All courses
Agentic AI
Agentic AI
Artificial Intelligence
Degree / Exec. PG

IIIT Bangalore
Executive Diploma in Machine Learning and AI
OPJ Global University
Master’s Degree in Artificial Intelligence and Data Science
Liverpool John Moores University
Master of Science in Machine Learning & AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIExecutive Certificate

IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
IIIT Bangalore
Executive Programme in Generative AI for Leaders
upGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceOffline Bootcamps

upGrad
Data Science and AI-MLDoctorate
For All Domains
IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
Swiss School of Business and Management
Global Doctor of Business Administration from SSBM
Edgewood University
Doctorate in Business Administration by Edgewood UniversityGolden Gate University
Doctor of Business Administration From Golden Gate University
Rushford Business School
Doctor of Business Administration from Rushford Business School, Switzerland-d9bdeff6165f4eb1ba2adcebde78e961.svg)
University of Waterloo
Chief Technology and AI Officer ProgramLeadership / AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIMachine Learning
Machine Learning
Data Science
Degree / Exec. PG
O.P Jindal Global University
Master’s Degree in Artificial Intelligence and Data ScienceIIIT Bangalore
Executive Diploma in Data Science & AILiverpool John Moores University
Master of Science in Data ScienceExecutive Certificate
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceupGrad | Microsoft
Gen AI Mastery Certificate for Content CreationOffline Bootcamps
upGrad
Data Science and AI-MLMBA
Masters

Liverpool School of Business
Master of Business Administration from Liverpool Business School with IIM Udaipur Certification
Paris School of Business
Master of Science in Business Management and TechnologyO.P.Jindal Global University
MBA (with Career Acceleration Program by upGrad)Edgewood University
MBA from Edgewood UniversityO.P.Jindal Global University
MBA from O.P.Jindal Global UniversityExecutive Certificate

IMT, Ghaziabad
Advanced General Management ProgramMarketing
Executive Certificate
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Content CreationOffline Bootcamps
upGrad
Digital MarketingManagement
Degree
O.P Jindal Global University
MSc in International Accounting & Finance (ACCA integrated)
Golden Gate University
Master of Arts in Industrial-Organizational PsychologyExecutive Certificate

IIIT-B & IIM, Udaipur
Chief Technology Officer & AI Leadership ProgrammeIIIT-B & IIM, Udaipur
Chief Data and AI Officer Programme
IIM Kozhikode
Human Resource Analytics Course from IIM-KupGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftEducation
Education

Northeastern University
Master of Education (M.Ed.) from Northeastern UniversityEdgewood University
Doctor of Education (Ed.D.)Edgewood University
Master of Education (M.Ed.) from Edgewood UniversityCertifications
Project Management
Certification

Knowledgehut
Leadership And Communications In ProjectsKnowledgehut
Microsoft Project 2007/2010-ae8d039bbd2a41318308f8d26b52ac8f.svg)
Knowledgehut
Financial Management For Project ManagersKnowledgehut
Fundamentals of Earned Value Management (EVM)Knowledgehut
Fundamentals of Portfolio ManagementKnowledgehut
Fundamentals of Program Management-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
Knowledgehut
CAPM® CertificationsKnowledgehut
Microsoft® Project 2016Certifications & Trainings
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)
Knowledgehut
PMP® CertificationKnowledgehut
PMI-RMP® CertificationKnowledgehut
PMP Renewal Learning PathKnowledgehut
Oracle Primavera P6 V18.8Knowledgehut
Microsoft® Project 2013Knowledgehut
PfMP® Certification CourseKnowledgehut
Project Planning and MonitoringPrince2 Certifications

Knowledgehut
PRINCE2® FoundationKnowledgehut
PRINCE2® PractitionerKnowledgehut
PRINCE2 Agile Foundation and PractitionerKnowledgehut
PRINCE2 Agile® Foundation CertificationKnowledgehut
PRINCE2 Agile® Practitioner CertificationManagement Certifications
Knowledgehut
Project Management Masters Certification ProgramKnowledgehut
Change ManagementKnowledgehut
Project Management TechniquesKnowledgehut
Product Management Certification ProgramKnowledgehut
Project Risk Management- Study abroad
- Offline centres
- uGSOT - B.Tech
More
%20(2)-db0b6f38da9c485faf76e366793c9b9e.webp&w=128&q=75)


48. Variance in ML
Understanding Gradient Boosting in Machine Learning: Techniques, Applications, and Optimization
Do you know? In 2025, researchers introduced the first unified online learning framework for Gradient Boosting Decision Trees (GBDT), supporting both incremental and decremental learning. This framework allows models to add or remove data instances without retraining from scratch, enabling real-time updates and reducing learning costs. |
Gradient boosting has become a go-to algorithm technique that builds predictive models by combining multiple weak learners to form a stronger, more accurate model. It is widely used for classification and regression tasks, offering significant improvements in performance by reducing bias and variance.
