All courses
Agentic AI
Agentic AI
Artificial Intelligence
Degree / Exec. PG

IIIT Bangalore
Executive Diploma in Machine Learning and AI
OPJ Global University
Master’s Degree in Artificial Intelligence and Data Science
Liverpool John Moores University
Master of Science in Machine Learning & AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIExecutive Certificate

IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
IIIT Bangalore
Executive Programme in Generative AI for Leaders
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceOffline Bootcamps

upGrad
Data Science and AI-MLDoctorate
For All Domains
IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
Swiss School of Business and Management
Global Doctor of Business Administration from SSBM
Edgewood University
Doctorate in Business Administration by Edgewood UniversityGolden Gate University
Doctor of Business Administration From Golden Gate University
Rushford Business School
Doctor of Business Administration from Rushford Business School, SwitzerlandGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)-d9bdeff6165f4eb1ba2adcebde78e961.svg)
University of Waterloo
Chief Technology and AI Officer ProgramLeadership / AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIMachine Learning
Machine Learning
Data Science
Degree / Exec. PG
O.P Jindal Global University
Master’s Degree in Artificial Intelligence and Data ScienceIIIT Bangalore
Executive Diploma in Data Science & AILiverpool John Moores University
Master of Science in Data ScienceExecutive Certificate
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceupGrad | Microsoft
Gen AI Mastery Certificate for Content CreationOffline Bootcamps
upGrad
Data Science and AI-MLupGrad
Data AnalyticsMBA
Masters

Paris School of Business
Master of Science in Business Management and TechnologyO.P.Jindal Global University
MBA (with Career Acceleration Program by upGrad)Edgewood University
MBA from Edgewood UniversityO.P.Jindal Global University
MBA from O.P.Jindal Global UniversityGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)Executive Certificate

IMT, Ghaziabad
Advanced General Management ProgramMarketing
Executive Certificate
Offline Bootcamps
upGrad
Digital MarketingManagement
Degree
O.P Jindal Global University
MSc in International Accounting & Finance (ACCA integrated)Paris School of Business
Master of Science in Business Management and Technology
Golden Gate University
Master of Arts in Industrial-Organizational PsychologyExecutive Certificate

IIM Kozhikode
Human Resource Analytics Course from IIM-KupGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftEducation
Education

Northeastern University
Master of Education (M.Ed.) from Northeastern UniversityEdgewood University
Doctor of Education (Ed.D.)Edgewood University
Master of Education (M.Ed.) from Edgewood UniversityCertifications
Project Management
Certification

Knowledgehut
Leadership And Communications In ProjectsKnowledgehut
Microsoft Project 2007/2010-ae8d039bbd2a41318308f8d26b52ac8f.svg)
Knowledgehut
Financial Management For Project ManagersKnowledgehut
Fundamentals of Earned Value Management (EVM)Knowledgehut
Fundamentals of Portfolio ManagementKnowledgehut
Fundamentals of Program Management-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
Knowledgehut
CAPM® CertificationsKnowledgehut
Microsoft® Project 2016Certifications & Trainings
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)
Knowledgehut
PMP® CertificationKnowledgehut
PMI-RMP® CertificationKnowledgehut
PMP Renewal Learning PathKnowledgehut
Oracle Primavera P6 V18.8Knowledgehut
Microsoft® Project 2013Knowledgehut
PfMP® Certification CourseKnowledgehut
Project Planning and MonitoringPrince2 Certifications

Knowledgehut
PRINCE2® FoundationKnowledgehut
PRINCE2® PractitionerKnowledgehut
PRINCE2 Agile Foundation and PractitionerKnowledgehut
PRINCE2 Agile® Foundation CertificationKnowledgehut
PRINCE2 Agile® Practitioner CertificationManagement Certifications
Knowledgehut
Project Management Masters Certification ProgramKnowledgehut
Change ManagementKnowledgehut
Project Management TechniquesKnowledgehut
Product Management Certification ProgramKnowledgehut
Project Risk Management- Study abroad
- Offline centres
- uGSOT - B.Tech
More



49. Variance in ML
12 Issues in Machine Learning: Key Problems in Training, Testing, and Deployment
Did you know? A recent report revealed that 44% of organizations faced challenges with AI model transparency, reinforcing the need for explainable models to ensure accountability and trust. Furthermore, 15% of organizations reported facing deployment hurdles like monitoring and observability, signaling a pressing need for robust MLOps frameworks.
