, feature selection is a key strategy to reduce overfitting by removing irrelevant or redundant input variables. Unnecessary features often introduce noise and increase model complexity, making it easier for the model to latch onto spurious patterns. By selecting only the most informative features, the model becomes more interpretable and generalizes better. Techniques like recursive feature elimination and information gain can aid in effective feature selection.
8. Is early stopping only applicable to neural networks?
While early stopping is widely used in neural networks, it is not exclusive to them. Any iterative model—such as gradient boosting or even logistic regression trained via iterative solvers—can use early stopping based on validation metrics. The key idea is to halt training once performance on unseen data begins to degrade, thereby preventing memorization of noise. This makes early stopping a general-purpose tool in machine learning optimization.
9. How do ensemble methods reduce overfitting?
Ensemble methods like Random Forest and Gradient Boosting combine predictions from multiple models to reduce overall variance. By leveraging different hypotheses or training subsets, ensembles balance out individual model weaknesses. This approach smooths over any one model’s tendency to overfit to noise or outliers in the data. As a result, ensemble models typically achieve better generalization and higher predictive accuracy.
10. How can I monitor my model in production to detect signs of overfitting over time?
Monitoring model performance in production involves tracking metrics like accuracy, precision, recall, and data drift on live inputs. Tools such as MLflow, Prometheus, or custom dashboards can flag deviations from expected behavior. Additionally, shadow models and concept drift detectors can reveal when the model no longer performs as expected due to changing data patterns. Regular evaluations against updated ground truth ensure timely retraining and mitigate overfitting risks.
11. Why is pruning important for controlling overfitting in decision trees?
Pruning reduces the size and complexity of decision trees by removing branches that provide little predictive value. Without pruning, trees can grow deep and fit training noise, leading to poor generalization. Pruning can be done during training (pre-pruning) or after the tree has been built (post-pruning), depending on the library used. This results in a simpler, more interpretable tree that performs better on unseen data.





upGrad Learner Support
Talk to our experts. We are available 7 days a week, 10 AM to 7 PM
Indian Nationals
Foreign Nationals