With its ability to focus on complex cases by giving more weight to errors, gradient boosting has become a go-to algorithm for many machine learning practitioners. Gradient boosting in machine learning repeatedly refines its predictions by minimizing errors in each step, effectively handling a wide range of real-world problems.
In this blog, you will explore what is gradient boosting in machine learning, how it works, including the key techniques behind its effectiveness, challenges, benefits, applications, and more.
Take your skills to the next level with upGrad’s Advanced Machine Learning Courses Program. Learn directly from industry experts and build real-world, impactful projects to enhance your AI and Data Science career.
What is Gradient Boosting in Machine Learning?
GB is an ML technique that improves the model performance, making the model stronger and more accurate. In ensemble learning, several models are trained to work together, each contributing to the final output. GB specifically stands out because it sequentially corrects errors made by previous models.
Each subsequent model in the sequence focuses on the instances that the previous models got wrong and effectively boosts the overall system's performance. The key idea behind boosting is that each new model is trained to fix the mistakes made by its predecessors. It is most commonly used with decision trees as the base learners, where each tree is built to predict the residuals (or errors) from the previous tree.
Looking to step into your career and stand among the 12% of the global workforce that possess AI skills? Then choose the following upGrad ML Courses:
- Executive Programme in Generative AI for Leaders
- Generative AI Foundations Certificate Program
- Master of Science in Machine Learning & AI
The Core Mechanics of Gradient Boosting: Sequential Error Correction
GB operates on the principle of sequentially building models to correct the errors of previous models, refining the overall prediction with each step. This iterative process allows the model to improve accuracy by focusing on the residuals (errors) from the earlier models in the sequence.
-72caf8a0276b465bb74e29a332ac5b2b.png)
Here’s a closer look at how GB works:
- Building a Base Model: The process begins by creating a base model, typically a simple decision tree, which generates an initial prediction. For example, in predicting the churn rate of a subscription service, the base model might forecast a churn rate of 30%. However, the actual churn rate observed is 40%. The discrepancy between the predicted and actual values, known as the residual error, is calculated as:
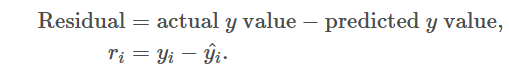
In this case: Residual Error = 40%−30% = 10%
Therefore, the residual error, or the difference between the predicted and actual churn rates, is 10%.
- Calculating Residuals: The difference between the model's prediction and the actual value (residuals) is calculated. For example, for customer churn prediction, the residual is 40% (actual), 30% (predicted) = 10%. This residual indicates how much the first model missed and serves as the focus for the next model.
- Building New Models on Residuals: Each new model is trained to minimize these residuals, focusing on correcting the errors made by the previous model. For example, the second model will focus specifically on correcting that 10% error. If the second model predicts a 35% churn rate, it’s trying to reduce the error in the next iteration.
- Iterative Refinement: The process continues iteratively, with each new model improving on the previous one. For example, if the third model corrects the remaining 5% error, the final prediction is 40%, which is closer to the actual churn rate. The model refines its prediction with each new iteration, reducing the overall error.
- Final Prediction: The final output is a weighted combination of the predictions made by all the models in the ensemble. For example, the first model predicts 30%, the second predicts 35%, and the third predicts 40%. The final model combines these predictions, giving more weight to the third model for a final prediction of 39%, which is much closer to the actual churn rate.
This sequential error correction approach allows GB to create highly accurate predictive models by using the strengths of multiple decision trees. It is particularly effective for non-linear relationships and complex datasets, where individual models might struggle to capture intricate patterns.
The Gradient Boosting Machine (GBM) Model: Structure and Functionality
The Gradient Boosting Machine (GBM) model's core functionality revolves around iteratively refining predictions by correcting errors made by previous models, making it particularly effective in classification and regression tasks.
Here’s a breakdown of how GBM works:
- Weak Learners: The first step in GBM is to create an initial, typically shallow decision tree, which is trained to make predictions. While this model is weak and does not perform well on its own, it establishes a baseline from which subsequent models can improve.
- Gradient-Based Error Minimization: Unlike other boosting models like AdaBoost, GBM optimizes predictions using gradient descent, which adjusts the model by directly minimizing the loss function (residuals) through a gradient-based approach. This unique error-correction strategy allows GBM to focus on areas where the model is performing poorly by calculating the gradient of the loss function with respect to the model’s parameters.
- Sequential Model Building: In contrast to simpler ensemble models, each model in the GBM sequence is trained to focus on the residual errors of its predecessor. This allows the model to iteratively improve its predictions, with each new model addressing specific weaknesses identified in the earlier ones.
- Ensemble Method: The final prediction in GBM is derived from the weighted sum of all the models in the ensemble. Later models in the sequence are given more weight, reflecting their greater accuracy in correcting errors from earlier models. This progressive refinement through iterative corrections results in highly accurate and robust predictions, even in complex datasets.
- Structural Uniqueness: One key difference between GBM and other boosting models (like AdaBoost) is that GBM allows for flexible decision tree structures, which can range from shallow trees with few splits to deeper trees. This flexibility in tree design enhances GBM’s ability to capture intricate patterns in data.
