All courses
Agentic AI
Agentic AI
Artificial Intelligence
Degree / Exec. PG

IIIT Bangalore
Executive Diploma in Machine Learning and AI
OPJ Global University
Master’s Degree in Artificial Intelligence and Data Science
Liverpool John Moores University
Master of Science in Machine Learning & AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIExecutive Certificate

IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
IIIT Bangalore
Executive Programme in Generative AI for Leaders
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceOffline Bootcamps

upGrad
Data Science and AI-MLDoctorate
For All Domains
IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
Swiss School of Business and Management
Global Doctor of Business Administration from SSBM
Edgewood University
Doctorate in Business Administration by Edgewood UniversityGolden Gate University
Doctor of Business Administration From Golden Gate University
Rushford Business School
Doctor of Business Administration from Rushford Business School, SwitzerlandGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)-d9bdeff6165f4eb1ba2adcebde78e961.svg)
University of Waterloo
Chief Technology and AI Officer ProgramLeadership / AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIMachine Learning
Machine Learning
Data Science
Degree / Exec. PG
O.P Jindal Global University
Master’s Degree in Artificial Intelligence and Data ScienceIIIT Bangalore
Executive Diploma in Data Science & AILiverpool John Moores University
Master of Science in Data ScienceExecutive Certificate
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceupGrad | Microsoft
Gen AI Mastery Certificate for Content CreationOffline Bootcamps
upGrad
Data Science and AI-MLupGrad
Data AnalyticsMBA
Masters

Paris School of Business
Master of Science in Business Management and TechnologyO.P.Jindal Global University
MBA (with Career Acceleration Program by upGrad)Edgewood University
MBA from Edgewood UniversityO.P.Jindal Global University
MBA from O.P.Jindal Global UniversityGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)Executive Certificate

IMT, Ghaziabad
Advanced General Management ProgramMarketing
Executive Certificate
Offline Bootcamps
upGrad
Digital MarketingManagement
Degree
O.P Jindal Global University
MSc in International Accounting & Finance (ACCA integrated)Paris School of Business
Master of Science in Business Management and Technology
Golden Gate University
Master of Arts in Industrial-Organizational PsychologyExecutive Certificate

IIM Kozhikode
Human Resource Analytics Course from IIM-KupGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftEducation
Education

Northeastern University
Master of Education (M.Ed.) from Northeastern UniversityEdgewood University
Doctor of Education (Ed.D.)Edgewood University
Master of Education (M.Ed.) from Edgewood UniversityCertifications
Project Management
Certification

Knowledgehut
Leadership And Communications In ProjectsKnowledgehut
Microsoft Project 2007/2010-ae8d039bbd2a41318308f8d26b52ac8f.svg)
Knowledgehut
Financial Management For Project ManagersKnowledgehut
Fundamentals of Earned Value Management (EVM)Knowledgehut
Fundamentals of Portfolio ManagementKnowledgehut
Fundamentals of Program Management-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
Knowledgehut
CAPM® CertificationsKnowledgehut
Microsoft® Project 2016Certifications & Trainings
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)
Knowledgehut
PMP® CertificationKnowledgehut
PMI-RMP® CertificationKnowledgehut
PMP Renewal Learning PathKnowledgehut
Oracle Primavera P6 V18.8Knowledgehut
Microsoft® Project 2013Knowledgehut
PfMP® Certification CourseKnowledgehut
Project Planning and MonitoringPrince2 Certifications

Knowledgehut
PRINCE2® FoundationKnowledgehut
PRINCE2® PractitionerKnowledgehut
PRINCE2 Agile Foundation and PractitionerKnowledgehut
PRINCE2 Agile® Foundation CertificationKnowledgehut
PRINCE2 Agile® Practitioner CertificationManagement Certifications
Knowledgehut
Project Management Masters Certification ProgramKnowledgehut
Change ManagementKnowledgehut
Project Management TechniquesKnowledgehut
Product Management Certification ProgramKnowledgehut
Project Risk Management- Study abroad
- Offline centres
- uGSOT - B.Tech
More



49. Variance in ML
Categories of Machine Learning: What Classes of Problems Do They Solve?
Did you know? Frank Rosenblatt's 1958 perceptron marked the birth of supervised learning neural networks, revolutionizing visual pattern recognition. Meanwhile, unsupervised learning algorithms work like digital Isaac Newtons—quietly observing unlabeled data until patterns emerge naturally, finding hidden structures and relationships without human guidance, just as Newton discovered gravity while contemplating falling apples!
Categories of machine learning refer to the different classes or types of problems that algorithms can solve, such as supervised learning, unsupervised learning, and reinforcement learning.
Understanding these categories is essential, as the choice of category determines the type of algorithm and approach you should use for a given problem.
In this guide, you'll explore the main categories of machine learning, how they differ, and when to apply each one, ensuring that you can select the right approach for your projects to achieve optimal results.