Machine learning models often fail due to compounding issues across the pipeline. In training, noisy or biased data leads to inaccurate learning. During testing, weak validation and limited test coverage hide real-world errors. In deployment, lack of monitoring, model drift, and poor explainability reduce performance over time.
These challenges affect prediction accuracy, fairness, and system reliability. Identifying and addressing issues at each stage is essential to build machine learning models that are stable, trustworthy, and production-ready.
In this blog, we'll explore 12 specific machine learning problems that practitioners commonly face, highlighting key challenges of machine learning and practical solutions.
Upskill your career with upGrad's AI and ML courses. With over 1,000 partner companies and an average salary hike of 51%, these online programs are designed to take your career to the next level.
Understanding the Core Issues in Machine Learning Model Development
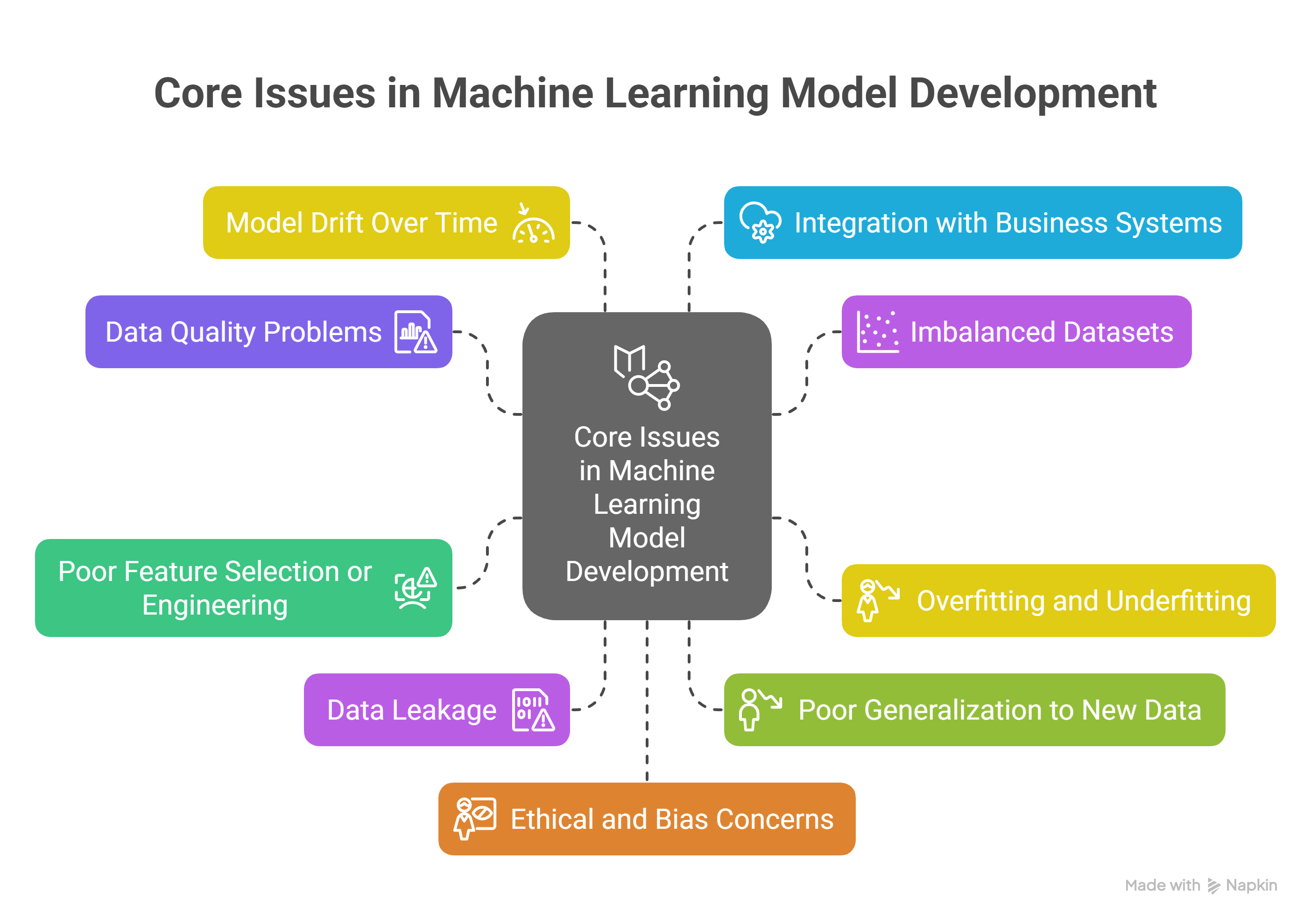
Developing a robust machine learning model requires understanding and addressing the common challenges encountered throughout the model lifecycle. Below are the four primary issues in machine learning often faced during model development, along with practical solutions to overcome them.