- Application and Effectiveness: GBM’s ability to combine the strengths of multiple weak learners and refine predictions iteratively makes it highly suitable for complex tasks in fields like finance, healthcare, and e-commerce, where high predictive accuracy is essential. The model’s unique gradient descent-based optimization ensures that it can outperform many other ensemble methods, especially on high-dimensional datasets.
GBM is effective because it combines the strengths of multiple weak learners, progressively improving the accuracy of the model. This makes it highly suitable for applications where predictive accuracy is crucial, such as in finance, healthcare, and e-commerce.
Also Read: Clustering in Machine Learning: Learn About Different Techniques and Applications
Above, you learned what is gradient boosting in machine learning, its core, and functions. Now, you will get insights on how this technique works and what makes it so effective in ML. Let’s explore it below!
How Does Gradient Boosting Work in Machine Learning? Key Insights and Mechanisms
To understand how GB creates accurate predictive models, let's break down the process step by step, highlighting the key components that drive its effectiveness.
Step-by-step breakdown of the Gradient Boosting process
-37fe513bed364991a8e50ff0f97db60c.png)
- Initial Prediction: The process begins with a basic model, often a decision tree, making an initial prediction. This model is typically weak on its own. For example, imagine predicting the price of a car. The first decision tree might predict ₹20,00,000, but the actual price turns out to be ₹25,00,000. The prediction error (residual) is ₹5,00,000. This first step sets the foundation for improvement in subsequent models.
- Error Calculation: The difference between the model's prediction and the actual value is calculated as the residual. In this case, the residual is the difference between ₹25,00,000 (actual) and ₹20,00,000 (predicted), which equals ₹5,00,000. This error calculation is crucial because it highlights where the model needs improvement.
- Focus on Errors: Subsequent models are trained specifically to minimize these residuals, correcting the errors made by the previous model. For example, the second model will focus on correcting the ₹5,00,000 error. If it predicts ₹24,00,000, it reduces the residual error by ₹1,00,000, improving the model's prediction accuracy.
- Iterative Learning: This iterative learning process continues with each new model. Each subsequent model refines the prediction by focusing on the errors of the previous one. For example, if the third model corrects the remaining ₹1,00,000 error, the final prediction might be ₹25,00,000, which is much closer to the actual price. This iterative correction progressively reduces prediction errors and improves the model's overall accuracy.
Advance Your Career with a Master’s in AI & Data Science with this 12-month course. Take the next step in your professional journey by earning India’s first 1-Year Master’s in AI & Data Science from India’s #1 Private University. Enhance your skills and career prospects with exclusive Microsoft Certification Credentials!
How does the model minimize errors?
The model minimizes errors using gradient descent, an optimization technique that adjusts the model’s predictions in the direction that reduces the error (residuals). In GB, after each new model is built, it focuses on correcting the mistakes (errors) made by the previous models.
Gradient Descent:
- Calculate the Gradient of the Error: The gradient represents the direction in which the error is the greatest. The model calculates how much change (adjustment) is needed to reduce the error.
- Adjust Weights: Gradient descent adjusts the model's weights to minimize the error in the predictions. By making incremental adjustments, the model gets closer to the optimal solution.
- Iterative Updates: In GB, each new model adjusts its predictions based on the gradient of the error calculated from the residuals of previous models. This iterative process refines the model and reduces prediction errors over time.
Building Gradient Boosting Models
- Training Individual Trees: Each tree in the GB ensemble is trained to predict the residuals of the previous tree. For example, in predicting monthly sales, the first tree might predict $10,000, but the actual sales are $12,000, creating a residual of $2,000. The second tree is trained to correct this $2,000 error.
- Combining Predictions: The final prediction is a weighted average of the predictions from all trees. For example, the first tree predicts $10,000, the second predicts $11,500, and the third predicts $12,000. The final prediction will be weighted toward the third tree, resulting in a more accurate prediction.
This process ensures that GB iteratively corrects errors, with the final model being a more accurate, weighted combination of the predictions from all trees.
Role of Learning Rate and Tree Depth
- Learning Rate: The learning rate is a hyperparameter that controls the magnitude of the adjustments made to the model's predictions in each iteration. A lower learning rate means that the model will make smaller adjustments to the predictions, requiring more trees to converge to the optimal solution. Although this results in a longer training process, it can often lead to better generalization, preventing the model from overfitting to the training data.
However, setting the learning rate too low can also make training inefficient, as the model may require too many trees to reach the best solution. For example, in a financial model predicting stock prices, a low learning rate can help ensure the model doesn’t overfit to the short-term fluctuations in the data, focusing on capturing more general, long-term trends.
- Tree Depth: Tree depth refers to the number of levels in the decision trees used in Gradient Boosting. Shallow trees (with fewer levels) might not capture enough of the underlying complexity of the data, leading to high bias. On the other hand, deeper trees have more splits and are more capable of modeling complex relationships, but they also risk overfitting to noise in the data, which can lead to high variance.