Improve your understanding of different machine learning categories with our online AI and ML courses. Learn how to choose ML categories effectively for your specific problems!
What are the Different Categories of Machine Learning? A Simple Guide
The categories of machine learning are tailored to tackle specific problems based on the nature of the data and the goal of the analysis. Understanding these categories not only helps in choosing the right approach for a problem but also in optimizing the performance of machine learning models.
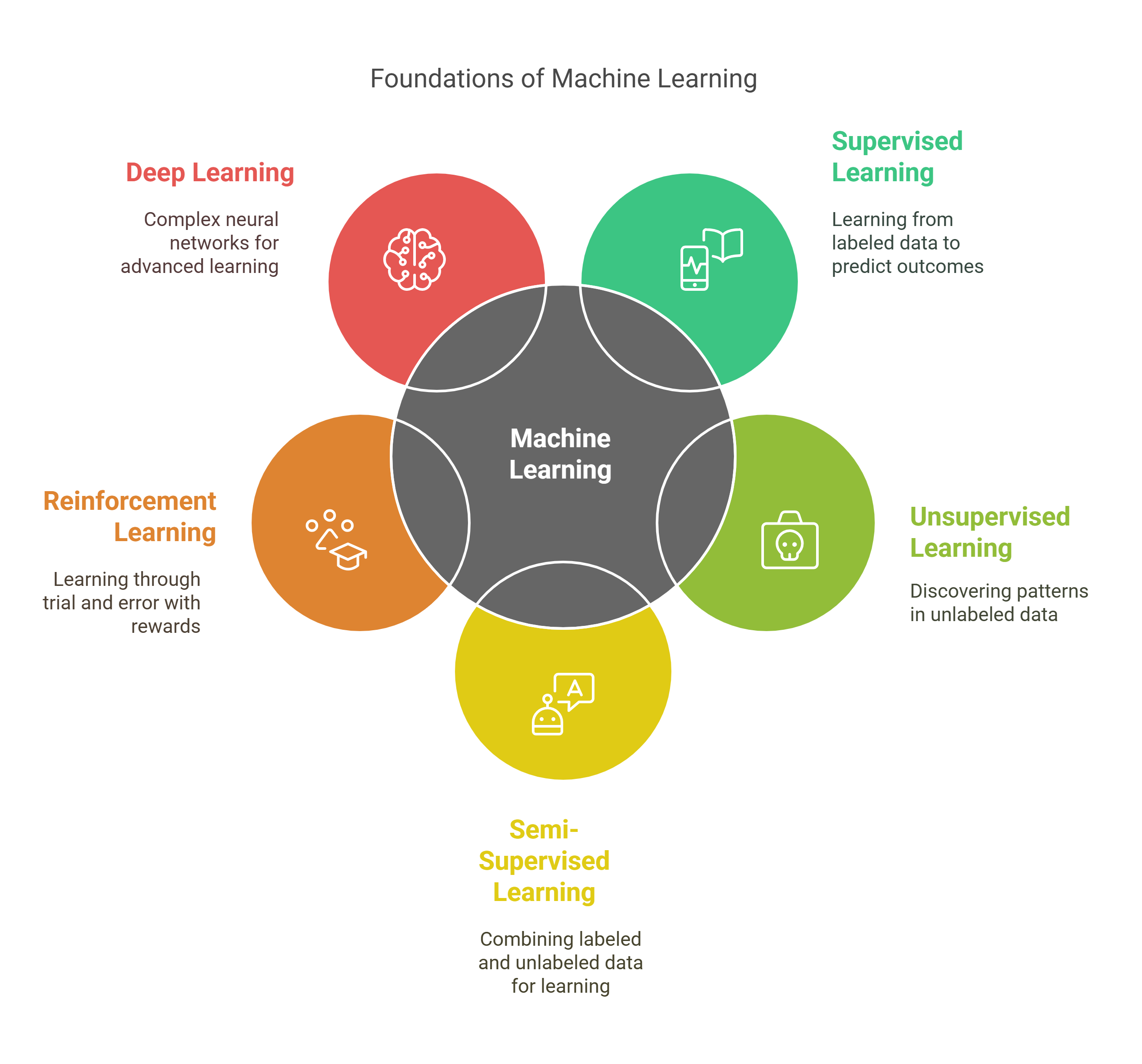
Machine learning professionals skilled in using machine learning categories are in high demand due to their ability to handle different problems. If you're looking to develop skills in ML, here are some top-rated courses to help you get there:
- Masters in Artificial Intelligence and Machine Learning
- Executive Diploma in Machine Learning and AI
- Master’s Degree in Artificial Intelligence and Data Science
Let’s understand the main categories of machine learning in greater detail:
1. Supervised Learning
In supervised learning, the model is trained on labeled data, meaning each input comes with a corresponding output. The goal is for the model to learn the mapping between input and output so it can predict the correct output for new, unseen data.