1. Data Quality Problems
Challenges of machine learning often start with poor data quality. Incomplete, inconsistent, or noisy data can significantly affect model training and performance. It's critical to address these issues in machine learning early to ensure that the model learns effectively from the dataset and avoids common machine learning problems that arise from data issues.
- Impact on Model Training: Poor data quality leads to the model learning from irrelevant or misleading information, reducing its ability to generalize to unseen data.
- Preprocessing Importance: Data preprocessing techniques like imputation, outlier removal, and noise reduction are essential to prepare the data for optimal model training.
- Data Cleaning: Proper data cleaning techniques improve the dataset's accuracy and enhance the model's interpretability and stability over time.
Solution: Data cleaning is essential for improving the quality of your dataset. Techniques such as imputation for missing values, removing duplicates, and identifying and eliminating outliers are critical steps. Moreover, noise reduction through smoothing or transformation can help make the data more suitable for training.
Example: In machine learning for healthcare predictions, missing values or inconsistencies in patient records can harm the model’s accuracy. Imputing missing data or eliminating rows with excessive missing data ensures the model receives reliable inputs, improving overall performance. This step is crucial for avoiding issues in machine learning related to data quality and model reliability.
If you're ready to boost your expertise and dive into advanced AI and ML techniques, explore these top-rated courses designed to help you master cutting-edge concepts:
- Master's in Artificial Intelligence and Machine Learning
- Executive Diploma in Machine Learning and AI
- Executive Post Graduate Certificate Programme in Data Science & AI
2. Imbalanced Datasets
Imbalanced datasets occur when one class dominates the dataset, leading to biased predictions. This is a major challenge in machine learning, especially in classification tasks, where the model may develop a bias toward the majority class and ignore the minority class. This results in a model that cannot be generalized well, especially when deployed in real-world, imbalanced data.
- Impact on Classification Accuracy: When the data is imbalanced, the model predicts the majority class more frequently, resulting in poor performance for the minority class. This makes it difficult for the model to identify and correctly predict the rare, yet important, outcomes.
- Model Bias: The model may achieve high accuracy by simply predicting the majority class, but this does not reflect true predictive power or generalization. As a result, the model's effectiveness is undermined, especially in critical use cases like fraud detection or disease prediction.
Solution: Use techniques like oversampling, undersampling, or synthetic data generation to balance the dataset. Alternatively, apply algorithm-level methods like cost-sensitive learning to mitigate bias in machine learning challenges. Also, consider evaluating models using metrics like F1-score or AUC to better assess performance on imbalanced datasets.
Example: In a fraud detection model, where fraudulent transactions are only 1% of the data, the model may bias predictions towards the majority class (legitimate transactions). Using techniques like SMOTE (oversampling) or undersampling can balance the dataset, improving the model’s ability to detect fraudulent transactions accurately.
Also read: 17 AI Challenges in 2025: How to Overcome Artificial Intelligence Concerns?
3. Overfitting and Underfitting
Overfitting occurs when the model memorizes the training data, including noise and outliers, instead of generalizing. This leads to high accuracy on the training data but poor performance on new, unseen data. Overfitting often happens with complex models or excessive training.
Underfitting occurs when the model is too simple to capture the underlying patterns in the data. It fails to perform well on the training and test data, resulting in low accuracy. Underfitting typically happens when the model lacks complexity or isn't trained enough.
- Solution: To combat overfitting, methods like cross-validation, early stopping, and regularization (L1/L2) can be used. For machine learning problems, more complex models or additional features can be used to avoid underfitting.