Finding the right balance between bias and variance is crucial for building a model that generalizes well. For example, shallow trees might miss essential relationships between variables in a healthcare model predicting patient outcomes. In contrast, deeper trees could overfit to individual patient data, making the model less reliable on new, unseen data.
Also Read: Reinforcement Learning in Machine Learning: How It Works, Key Algorithms, and Challenges
To gain a deeper understanding of how GB enhances model performance, it’s important to consider the challenges and benefits of this powerful technique. Let's explore both sides of the GB process.
Challenges and Benefits of Gradient Boosting in ML
GB is a highly effective machine learning technique, but like any powerful algorithm, it comes with its own set of challenges and benefits. Understanding both sides is essential to effectively leveraging GBM models. While GB offers exceptional accuracy, versatility, and feature interpretability, it also presents issues such as the risk of overfitting, computational complexity, and hyperparameter sensitivity.
%20Challenges%20and%20Benefits%20of%20Gradient%20Boosting%20in%20ML%20-%20visual%20selection%20(2)-508f932dd8f74d4eb3624094467ac990.png)
In this section, you will explore both the challenges that can arise when working with GBM models, as well as the benefits that make them a go-to solution for many machine learning tasks.
Let’s first start with exploring some of the common issues faced when using the GBM model.
- Overfitting Risks in Gradient Boosting
One of the primary concerns with the Gradient Boosting Machine (GBM) model is the risk of overfitting. This occurs when the model becomes excessively complex and starts to "memorize" not only the underlying patterns in the data but also the noise and outliers. As a result, while the model may perform exceptionally well on the training data, it struggles to generalize to new, unseen data, leading to poor performance on the test set or in real-world applications.
Example: If you have a noisy dataset filled with outliers or irrelevant features, the model might learn these details rather than identifying the true patterns. This results in high accuracy on the training set but poor performance on unseen data.
Solution: To prevent overfitting, several techniques can be employed. Limiting the depth of individual trees, reducing the number of trees, or introducing regularization methods such as early stopping or subsampling can help ensure that the model generalizes well to new data, rather than fitting too closely to noise or outliers.
- Computational Complexity in Gradient Boosting
While GBM models are highly effective, they can be computationally expensive, especially when working with large datasets and many iterations. The iterative nature of GBM means that each tree is built based on the residuals from the previous tree, which can lead to significant time and resource demands.
Example: Training a GBM model on a dataset with millions of samples and hundreds of features can result in long training times and considerable computational overhead. With a large number of trees, the model requires extensive resources to process each iteration.
Solution: To manage computational complexity, techniques such as parallel processing through advanced implementations like XGBoost, LightGBM, or CatBoost can significantly improve efficiency. Additionally, reducing the number of iterations or pruning trees can help alleviate the computational load, making the process more manageable without sacrificing performance.
- Sensitivity to Hyperparameters
GBM models are sensitive to hyperparameters like the learning rate and tree depth. Improper tuning of these parameters can lead to either underfitting or overfitting, as the model may not learn effectively or may become too complex.
Example: If the learning rate is set too high, the model may overshoot the optimal solution, leading to poor performance. Conversely, if it is too low, the model may not learn effectively, resulting in underfitting.
Solution: To mitigate this sensitivity, hyperparameter tuning should be done carefully, using methods like grid search or random search to find the optimal values. Additionally, cross-validation can help assess the model's performance across different hyperparameter settings, ensuring a balanced trade-off between bias and variance.
While GBM model are highly effective for many tasks, addressing challenges like overfitting, computational complexity, and hyperparameter sensitivity is crucial to achieving optimal performance. By understanding these issues and implementing strategies to mitigate them, you can harness the full power of the GBM model in your machine learning tasks.
Unlock your potential with the Fundamentals of Deep Learning and Neural Networks in 28-hour learning! This free course offers expert-led training on neural networks, model training, and AI applications. Gain hands-on insights and earn a free certificate upon completion.
Now let’s explore the benefits of GB in machine learning.
Benefits of Gradient Boosting in Machine Learning
Gradient boosting in machine learning offers several key benefits that make it a go-to choice for any ML tasks. These benefits stem from its ability to provide high accuracy, its versatility, and its ability to offer insights into feature importance.
- High Model Accuracy: One of the strongest benefits of GB is its high accuracy in predictive tasks. It consistently outperforms many other machine learning algorithms, especially when tuned correctly.
Example: In Kaggle competitions, GBM models such as XGBoost have been consistently among the top-performing models, particularly in tasks like classification and regression.
Use Case: To predict customer churn in a subscription-based service, the GBM model can outperform traditional methods like logistic regression by accurately predicting which customers are likely to cancel their subscriptions.
- Versatility and Robustness: GBM models work well across various types of data and are robust enough to overfit when used with proper techniques such as pruning or regularization.
Example: When coupled with the right feature engineering, GBM models are effective for both structured data (tabular datasets) and unstructured data (text, images).
Use Case: GBM is widely used in credit scoring to assess the risk of loan defaults. The model can handle both categorical and continuous data and can be regularized to prevent overfitting, especially when working with small datasets.