Features:
- Requires labeled data for training.
- Predicts outcomes based on the input data.
- Can be used for both regression and classification tasks.
Problems Solved:
- Predicting numerical values (e.g., house prices).
- Classifying data into predefined categories (e.g., spam email detection).
- Time-series forecasting (e.g., predicting stock prices).
Real-Life Application: In healthcare, supervised learning models are used for predicting diseases, diagnosing conditions, or even predicting patient outcomes. For instance, a supervised learning model might be trained on a dataset containing medical images and their corresponding diagnoses (e.g., “lung cancer,” “no cancer”) to identify lung cancer in new X-ray images.
The supervised approach is ideal here because you have clear input-output pairs (images and their diagnoses), and the algorithm can learn from this historical data to make predictions on unseen cases.
Why it’s suitable? Supervised learning is perfect for healthcare because the problem is well-defined: there are specific conditions (the labels) and corresponding medical data (the inputs). You can rely on historical data to learn patterns that help predict the future, making this method highly effective for medical diagnostics and personalized treatment planning.
You can learn the basic healthcare IT skills with upGrad’s free E-Skills in Healthcare course. You will explore tools, strategies, and frameworks to implement effective tech solutions in healthcare environments.
Also Read: 6 Types of Supervised Learning You Must Know About in 2025
2. Unsupervised Learning
In unsupervised learning, the model is given data without any labels. The goal is for the model to identify underlying patterns or groupings in the data on its own. It’s often used for clustering and dimensionality reduction.
Features:
- Works with unlabeled data.
- Finds hidden patterns or groupings in data.
- Often used for clustering and dimensionality reduction.
Problems Solved:
- Identifying customer segments based on purchasing behavior.
- Reducing data dimensionality for better visualization and analysis.
- Detecting anomalies or outliers in datasets (e.g., fraud detection).
Real-Life Application: In marketing, unsupervised learning is often used to segment customers into distinct groups based on their purchasing behavior. For instance, using clustering techniques like K-means or DBSCAN, a retailer could segment customers into different groups based on their shopping habits, product preferences, and demographics.
The algorithm uncovers natural groupings without requiring explicit labels, allowing the business to tailor marketing efforts to each group effectively.
Why it’s suitable? Customer segmentation is an exploratory task, where you may not know beforehand how many distinct customer types exist or how they should be grouped. Unsupervised learning allows the algorithm to find these patterns organically, making it ideal for tasks that require discovery, rather than prediction.
Decoding what drives customer action can be easy with upGrad’s free Introduction to Consumer Behavior course. You will explore the psychology behind purchase decisions, discover proven behavior models, and learn how leading brands influence buying habits.
Also Read: Difference Between Supervised and Unsupervised Learning
3. Semi-Supervised Learning
Semi-supervised learning combines both labeled and unlabeled data, often using a small amount of labeled data and a larger set of unlabeled data. It’s useful when labeling data is expensive or time-consuming.
Features:
- Combines labeled and unlabeled data.
- Reduces the need for large labeled datasets.
- Often used in situations where labeling data is expensive or time-consuming.
Problems Solved:
- Improving model accuracy with a small amount of labeled data.
- Handling large volumes of unlabeled data.
- Speeding up the model training process without needing extensive labeled datasets.
Real-Life Application: Imagine you have a large collection of medical images (e.g., X-rays or MRIs) but only a small fraction are labeled with diagnoses (e.g., cancerous, benign). In such cases, semi-supervised learning can leverage the vast amount of unlabeled data to improve the model’s accuracy.
By using the labeled data to guide the learning and the unlabeled data to uncover more patterns, the model can learn effectively without requiring large amounts of manually labeled data.
Why it’s suitable? Labeling medical images can be costly and requires expert knowledge. Semi-supervised learning allows you to make the most out of a small set of labeled data, thereby reducing the reliance on expensive manual labeling, while still learning from the structure within a larger set of unlabeled data.
Also Read: Machine Learning Applications in Healthcare: What Should We Expect?
4. Reinforcement Learning
In reinforcement learning, an agent learns to make decisions by interacting with an environment. The agent receives rewards or penalties based on its actions and uses this feedback to improve future decisions. This category is inspired by how humans and animals learn from experience.
Features:
- Learns through interaction with the environment.
- Receives feedback in the form of rewards or penalties.
- Goal-oriented, aiming to maximize cumulative rewards over time.
Problems Solved:
- Decision-making in dynamic environments.
- Optimal resource allocation and planning.
- Game-playing AI, where the model learns through trial and error.
Real-Life Application: Reinforcement learning is widely used in training autonomous vehicles, where the car learns to drive by interacting with its environment. The car receives rewards for making safe driving decisions (e.g., staying in the lane, stopping at a red light) and penalties for risky actions (e.g., running a red light, swerving out of the lane).