- Example: In machine learning for image classification, a neural network might overfit by memorizing details, which can be prevented by using dropout layers. On the other hand, underfitting can be solved by adding more layers or epochs to improve accuracy.
If you're eager to master neural networks and AI models, upGrad's Fundamentals of Deep Learning and Neural Networks course is ideal. In just 28 hours, you'll dive into key concepts such as perceptrons, neuron functioning, and deep learning architecture. Plus, earn a signed, verifiable e-certificate from upGrad to showcase your skills.
Also read: What is Overfitting & Underfitting In Machine Learning? [Everything You Need to Learn]
4. Poor Feature Selection or Engineering
In machine learning, irrelevant or redundant features can confuse the model, leading to suboptimal performance. Proper feature selection and engineering are critical for improving model performance, as they directly influence the quality of input data used in training.
- Impact of Irrelevant Features: Including unnecessary features can introduce noise into the model, slowing training and potentially lowering accuracy.
- Feature Engineering: Effective feature engineering can help extract meaningful information from the data, improving the model's ability to recognize important patterns.
Solution: Carefully evaluate and select relevant features using Recursive Feature Elimination (RFE) or feature importance ranking methods. Conducting thorough feature engineering can dramatically enhance the model's performance and interpretability in addressing common machine learning challenges.
Example: In a customer churn prediction model, irrelevant features like a customer’s favourite colour can confuse the model and harm predictions. Using RFE or feature importance ranking helps select key features like usage patterns or service complaints, boosting accuracy and performance.
5. Data Leakage
Data leakage occurs when information from outside the training dataset is inadvertently included in the model's training process. This problem can significantly distort model performance, leading to overly optimistic test results. Data leakage usually arises from improper data splits or including future information in training features, which would not be available during real-world predictions.
- Consequences of Data Leakage: Data leakage distorts the model evaluation, causing it to perform better than it would in actual deployment, ultimately undermining its reliability and fairness.
- Common Causes of Leakage: Leakage often occurs due to inappropriate data preprocessing or improper training and testing data splitting, resulting in unrealistic evaluation metrics.
Solution: To prevent data leakage, ensure that all features used for training are based only on past data, avoiding any future information. Additionally, robust cross-validation methods such as k-fold cross-validation should be implemented to ensure there is no overlap between the training and testing datasets.
Example: In a loan approval model, including the target variable (loan status) as a feature during training would lead to data leakage. The model would "learn" from the target, making it unrealistically accurate.
Also read: How to Perform Cross-Validation in Machine Learning?
6. Poor Generalization to New Data
A key machine learning problem arises when a model performs well on test data but fails to generalize to real-world scenarios. This issue is often caused by overfitting or a narrow training distribution, leading to a model that memorizes the training data but struggles when exposed to unseen data.
- Impact of Overfitting: When overfitting occurs, the model memorizes the training data, achieving high accuracy on training and test sets but performing poorly on new data, leading to poor generalization.
- Training Distribution Issues: If the training dataset is not diverse enough, the model will have difficulty generalizing to new, out-of-sample data.
Solution: Regularization techniques (such as L2 regularization), data augmentation, and cross-validation should be used to improve generalization. Ensuring a more diverse training dataset will also enhance model generalization to a wider variety of real-world data.
Example: Consider an image classification model trained to recognise handwritten digits using a dataset with centered and upright images. If the model is tested on rotated or slightly zoomed versions of the same digits, variations it never saw during training, it may fail to classify them correctly.
Also read: Regularization in Machine Learning: How to Avoid Overfitting?
7. Model Drift Over Time
Model drift occurs when real-world data evolves, but the assumptions of a machine learning model remain unchanged, causing its accuracy to degrade post-deployment. This challenge is significant for applications where data continuously changes, such as fraud detection or customer behavior prediction.
- Data Changes Over Time: Real-world data patterns evolve, and if the model is not regularly updated, its accuracy can diminish as it fails to account for these new trends.
- Impact on Model Performance: Failure to address model drift can cause predictive models to become unreliable, leading to poor decision-making, particularly in dynamic industries.
Solution: Implement periodic retraining schedules using updated data to manage model drift. Monitoring the model’s performance through feedback loops and utilizing online learning techniques can help adapt it to evolving trends, improving its ability to predict accurately over time.