- Feature Importance and Interpretability: GB provides valuable insights into feature importance, making it easier to understand which variables have the most significant impact on predictions. This interpretability is critical for industries where understanding model decisions is important.
Example: GBM models can provide feature importance rankings, helping data scientists and business analysts understand which features are driving the model's predictions.
Use Case: In healthcare, when predicting patient readmission, GBM models can highlight which factors (such as age, previous health conditions, or medication adherence) are the most critical in determining the likelihood of a patient being readmitted.
Also Read: AI & Machine Learning Cheat Sheet: Key Models, Use Cases & When to Use Them
As machine learning continues to evolve, so do the algorithms that power it. Let’s explore how these advancements have enhanced the performance and scalability of this powerful algorithm.
Recent Innovations and Optimizations in Gradient Boosting Techniques
GB has continually evolved, with various libraries enhancing the traditional algorithm's power and scalability. Recent innovations have focused on improving speed, memory efficiency, and model accuracy while addressing common challenges like overfitting and feature handling.
%20Challenges%20and%20Benefits%20of%20Gradient%20Boosting%20in%20ML%20-%20visual%20selection%20(1)-7864f8a9b26a49dcb1a71aa3e6f22fcb.png)
Let's look at some of the leading frameworks in this field.
XGBoost: Extreme Gradient Boosting
XGBoost (Extreme Gradient Boosting) is one of the most popular and powerful machine learning algorithms, widely known for its speed, performance, and scalability. It is an implementation of gradient boosting that has been optimized for efficiency, making it one of the go-to choices for solving complex machine learning problems. Let’s explore how this ML algorithm works and what components it uses.
1. Regularization: XGBoost uses L1 and L2 regularization techniques to control model complexity and prevent overfitting.
- L1 regularization (Lasso) adds a penalty proportional to the absolute value of the coefficients, promoting sparsity by driving some coefficients to zero. This helps simplify the model and automatically selects relevant features, especially when irrelevant ones are present.
- L2 regularization (Ridge) adds a penalty proportional to the square of the coefficients, reducing large coefficients and preventing any feature from dominating the model. While it doesn’t set coefficients to zero, it shrinks them, enhancing stability, generalization, and reducing overfitting risk.
Together, these regularization techniques ensure that XGBoost models generalize well to unseen data by controlling complexity and preventing overfitting.
2. Parallelized Learning: Traditional Gradient Boosting algorithms build trees sequentially, with each tree correcting the errors of the previous one. This process can be time-consuming, especially for large datasets. XGBoost addresses this by utilizing parallelized learning, significantly speeding up model training.
- Feature Parallelism: Different features are used in parallel to create splits, accelerating the training process by utilizing multiple cores.
- Data Parallelism: The data is split across CPU cores, allowing different parts of the algorithm to be processed simultaneously, thus speeding up tree-building.
By using parallelization, XGBoost reduces training time and makes it scalable for large datasets and real-time applications.
3. Handling Missing Data: XGBoost stands out for its ability to handle missing data automatically, without the need for manual preprocessing such as imputation, which can introduce bias or inaccuracies.
- Sparsity-Aware Splitting: When a feature has missing values, XGBoost treats them as a separate category and considers them during the split process. This approach allows the model to make optimal decisions even with missing data.
- Learning Missing Patterns: XGBoost automatically learns how missing data behaves by observing how the model performs on the rest of the features, helping it decide whether missing values should go left or right during a split.
- Flexible Handling: The algorithm can assign missing values to either side of the tree split, optimizing model performance without being hindered by gaps in the dataset.
This ability makes XGBoost highly robust, as it can effectively handle imperfect datasets without requiring extra steps, making it ideal for real-world data scenarios.
Use Case: XGBoost is ideal for competitions like Kaggle, where fast execution and model accuracy are paramount. It is often used in fields like finance, healthcare, and marketing to build predictive models with large datasets.
Supercharge your creativity and maximize efficiency with the Generative AI Mastery Certificate for Content Creation. In collaboration with Microsoft, this course offers a Joint Completion Certification from upGrad and Microsoft. Plus, get paid access to Microsoft 365 Copilot for 2 months, worth ₹6000+, absolutely free!
LightGBM: A Scalable Gradient Boosting Model
LightGBM (Light Gradient Boosting Machine) is a high-performance, scalable implementation of Gradient Boosting, designed to address the computational inefficiencies often encountered when working with large datasets. By introducing new techniques for data handling and tree learning, LightGBM significantly improves the speed and memory efficiency of the traditional Gradient Boosting algorithm, making it an excellent choice for large-scale machine learning tasks.
- LightGBM (Light Gradient Boosting Machine) is a high-performance, scalable implementation of Gradient Boosting, designed to improve computational efficiency for large datasets. It introduces innovations like histogram-based learning and leaf-wise tree growth, making it faster and more memory-efficient compared to traditional methods.
- Histogram-based Learning: This technique groups continuous features into discrete bins, reducing memory usage and speeding up the training process, especially with datasets that have many continuous features.