Over time, the vehicle learns to navigate the environment by optimizing its decision-making policy to maximize its cumulative reward (i.e., driving safely).
Why it’s suitable? Reinforcement learning is perfect for autonomous vehicles because the learning happens through trial and error, just like a human learning to drive. The agent doesn’t need explicit instructions for every scenario but instead learns from the consequences of its actions, making it well-suited for complex, real-time environments where decision-making evolves continuously.
Also Read: A Guide to Actor Critic Model in Reinforcement Learning
5. Deep Learning
A subset of machine learning, deep learning uses neural networks with many layers to model complex patterns in large datasets. It’s particularly effective in tasks such as image recognition, speech processing, and natural language understanding.
Features:
- Utilizes neural networks with many layers (hence the term "deep").
- Excels at learning from large amounts of unstructured data (e.g., images, text).
- Performs feature extraction automatically, reducing the need for manual feature engineering.
Problems Solved:
- Image and speech recognition.
- Natural language processing (e.g., chatbots, language translation).
- Complex pattern recognition in large datasets.
Real-Life Application: Deep learning models are extensively used in facial recognition systems, where neural networks learn to identify unique facial features from large datasets of images.
For example, the technology is applied in security systems at airports or buildings, where the model can match a person’s face to a database of known individuals. This is accomplished using convolutional neural networks (CNNs) that automatically extract features from images and perform classification.
Why it’s suitable? Facial recognition requires the ability to process high-dimensional visual data and extract relevant patterns from it. Deep learning excels in this domain due to its ability to automatically learn hierarchical features from raw data, eliminating the need for manual feature engineering. It’s especially well-suited for complex tasks like image classification, where traditional machine learning models may struggle.
Each of these categories of machine learning has its own strengths and is suited to different types of problems. Understanding when and how to apply them is crucial for building successful machine learning models.
You can get a better understanding of neural networks with upGrad’s free Fundamentals of Deep Learning and Neural Networks course. Get expert-led deep learning training, and hands-on insights, and earn a free certification.
Also Read: Neural Network Architecture: Types, Components & Key Algorithms
Now that you have a good understanding of categories of machine learning, let’s look at the common classes of problems in machine learning solved by them.
Common Classes of Problems in Machine Learning
Machine learning techniques are tailored to solve specific types of problems. Choosing the right approach depends on the problem's nature. For example, regression predicts continuous values, while classification assigns categories of machine learning.
Clustering groups similar data, and anomaly detection identifies outliers. Understanding the problem and the data helps in selecting the best technique. The right method ensures better performance and aligns with real-world applications.
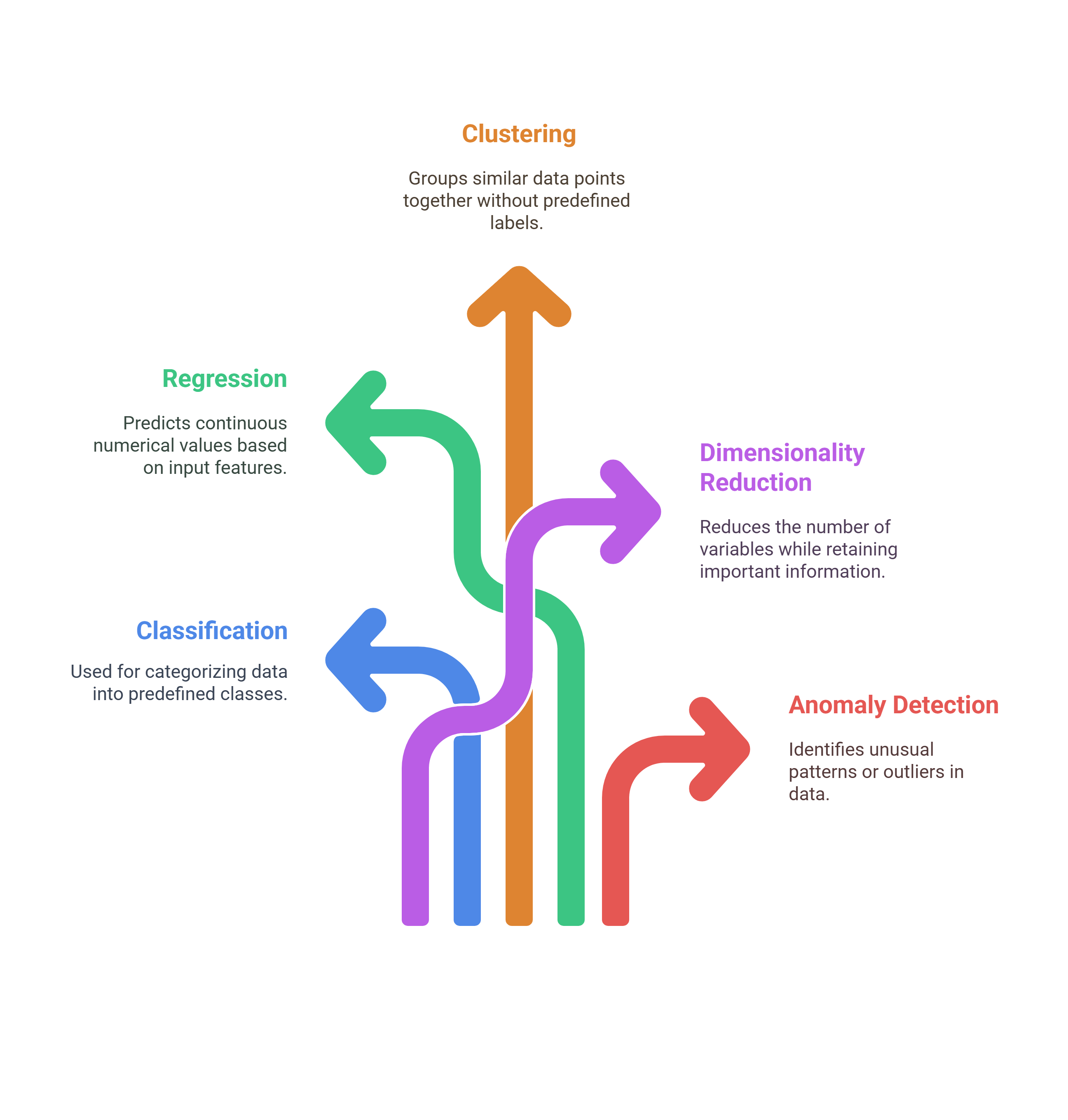
Now, let’s explore the common classes of problems in machine learning and the techniques best suited to solve them:
1. Classification