Example: In email spam detection, covariate drift occurs when the distribution of words or sender patterns changes over time, like spammers using new obfuscation tactics. Concept drift happens when the definition of "spam" evolves, such as during a pandemic when promotional emails about masks or remote tools shift from spam to relevant content.
Also Read: Top 5 Machine Learning Models Explained For Beginners
8. Integration with Business Systems
One of the main challenges of machine learning is integrating models into existing business systems. Machine learning models should seamlessly integrate with IT pipelines to deliver actionable insights. Often, there is a mismatch between model output and operational processes, making the integration challenging and sometimes inefficient.
- Alignment with Business Goals: The model’s predictions must align with the business strategy and operational logic to ensure relevant and impactful decisions.
- Operational Challenges: Deployment challenges often arise when models cannot integrate smoothly with existing software infrastructure, causing delays or failure to align with business timelines.
Solution: Collaborate with IT teams to design flexible models that can be integrated with current business systems. Utilize APIs, model management tools, and cloud platforms like AWS or Azure to streamline deployment and ensure models align with operational processes.
Example: A customer churn prediction model feeds its output into a CRM system to trigger retention offers. However, due to API latency or mismatched data formats between the model and CRM, the predictions arrive late or are unusable, causing a poor customer experience.
Also Read: Neural Network Model: Brief Introduction, Glossary & Backpropagation
9. Ethical and Bias Concerns
Machine learning models can replicate or amplify existing societal biases in their training data, leading to unfair or discriminatory outcomes. This issue, known as algorithmic bias, is particularly critical in high-stakes domains such as hiring, lending, or criminal justice, where skewed predictions can reinforce inequality.
- Impact of Bias on Fairness: Algorithmic bias undermines fairness by producing outcomes that systematically disadvantage certain groups. Fairness metrics, such as disparate impact, are used to quantify whether decisions disproportionately affect protected categories (e.g., race, gender) compared to others.
- Sources of Bias in Data: Bias often stems from unbalanced datasets, historical discrimination encoded in training labels, or feature choices that correlate with sensitive attributes. These flaws skew model predictions and decision-making processes.
Solution: To reduce bias, it’s essential to use diverse and representative datasets, apply bias detection tools, and adopt fairness-aware algorithms. Techniques like re-weighting samples, adversarial debiasing, or applying fairness constraints during training can improve equity across demographic groups.
Example: The COMPAS algorithm used in US criminal justice systems was found to overpredict recidivism risk for Black defendants compared to white defendants. Similarly, due to historical hiring patterns in the data, some resume screening tools have prioritised male candidates over equally qualified female applicants.
As you tackle machine learning challenges, gaining the right skills is crucial. The Executive Diploma in Machine Learning and AI with IIIT-B covers key areas like Deep Learning, Gen AI, and MLOps. In just 11 months, you'll gain the expertise to address real-world challenges and align ML models with business goals.
Also Read: AI Ethics: Ensuring Responsible Innovation for a Better Tomorrow
Challenges of Machine Learning During Model Training
Before a model can deliver accurate predictions, it must be trained, and that’s where many problems begin. Training machine learning models involves challenges like long training times, high costs, sensitivity to hyperparameters, and limited interpretability. Overcoming these issues in machine learning is key to model success.
10. Long Training Times and High Computation Costs
Training deep models, especially on large datasets, can be computationally expensive and time-consuming. Training time and associated costs can become a significant concern as models become complex. Training models can take hours or even days for large-scale tasks like image or natural language processing (NLP), depending on the computational power available.
- Scalability Implications: Long training times can limit scalability, especially when deploying models in real-time systems.
- Cost Management: High computation costs, especially with cloud-based resources, can strain budgets, particularly for startups or small enterprises.
Solution: To manage long training times and high costs, techniques like model parallelism, gradient accumulation, and transfer learning can help reduce training time. Additionally, cloud services with GPU support can speed up the process, ensuring models can be trained more efficiently. Consider tuning hyperparameters or simplifying models to balance performance and training time.
Example: In image recognition tasks, training deep convolutional neural networks (CNNs) on a dataset of millions of high-resolution images can take days, especially when using CPUs instead of GPUs.
If you want to deepen your knowledge of machine learning models and their real-world applications, upGrad's Master's in AI and Machine Learning is the ideal choice. Over 17 months, you'll gain hands-on experience, mentorship from industry experts, and a dual accreditation from LJMU (UK) and IIIT Bangalore (India), opening doors to exciting career opportunities.