- Leaf-wise Tree Growth: Unlike level-wise growth in traditional algorithms, LightGBM grows the leaf that minimizes loss the most, resulting in deeper trees. This enhances accuracy but may increase overfitting risk if not controlled.
- Efficient Large Dataset Handling: LightGBM leverages data parallelism and feature parallelism to efficiently handle massive datasets with high-dimensional features, making it ideal for industries like finance, e-commerce, and healthcare.
- Use Case: LightGBM is used in real-time applications like fraud detection, where fast prediction times are crucial. Processing large volumes of transaction data quickly helps identify fraudulent activities in real time, minimizing financial losses.
CatBoost: Handling Categorical Features Efficiently
CatBoost (Categorical Boosting) is a machine learning algorithm specifically designed to handle categorical features directly, eliminating the need for complex preprocessing steps like one-hot encoding or label encoding. This makes it a highly efficient and time-saving option for datasets that contain a significant number of categorical variables.
- Categorical Feature Encoding: CatBoost uses a unique and efficient algorithm to encode categorical features, allowing the model to directly handle them without any preprocessing. This reduces the time spent on data preparation and helps prevent information leakage, which can occur when categorical data is improperly processed, leading to overfitting.
- Symmetric Trees: Unlike other Gradient Boosting algorithms, CatBoost constructs symmetric trees where the structure of the tree is balanced, making splits more consistent across all branches. This symmetry helps improve the model's generalization ability, allowing it to perform better on unseen data and reducing the chances of overfitting.
- Robustness to Overfitting: CatBoost's boosting method uses a permutation-driven approach that randomizes the order of data when training, helping to mitigate overfitting. By permuting the data and applying a more robust approach to fitting, CatBoost enhances model accuracy, especially in cases with high-dimensional categorical data.
Use Case: CatBoost is especially beneficial in applications that involve significant categorical features, such as prediction models in healthcare. In healthcare datasets, patient information often includes categorical variables like gender, medical history, and region, which are crucial for accurate predictions. CatBoost efficiently handles these features, making it ideal for tasks like predicting patient outcomes, diagnosing medical conditions, and personalizing treatment plans.
Take your AI skills to the next level with the Fundamentals of Deep Learning and Neural Networks free course. Dive deep into neural networks, model training, and AI applications, and strengthen your understanding with hands-on insights. With 28 hours of learning, you gain expert-led guidance and the chance to earn a free certification.
With these recent innovations and optimizations in GB, the algorithm has become even more powerful and versatile. Now, let’s learn how these advancements are being applied across various domains in ML.
Applications of Gradient Boosting in Machine Learning
Gradient boosting has proven to be a highly effective tool across multiple industries due to its versatility and predictive power. From finance to healthcare, and marketing to e-commerce, organizations are leveraging this technique to enhance their decision-making and improve business outcomes. Let’s explore some key applications of GB in these sectors.
-4826d8f941c34cc79852992ecce87922.png)
Gradient Boosting in Finance
Gradient boosting in machine learning plays an important role in financial services, where accurate predictions and timely interventions are crucial for risk management and profitability. The algorithm’s ability to handle complex data and provide high accuracy makes it ideal for several financial applications.
- Financial Prediction Models: Used to forecast stock prices, market trends, and asset values based on historical data and technical indicators. Example: Hedge funds and financial analysts use GB to predict market behavior and optimize their trading strategies, like JPMorgan Chase, which uses machine learning, including GB, to predict price movements in the stock market.
- Fraud Detection: Helps in detecting fraudulent transactions by analyzing patterns and identifying anomalies in real-time. Example: PayPal uses GB to identify fraudulent transactions by recognizing unusual patterns in purchasing behavior, thereby reducing chargebacks and preventing fraud.
- Risk Analysis: Evaluates the potential risks in lending, insurance, and investment portfolios, enabling better decision-making. Example: Insurance companies like Geico use GB to predict the likelihood of a claim and set premium rates based on risk factors, improving pricing accuracy.
Gradient Boosting in Healthcare
In healthcare, the ability to predict patient outcomes and diagnose conditions accurately can make a significant difference in treatment effectiveness and patient survival rates. GB is increasingly used for predictive modeling in this field.
- Predicting Patient Outcomes: Forecasts patient recovery, disease progression, and hospital readmission rates. Example: Hospitals like the Mayo Clinic use GB to predict which patients are at risk of readmission, helping healthcare providers intervene early and reduce unnecessary hospital stays.
- Medical Diagnosis: Assists in diagnosing diseases such as cancer, heart conditions, and diabetes by analyzing medical images and patient data. Example: In oncology, GB is used to predict the likelihood of cancer recurrence by analyzing patient history, biopsy results, and genetic data, improving early intervention.
- Personalized Treatment: Helps tailor personalized treatment plans based on individual patient characteristics and historical treatment data. Example: Personalized treatment plans for diabetes patients are optimized using GB, which helps predict how individual patients will respond to various medications based on their medical history.
Gradient Boosting in Marketing and E-commerce
In the competitive world of marketing and e-commerce, companies rely on accurate predictions to engage customers, increase sales, and improve retention rates. GB is a valuable tool in predicting customer behavior and streamlining marketing efforts.