Classification is a problem type where the goal is to predict a discrete label or category for each data point. This is a supervised learning task where the model is trained on labeled data.
Problem Examples:
- Predicting whether an email is spam or not.
- Diagnosing medical conditions based on patient data (e.g., predicting if a tumor is malignant or benign).
Common Algorithms Used: Logistic Regression, Decision Trees, Random Forest, Support Vector Machines, k-Nearest Neighbors.
Learn the fundamentals of logistic regression with upGrad’s free Logistic Regression for Beginners course. It covers univariate and multivariate models and their practical applications in data analysis and prediction.
Also Read: Everything You Need to Know About Binary Logistic Regression
2. Regression
Regression involves predicting a continuous output based on input features. Like classification, it’s a supervised learning task, but the output is numerical.
Problem Examples:
- Predicting house prices based on features such as size, location, and number of rooms.
- Estimating the salary of an employee based on years of experience and education level.
Common Algorithms Used: Linear Regression, Lasso, Ridge Regression, Decision Trees for Regression, Support Vector Regression.
If you want to learn more about linear regression, try upGrad’s free Linear Regression - Step by Step Guide. It will help you build a strong foundation in predictive modeling and you will learn simple and multiple regression, performance metrics, and applications across data science domains.
Also Read: Types of Regression in Machine Learning: 18 Advanced Models
3. Clustering
Clustering is an unsupervised learning problem where the goal is to group similar data points together. Unlike classification, there are no predefined labels, and the algorithm must discover the inherent structure of the data.
Problem Examples:
- Segmenting customers into different groups based on purchasing behavior.
- Grouping similar documents for topic modeling in natural language processing.
Common Algorithms: K-means, DBSCAN, Hierarchical Clustering, Agglomerative Clustering.
You will learn more about clustering techniques with upGrad’s free Unsupervised Learning: Clustering course. Explore K-Means, Hierarchical Clustering, and practical applications to uncover hidden patterns in unlabelled data.
Also Read: Clustering vs Classification: What is Clustering & Classification
4. Dimensionality Reduction
Dimensionality reduction aims to reduce the number of input variables in a dataset while preserving essential patterns and structures. This technique is useful when dealing with high-dimensional data.
Problem Examples:
- Reducing the number of features in an image dataset for faster processing and easier visualization.
- Simplifying a large set of sensor readings in a smart home to detect anomalies.
Common Algorithms: Principal Component Analysis (PCA), t-SNE, Autoencoders.
5. Anomaly Detection
Anomaly detection identifies rare or unusual patterns that do not conform to expected behavior. This is useful for identifying outliers in data that may indicate problems or exceptional cases.
Problem Examples:
- Detecting fraudulent credit card transactions.
- Identifying malfunctioning equipment in a manufacturing process based on sensor data.
Common Algorithms: Isolation Forest, One-Class SVM, Local Outlier Factor (LOF), k-Means Clustering for anomaly detection.
These problem classes span a wide range of applications across industries. Depending on your use case, you can select the appropriate machine learning method that aligns with the problem you are trying to solve.