Also Read: Top 29 Image Processing Projects in 2025 For All Levels + Source Code
11. Sensitivity to Hyperparameters
Machine learning models are susceptible to hyperparameters such as learning rate, batch size, and number of epochs. A small change in these hyperparameters can significantly affect training stability and overall model performance. For example, a higher learning rate might cause the model to overshoot the optimal solution, while a smaller learning rate may lead to slow convergence.
- Impact on Stability: Small changes in hyperparameters can result in unstable training, where the model either fails to converge or converges too slowly.
- Hyperparameter Tuning Complexity: Tuning hyperparameters to find the optimal configuration is often time-consuming and can be complex for large models.
Solution: To mitigate these challenges, methods like grid search, random search, or Bayesian optimization can be used to find the optimal hyperparameters. Additionally, using learning rate schedules, where the learning rate decreases during training, can help improve convergence stability.
Example: In a CNN trained for image classification with SGD, a learning rate 0.1 can cause overshooting and divergence, while 0.0001 may lead to slow convergence or undertraining. Choosing the right learning rate ensures stable and efficient model training.
Also Read: Deep Learning vs Neural Networks: What’s the Difference?
12. Lack of Interpretability in Complex Models
Deep learning models and ensemble methods like Random Forest or Gradient Boosting Machines often deliver high accuracy but are criticised for being “black boxes”; their internal logic is difficult to understand. This creates challenges in finance or healthcare, where transparency is essential for compliance and trust.
- Interpretability vs. Explainability: Interpretability refers to how well a human can understand the internal mechanics of a model (e.g., decision trees), while explainability relates to clarifying the outputs of complex, often opaque models (e.g., neural networks or ensemble models).
- Implications for Trust and Compliance: Regulatory environments often require that decisions made by AI, such as loan approvals or medical diagnoses, can be justified. Model adoption can be stalled by legal or ethical concerns without clear explanations.
Solution:
Techniques like SHAP (Shapley Additive Explanations) and LIME (Local Interpretable Model-agnostic Explanations) are used to address this. These tools break down predictions to show how much each feature contributed.
Example:
A Gradient Boosting Machine predicting loan approvals may lack transparency, but using SHAP can reveal that "age" contributed +0.3 and "low income" -0.5 to a loan rejection decision. In contrast, a decision tree provides inherent interpretability, allowing you to trace the path from input to output.
Boost your career with upGrad’s Executive Post Graduate Certificate in Data Science & AI. In 6 months, master Python, deep learning, and AI with hands-on projects. Offered by IIIT Bangalore, this course equips you with job-ready skills, plus 1 month of Microsoft Copilot Pro to support your learning.
Also read: Random Forest Algorithm: When to Use & How to Use? [With Pros & Cons]
Addressing problems early ensures smoother training, deployment, and performance. Explore why early detection is key to building reliable machine learning models.
Why It's Important to Identify Issues in Machine Learning Early?
-b266b6132af8489fbd5dcb8eec9fabeb.png)
Identifying issues in machine learning early in the process is essential to avoid costly mistakes and inefficiencies that can arise later. Addressing potential challenges early on not only saves time and resources but also leads to better, more reliable models.
1. Reduces Technical Debt and Rework
Catching issues in machine learning during the data preparation or model design stages prevents the need for rework in later phases of development. This reduces technical debt, ensuring that models are optimized from the start.
- Example: Identifying and fixing feature selection issues early prevents the need for major re-engineering during deployment or in production environments. Addressing machine learning problems at this stage ensures smoother model testing and deployment transitions.
2. Improves Model Reliability and Business Adoption
Stable and interpretable models are more likely to be trusted by stakeholders and adopted by businesses. Early identification of problems reduces the chance of errors later, speeding up deployment and improving overall performance.
- Example: A model with fewer bugs and more precise explanations of its decision-making process leads to faster adoption in industries like healthcare, where trust is critical. This ensures that your machine learning models align well with business goals and are trusted for real-world applications.
3. Aligns Model Behavior with Compliance Requirements
Identifying issues in machine learning, like bias or lack of explainability, early helps ensure that the model complies with legal, ethical, and industry regulations. This also supports documentation and audit processes, reducing legal risks.