- Customer Churn Prediction: GB helps businesses predict customer churn by analyzing behavior patterns, allowing targeted retention strategies. Example: Netflix uses GB to analyze user preferences and viewing habits to reduce subscriber drop-off.
- Sales Forecasting: GB predicts future sales to optimize inventory and sales goals. Example: Walmart uses GB to forecast sales during peak seasons, improving inventory and supply chain management.
- Targeted Marketing Campaigns: GB enables personalized marketing by analyzing customer behavior. Example: Amazon uses GB to recommend personalized products based on past purchases, increasing sales and customer satisfaction.
These real-world applications highlight GB's versatility across industries. This machine learning technique has become a key tool in improving decision-making and operational efficiency in finance, healthcare, marketing, and e-commerce by providing accurate predictions and deep insights.
Also Read: Decision Tree in Machine Learning Explained [With Examples]
To deepen your understanding of the concepts discussed above, it's time to test your knowledge. Below is the quiz to assess your grasp of the material and solidify your learning.
Test Your Knowledge on Gradient Boosting in ML
Test your grasp of Gradient Boosting techniques, their applications, and optimizations with the following multiple-choice questions. This quiz will solidify your understanding and provide insight into areas you may want to explore further.
1. What is the main objective of gradient boosting?
A) Minimize computational complexity
B) Maximize predictive performance by combining weak learners
C) Increase data storage
D) Reduce the number of features
2. What method does gradient boosting in machine learning use to build the final model?
A) Bagging
B) Boosting
C) Random forest
D) K-nearest neighbors
3. Which of the following is a key benefit of using gradient boosting?
A) It works well with large datasets and handles missing values efficiently.
B) It only works for binary classification problems.
C) It eliminates the need for feature engineering.
D) It does not overfit the model even with complex datasets.
4. Which of the following is a commonly used implementation of gradient boosting?
A) XGBoost
B) K-means
D) Naive Bayes
5. What is one of the key optimizations in XGBoost compared to traditional gradient boosting in machine learning?
A) Handling only numeric data
B) Parallelized learning and regularization techniques
C) No need for hyperparameter tuning
D) Only supports binary classification
6. How does LightGBM differ from traditional gradient boosting methods?
A) It uses level-wise tree growth
B) It uses leaf-wise tree growth, optimizing accuracy
C) It only works with small datasets
D) It does not support categorical data
7. What is a unique feature of CatBoost that sets it apart from other gradient boosting frameworks?
A) It handles categorical features efficiently without needing additional preprocessing
B) It only works with image data
C) It only supports regression tasks
D) It eliminates the need for regularization
8. Which of the following is a common application of gradient boosting in finance?
A) Customer sentiment analysis
B) Fraud detection and risk analysis
C) Document classification
D) Image recognition
9. In healthcare, gradient boosting is commonly used for which of the following tasks?
A) Predicting patient outcomes and diagnosing diseases
B) Enhancing the speed of hospital administrative processes
C) Handling patient insurance claims
D) Optimizing hospital room allocation
10. How does gradient boosting help in marketing and e-commerce?
A) By predicting product prices based on user input
B) By predicting customer churn and optimizing marketing strategies
C) By automating customer service chatbots
D) By increasing the speed of website load time
Now that you’ve tested your knowledge on what is gradient boosting in machine learning, you might be wondering how you can further enhance your skills in this area. Let’s explore upGrad’s offerings
How Can upGrad Help with Gradient Boosting in Machine Learning?
What is gradient boosting in machine learning was discovered in this blog, where you learned that it is used to build strong models by iteratively adding weak learners, typically decision trees, to correct the errors of previous models. It uses regularization techniques like L1 and L2 to avoid overfitting and improve generalization, making it suitable for structured data.
One of its strengths is handling missing data effectively, allowing for optimal splits even when some values are missing.
If you're eager to learn more about machine learning and apply powerful techniques like Gradient Boosting in real-world scenarios, then choose upGrad. upGrad courses will equip you with the expertise needed to excel in data science, AI, and machine learning.
Explore these courses below:
- Executive PG Program in Machine Learning and AI
- PG Diploma in Data Science and AI
- Master of Science in Machine Learning & AI
Ready to take your career in machine learning to the next level? upGrad offers personalized one-on-one career counseling to help you choose the right learning path based on your goals and experience. You can also visit any upGrad centre for hands-on training with experienced mentors.
FAQs
1. How can Gradient Boosting be used in fraud detection for financial services?
Gradient Boosting is highly effective in fraud detection by analyzing transaction patterns to identify anomalies and potential fraud. It excels in detecting rare and subtle patterns in vast transaction datasets, focusing on edge cases that might be missed by traditional methods. GBM’s iterative learning process allows it to refine predictions over time, improving accuracy and reducing false positives. This is especially useful for real-time detection, enabling financial institutions to respond quickly and minimize losses from fraudulent activities.