If you want to improve your understanding of ML algorithms, upGrad’s Executive Diploma in Machine Learning and AI can help you. With a strong hands-on approach, this program helps you apply theoretical knowledge to real-world challenges, preparing you for high-demand roles like AI Engineer and Machine Learning Specialist.
Also Read: Types of Machine Learning Algorithms with Use Cases Examples
Now that you’re familiar with the problem classes, let’s explore the best practices you can follow when choosing the right categories of machine learning for your problem.
Best Practices to Follow When Choosing a Machine Learning Category
When choosing the right machine learning category for a problem, it’s important to follow best practices. These practices ensure your models are technically suited to the problem, and optimized for performance, interpretability, and scalability. They help you select the most effective approach, minimize errors, and ensure the model works well in real-world scenarios.
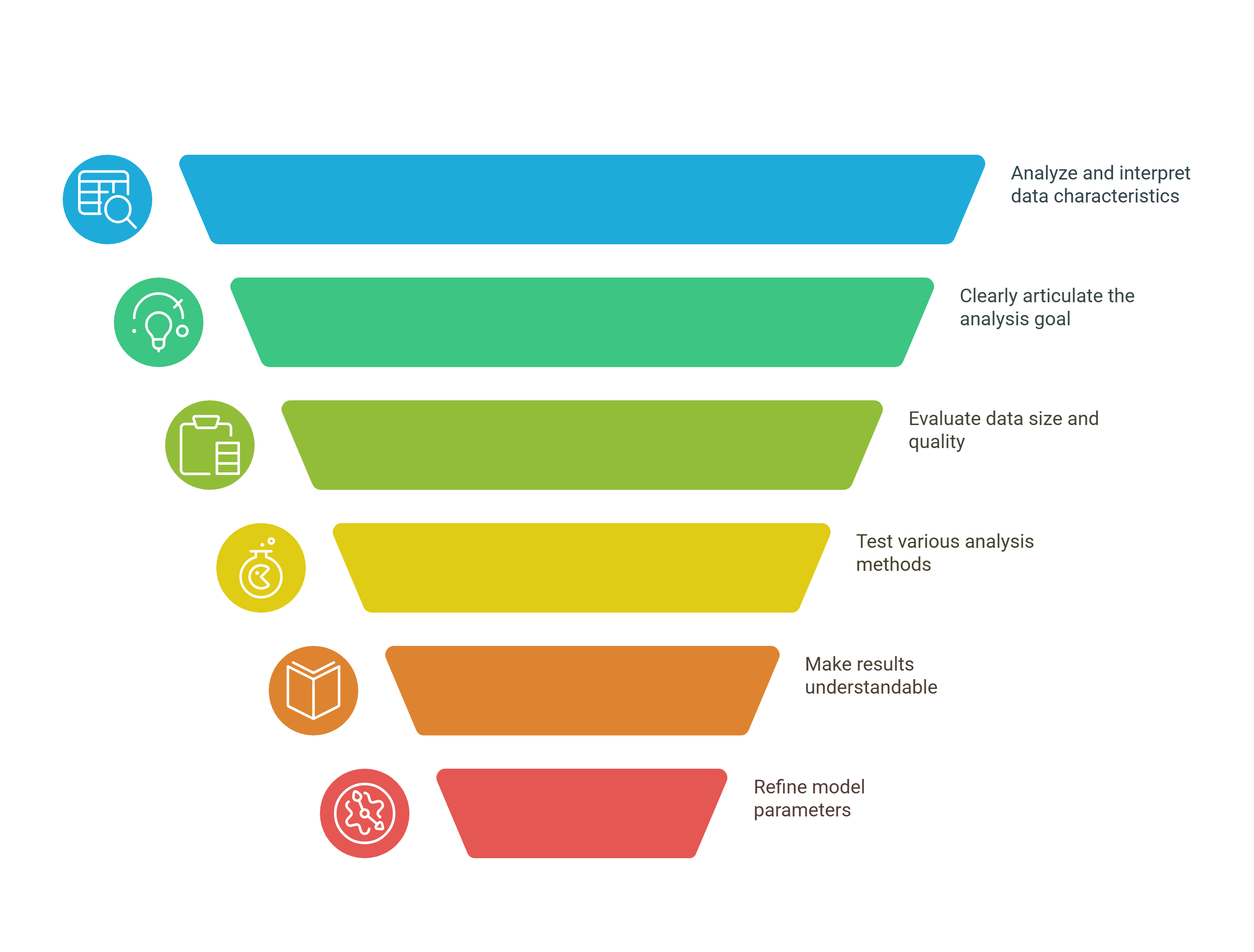
By applying the below practices, you can improve model accuracy, reduce overfitting, and ensure the solution can scale with growing data:
1. Understand Your Data
The first step in solving any problem with machine learning is understanding the data. The type of data you have, whether it’s labeled, unlabeled, continuous, categorical, or high-dimensional, will help you determine whether you should use supervised learning, unsupervised learning, or another method.