- Example: Performing early bias checks ensures that the model does not inadvertently discriminate against certain groups, which can help avoid lawsuits or regulatory scrutiny. By addressing challenges of machine learning early, you mitigate risks associated with fairness and ethical considerations.
Take your skills to the next level with upGrad's Job-Linked Data Science Advanced Bootcamp. With 11 live projects and mastery of 17+ industry tools, this program provides hands-on experience and certifications from Microsoft, NSDC, and Uber, helping you build a strong AI and machine learning portfolio.
Also Read: The Ultimate Guide to Deep Learning Models in 2025: Types, Uses, and Beyond
Now, let's explore how upGrad can help you build expertise and tackle these challenges with practical, expert-led programs that offer real-world experience in machine learning.
How Can upGrad Help You Become an Expert in Machine Learning?
Machine learning projects often fail due to overlooked issues during training, testing, and deployment—such as poor data quality, class imbalance, weak validation, and post-deployment drift. These challenges reduce model accuracy, fairness, and reliability. Solving them requires more than theoretical knowledge; it calls for practical, hands-on experience. Understanding real-world implications is key to building robust, scalable ML systems.
Many professionals struggle to apply ML concepts effectively, especially when facing problems like overfitting, missing data, or lack of model transparency. upGrad’s expert-led programs address this gap with practical projects, industry case studies, and personalized mentorship. Learners gain the skills to identify and fix core issues at every stage of the ML lifecycle.
Explore top courses to elevate your skills and career:
Additionally, enhance your learning with these free courses:
Unsure which program fits your background or career goals?
For personalized career guidance, upGrad offers one-on-one counseling to help you identify the right learning path based on your experience and aspirations. You can also visit your nearest upGrad centre to begin hands-on training with expert mentors.
Similar Reads:
- Deep Learning Tutorial: Master AI & Neural Networks
- Artificial Intelligence Tutorial
- Machine Learning Tutorials
- Cost Function In Machine Learning
- Top 10 Machine Learning Applications in 2025 and the Role of Edge Computing
- Image Annotation in Machine Learning
FAQs
1. How can reinforcement learning be applied to real-world problems?
Reinforcement learning (RL) is crucial in systems requiring continuous, adaptive decision-making. In robotics, RL enables machines to learn precise control strategies by interacting with physical environments, improving over time. Self-driving cars use RL to optimize driving behavior under dynamic traffic conditions. In recommendation systems, RL adapts to user preferences by learning which actions (suggestions) yield the highest engagement. In finance, RL helps automate trading strategies that balance long-term gains and risk. Its trial-and-error learning mechanism makes RL ideal for optimizing decisions in uncertain and evolving scenarios.
2. Why is data preprocessing crucial in machine learning?
Data preprocessing directly impacts the reliability and effectiveness of ML models. In healthcare, raw patient data often contains missing values, inconsistent entries, or noise due to manual entry—preprocessing ensures only meaningful signals are used for diagnosis models. In fraud detection, inconsistent transaction data can mislead models unless normalized and cleaned. Proper handling of missing values, categorical encoding, and feature scaling enables better pattern recognition. Without these steps, models may misinterpret data, resulting in inaccurate predictions or biased outcomes, especially in high-stakes applications like credit scoring or medical diagnostics.
3. What role does unsupervised learning play in machine learning?
Unsupervised learning is key in scenarios where labeled data is unavailable or costly. In cybersecurity, clustering algorithms group network activity to detect unusual patterns indicative of threats. Retailers use it for customer segmentation, grouping buyers by purchase behavior to tailor marketing strategies. In manufacturing, unsupervised learning identifies anomalies in sensor data, allowing predictive maintenance before failures occur. It also aids document classification and image compression by discovering hidden structures in data. By revealing patterns without human supervision, it supports intelligent decision-making across diverse domains.
4. What is transfer learning, and how does it help with machine learning challenges?
Transfer learning enables reuse of pre-trained models on related tasks, significantly reducing training time and data requirements. In computer vision, a model trained on ImageNet can be fine-tuned to detect plant diseases or medical anomalies in x-rays. In NLP, large language models pre-trained on massive corpora are adapted for tasks like sentiment analysis or chatbots. This method is valuable where data collection is expensive—such as rare disease detection—allowing smaller datasets to benefit from broader knowledge. Transfer learning improves accuracy, speeds deployment, and democratizes access to high-performing models in resource-constrained settings.