2. What role does XGBoost play in predicting customer churn for e-commerce businesses?
XGBoost is particularly useful for predicting customer churn by analyzing user engagement, purchase behavior, and transaction history. By learning from past interactions, it identifies high-risk customers who are likely to leave, allowing businesses to take proactive retention measures. Its optimization techniques, like regularization and handling imbalanced datasets, help improve predictive accuracy. XGBoost also offers high interpretability, making it easier for businesses to understand the key factors contributing to churn and tailor their strategies accordingly.
3. How does LightGBM improve demand forecasting in retail?
LightGBM improves demand forecasting by efficiently processing large, high-dimensional datasets, making it particularly suited for retail applications. It can predict future sales trends by analyzing customer behavior, historical data, and market dynamics, enabling retailers to optimize inventory levels. By utilizing histogram-based learning and leaf-wise tree growth, LightGBM enhances both the speed and accuracy of predictions. This allows businesses to reduce stockouts, minimize waste, and ensure products are available when customers need them, especially during peak seasons.
4. In what way does CatBoost help healthcare providers predict patient outcomes?
CatBoost is highly effective in healthcare for predicting patient outcomes by analyzing medical history, demographic factors, and treatment data. Its strength lies in efficiently handling categorical data, such as patient gender or medical conditions, which is critical in healthcare datasets. By utilizing gradient boosting with categorical feature optimization, CatBoost can identify at-risk patients for various conditions, such as heart disease or diabetes. This enables healthcare providers to intervene earlier, personalize treatments, and improve patient care outcomes.
5. How can gradient boosting in machine learning be utilized for real-time stock market predictions?
Gradient Boosting is widely used for stock market predictions by analyzing historical data such as stock prices, trading volumes, and economic indicators. Its ability to handle large datasets and correct errors iteratively makes it an ideal tool for forecasting volatile markets. The model learns to make predictions based on complex patterns and trends that evolve over time, improving its forecasts as more data becomes available. This capability allows financial institutions and traders to make more informed decisions and optimize their strategies in real-time.
6. How does XGBoost contribute to credit scoring models in the banking sector?
XGBoost enhances credit scoring models by analyzing a borrower’s financial behavior, transaction history, and external data points. It can detect non-linear patterns in the data that traditional models might overlook, improving the accuracy of creditworthiness assessments. XGBoost’s regularization techniques prevent overfitting and ensure robust performance, even with noisy or incomplete data. This helps financial institutions assess risk more effectively, reduce defaults, and streamline loan approval processes.
7. What advantages does LightGBM offer in real-time product recommendation systems?
LightGBM is ideal for real-time product recommendation systems due to its high speed and efficiency in processing large datasets. By analyzing user interactions, purchase history, and preferences, LightGBM can generate highly personalized recommendations in real time. Its histogram-based learning and leaf-wise tree growth reduce computation time while maintaining accuracy, even with millions of users and products. This capability improves user experience by providing relevant product suggestions, increasing sales and engagement on e-commerce platforms.
8. How does CatBoost handle large datasets in customer segmentation for marketing?
CatBoost excels in customer segmentation by efficiently processing large, high-dimensional datasets, particularly those with a mix of categorical and numerical features. It can analyze customer behaviors, such as spending patterns or demographics, and identify distinct segments for targeted marketing. By optimizing categorical data handling, CatBoost ensures that segmentation is both accurate and computationally efficient. This allows businesses to design more personalized marketing campaigns, increasing customer engagement and improving retention rates.
9. How can gradient boosting be used in energy consumption forecasting?
Gradient boosting can be used to forecast energy consumption by analyzing historical usage patterns, weather conditions, and demographic data. By learning from these factors, it can identify trends and fluctuations in energy demand, allowing utilities to optimize energy distribution. GBM’s ability to handle complex, non-linear relationships in the data ensures accurate predictions even in dynamic environments. This helps reduce energy waste, improve cost efficiency, and ensure adequate energy supply, particularly during peak usage periods.
10. How does XGBoost improve disease prediction models in healthcare?
XGBoost improves disease prediction models by analyzing diverse patient data, such as medical records, genetic information, and test results. It excels at handling large, high-dimensional datasets, enabling healthcare providers to predict the likelihood of diseases like cancer or diabetes. Its optimization techniques, including regularization and tree pruning, help avoid overfitting, ensuring reliable predictions. By leveraging XGBoost, healthcare providers can detect diseases early, leading to more effective treatment plans and improved patient outcomes.
11. How can CatBoost optimize sales forecasting for large-scale retailers?
CatBoost optimizes sales forecasting for large retailers by efficiently processing large datasets with both categorical and numerical features, such as product categories and customer demographics. By leveraging its ability to handle complex feature interactions, CatBoost can accurately predict future sales trends, even in high-variance markets. This helps retailers optimize inventory, manage supply chains, and adjust pricing strategies to maximize profitability. Additionally, CatBoost’s robust performance with minimal hyperparameter tuning makes it an ideal choice for large-scale retailers.





upGrad Learner Support
Talk to our experts. We are available 7 days a week, 10 AM to 7 PM
Indian Nationals
Foreign Nationals