Without this understanding, you might choose an inappropriate technique that either fails to capture the data’s inherent patterns or doesn’t provide useful insights.
2. Clearly Define the Problem
The success of a machine learning model hinges on having a clear understanding of what you’re trying to solve. If your problem involves predicting a numerical value, regression models are typically best.
For tasks involving categorizing data into distinct groups, classification techniques should be prioritized. Clarity in problem definition ensures that you don’t waste time applying the wrong techniques, ultimately improving both model accuracy and project efficiency.
3. Consider the Size and Quality of the Data
Data quality and quantity are critical factors in choosing the right machine learning approach. For instance, deep learning models require vast amounts of data to be effective, whereas traditional algorithms like decision trees, random forests, or support vector machines often perform well on smaller datasets.
If the data is noisy or sparse, simpler models with strong regularization techniques may outperform complex models.
4. Experiment with Different Techniques
Machine learning is often an iterative process. By experimenting with multiple techniques, you can compare their performance and understand which one best fits your problem. Trying out various approaches allows you to gain insights into different algorithms' strengths and weaknesses and helps you avoid relying on a "one-size-fits-all" mindset.
This is especially true for problems where domain-specific insights aren’t readily available, and trial-and-error might be the best route to identifying the optimal model.
5. Account for Interpretability
While model accuracy is important, interpretability is equally crucial in industries like healthcare, finance, and law. Some models (e.g., decision trees) are more transparent and easier to explain to non-technical stakeholders, while others (e.g., deep learning) can be more difficult to interpret.
Best practices emphasize choosing a model that not only performs well but also aligns with regulatory or ethical requirements for transparency.
6. Iterate and Tune Hyperparameters
Hyperparameter tuning can significantly impact the performance of your model. Simple models with default settings can often underperform, while well-tuned models can outperform more complex counterparts. Best practices encourage you to use techniques like grid search or random search to find the optimal set of hyperparameters. Cross-validation ensures that the model generalizes well to unseen data, which is essential for building robust, reliable models.
These guidelines help mitigate the risk of overfitting or underfitting, ensure that models deliver actionable insights, and prevent unnecessary computational waste.
Also Read: Random Forest Hyperparameter Tuning in Python: Complete Guide With Examples
To solidify your understanding of the categories of machine learning, test your knowledge with a quiz. It’ll help reinforce the concepts discussed throughout the tutorial and ensure you're ready to apply them in your projects.
Quiz to Test Your Knowledge on Categories of Machine Learning
Assess your understanding of machine learning categories, problem types, best practices, and real-world applications by answering the following multiple-choice questions.
Test your knowledge now!
1. What is the primary difference between supervised and unsupervised learning in machine learning?
a) Supervised learning requires labeled data, while unsupervised learning does not
b) Supervised learning only works with numerical data
c) Unsupervised learning requires labeled data
d) Supervised learning uses deep learning techniques, while unsupervised learning does not
2. Which of the following is an example of a problem best suited for supervised learning?
a) Customer segmentation
b) Email spam detection
c) Market basket analysis
d) Anomaly detection
3. What is the main advantage of using unsupervised learning?
a) It doesn’t require labeled data
b) It is faster to train
c) It always provides accurate predictions
d) It works well for regression tasks
4. In reinforcement learning, what does the "reward" represent?
a) The action taken by the agent
b) The feedback provided after performing an action
c) The state of the environment
d) The goal or target in the environment
5. Which of the following best describes semi-supervised learning?
a) The model only works with labeled data
b) It combines small amounts of labeled data with a large amount of unlabeled data
c) The model does not require any data for training
d) It works with completely unlabeled data
6. What is a common use case for deep learning?
a) Classifying images
b) Customer segmentation
c) Stock price prediction
d) Sentiment analysis on text
7. Which of the following problems is best suited for a regression model in supervised learning?
a) Predicting the likelihood of a customer buying a product
b) Classifying emails as spam or not spam
c) Predicting house prices based on features like size and location
d) Clustering customers based on their purchasing habits
8. In unsupervised learning, which method is commonly used to group similar data points?
a) Classification
b) Regression
c) Clustering
d) Dimensionality reduction
9. Why is reinforcement learning often used for decision-making tasks?
a) It works well with labeled data
b) It learns by exploring the environment and receiving feedback through rewards
c) It can only be applied to supervised learning tasks
d) It directly uses regression techniques to make decisions
10. How does semi-supervised learning improve on traditional supervised learning?
a) By eliminating the need for any labeled data
b) By using both labeled and unlabeled data to make more accurate predictions
c) By using a small amount of unlabeled data for training
d) By providing real-time updates to the model during training
This quiz will help you evaluate your understanding of machine learning categories, their problem types, and how to apply them effectively in real-world scenarios.