5. How can I ensure the fairness of my machine learning models?
Ensuring fairness involves addressing bias throughout the ML lifecycle. In hiring platforms, biased training data may lead to discriminatory outcomes if not audited. Fairness techniques—like re-weighting or modifying the loss function—help reduce disparities across groups. In lending, fairness constraints can prevent models from penalizing applicants based on geography or income proxies. Regular audits using fairness metrics like disparate impact or equal opportunity help detect issues. Representative datasets and domain-specific fairness checks are essential to uphold legal compliance and public trust in high-impact systems like credit scoring or insurance underwriting.
6. How do ensemble models improve machine learning accuracy?
Ensemble models combine predictions from multiple learners to improve generalization. In medical diagnosis, combining multiple models (e.g., decision trees, logistic regression, neural networks) reduces false positives and negatives, increasing diagnostic accuracy. In credit scoring, Random Forest ensembles provide robust predictions by averaging multiple trees, minimizing the impact of overfitting. In e-commerce, boosting methods improve recommendation accuracy by focusing on previously misclassified instances. By leveraging diverse model perspectives, ensemble methods reduce variance and bias, making them ideal for high-stakes or complex tasks where single models may falter.
7. How do hyperparameters affect machine learning model training?
Hyperparameters govern how a model learns and generalizes. In image classification using deep learning, tuning learning rate or dropout affects training stability and final accuracy. In fraud detection with gradient boosting, tree depth and learning rate determine model complexity and detection power. Poor hyperparameter choices may cause overfitting (too complex) or underfitting (too simplistic). Optimizing these through grid search or Bayesian methods ensures the model performs well across validation sets. In production, automated hyperparameter tuning pipelines reduce manual tuning while improving performance and consistency.
8. What’s the role of model retraining in addressing model drift over time?
Retraining combats performance decay caused by evolving data patterns. In e-commerce, customer preferences shift rapidly—models predicting purchases must retrain frequently to reflect new trends. In fraud detection, scammers adapt tactics, requiring updated models to maintain detection accuracy. Retraining with fresh data ensures relevance, especially when concept drift changes the relationship between input features and target outcomes. Without it, even well-performing models can degrade silently. Scheduled retraining, combined with drift detection systems, ensures that machine learning systems remain effective in fast-changing environments.
9. What are the risks of using synthetic data in machine learning models?
Synthetic data helps balance datasets or protect privacy but can introduce risk if poorly generated. In medical imaging, synthetic MRIs may lack clinical realism, misleading diagnostic models. In credit scoring, synthetic financial profiles may not capture true behavioral diversity, reducing model robustness. If the synthetic data reflects biases from the original data, it may amplify unfairness. Moreover, models trained primarily on synthetic data may perform well in testing but fail in real-world applications. Synthetic data must be carefully validated against real-world distributions to avoid these pitfalls.
10. How do I choose the right evaluation metric for my machine learning task?
The ideal metric depends on your task and what matters most. In disease screening, recall is critical—missing a positive case has high consequences. In spam detection, precision is prioritized to avoid blocking legitimate messages. For imbalanced datasets like fraud detection, F1-score or AUC-ROC provide better insights than accuracy. In recommendation systems, ranking metrics like NDCG are more relevant. Choosing the wrong metric can lead to misleading conclusions, so align the metric with both the data distribution and the real-world impact of model errors.
11. What’s the difference between concept drift and data drift in machine learning?
Data drift occurs when the distribution of input features changes—such as user behavior shifting after a UI redesign. Concept drift happens when the relationship between inputs and outputs changes—e.g., spam words evolving over time, affecting email classifiers. In both cases, model predictions degrade if not addressed. In online banking, drift detection helps update fraud models as patterns shift. Monitoring statistical metrics and retraining models ensures they stay relevant. Concept drift is harder to detect and often requires performance monitoring alongside data distribution tracking.





upGrad Learner Support
Talk to our experts. We are available 7 days a week, 10 AM to 7 PM
Indian Nationals
Foreign Nationals
Disclaimer
The above statistics depend on various factors and individual results may vary. Past performance is no guarantee of future results.
The student assumes full responsibility for all expenses associated with visas, travel, & related costs. upGrad does not .