You can also showcase your experience in advanced ML technologies with upGrad’s Professional Certificate Program in Data Science and AI. Along with earning Triple Certification from Microsoft, NSDC, and an Industry Partner, you will build Real-World Projects on Snapdeal, Uber, Sportskeeda, and more.
Also Read: 5 Breakthrough Applications of Machine Learning
You can also continue expanding your skills in machine learning with upGrad, which will help you deepen your understanding of advanced ML concepts and real-life applications.
Upskill with upGrad to Stay Ahead of Industry Trends!
upGrad’s courses provide expert training in machine learning, with a focus on ML categories, their practical applications, and best practices. Learn how to optimize your machine learning models for different scenarios.
While the course covered in the tutorial can significantly improve your knowledge, here are some free courses to facilitate your continued learning:
- Hypothesis Testing
- Unsupervised Learning: Clustering
- Logistic Regression for Beginners
- Linear Regression - Step by Step Guide
- Introduction to Natural Language Processing
You can also get personalized career counseling with upGrad to guide your career path, or visit your nearest upGrad center and start hands-on training today!
Similar Reads:
- Artificial Intelligence Tutorial
- Machine Learning Tutorials
- Deep Learning Tutorial: Master AI & Neural Networks
- Top 10 Machine Learning Applications in 2025 and the Role of Edge Computing
- Q Learning
- Bagging in Machine Learning: Overview, Steps, Benefits & Applications
- Cost Function In Machine Learning
- Image Annotation in Machine Learning
- Quantum Computing
- Bootstrap Aggregation
- Mahalanobis Distance: Formula, Python Code, Applications & Best Practices
- Support Vector Machine Svm For Anomaly Detection
- Isolation Forest Algorithm for Anomaly Detection
- Exponential Smoothing Method in Forecasting: Techniques and Applications
- Time Series Forecasting with ARIMA Models: Components, Advantages & Steps
FAQs
1. Can unsupervised learning be used for predictive tasks?
Unsupervised learning is primarily used for exploratory analysis and pattern discovery. However, certain techniques like clustering or dimensionality reduction can support predictive tasks indirectly, though it’s not the primary use case.
2. What are the key differences between supervised learning and reinforcement learning?
Supervised learning involves learning from labeled data to make predictions, while reinforcement learning involves learning by interacting with an environment and receiving feedback in the form of rewards or penalties.
3. Why do some ML problems require semi-supervised learning?
Semi-supervised learning is useful when there is a large amount of unlabeled data but limited labeled data. This method can significantly reduce the cost and time of labeling large datasets while still achieving good performance.
4. Is deep learning always better than traditional machine learning?
Not necessarily. Deep learning excels with large, complex datasets, like images or sequences, but for smaller datasets or simpler problems, traditional machine learning methods like decision trees or SVM might be more efficient and effective.
5. How does unsupervised learning help in anomaly detection?
In unsupervised learning, anomaly detection methods like clustering or density estimation can identify unusual patterns in data without the need for labeled training examples. The algorithm finds outliers by learning the normal distribution of data.
6. Can reinforcement learning be applied to problems that don’t have clear rewards?
Reinforcement learning relies on the definition of rewards to guide the learning process. If a task doesn't have well-defined rewards, it’s challenging to apply RL effectively. However, reward shaping or designing custom rewards could be a solution in such cases.
7. What types of machine learning problems are best suited for clustering techniques?
Clustering is useful when you need to discover groups or patterns in your data, such as customer segmentation, market basket analysis, and organizing large datasets without prior labels or categories.
8. Why do some machine learning algorithms perform better with certain categories of learning?
The choice of algorithm depends on the problem type and available data. For example, classification algorithms are effective for supervised learning with labeled data, whereas clustering algorithms are suited for unsupervised learning where no labels are provided.
9. When should I switch from supervised learning to semi-supervised learning?
If obtaining labeled data is expensive or time-consuming, but there is plenty of unlabeled data available, semi-supervised learning can be a valuable approach. It helps bridge the gap between fully labeled and fully unlabeled datasets.
10. Can deep learning techniques be applied to small datasets?
Deep learning generally requires large datasets to perform well and avoid overfitting. For smaller datasets, traditional machine learning models may work better and require less computational power, while deep learning might struggle.
11. What are the challenges in scaling reinforcement learning for real-world applications?
Scaling reinforcement learning to real-world problems often involves challenges such as long training times, the need for large amounts of computational resources, and the difficulty of defining clear and meaningful reward structures.





upGrad Learner Support
Talk to our experts. We are available 7 days a week, 10 AM to 7 PM
Indian Nationals
Foreign Nationals
Disclaimer
The above statistics depend on various factors and individual results may vary. Past performance is no guarantee of future results.
The student assumes full responsibility for all expenses associated with visas, travel, & related costs. upGrad does not .