All courses
Agentic AI
Agentic AI

IIIT Bangalore
Executive Programme in Generative AI for LeadersArtificial Intelligence
Degree / Exec. PG

IIIT Bangalore
Executive Diploma in Machine Learning and AI
OPJ Global University
Master’s Degree in Artificial Intelligence and Data Science
Liverpool John Moores University
Master of Science in Machine Learning & AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIExecutive Certificate

IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership ProgrammeIIIT Bangalore
Executive Programme in Generative AI for Leaders
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceOffline Bootcamps

upGrad
Data Science and AI-MLDoctorate
For All Domains
IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
Swiss School of Business and Management
Global Doctor of Business Administration from SSBM
Edgewood University
Doctorate in Business Administration by Edgewood UniversityGolden Gate University
Doctor of Business Administration From Golden Gate University
Rushford Business School
Doctor of Business Administration from Rushford Business School, SwitzerlandGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)-d9bdeff6165f4eb1ba2adcebde78e961.svg)
University of Waterloo
Chief Technology and AI Officer ProgramLeadership / AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIMachine Learning
Machine Learning
Data Science
Degree / Exec. PG
O.P Jindal Global University
Master’s Degree in Artificial Intelligence and Data ScienceIIIT Bangalore
Executive Diploma in Data Science & AILiverpool John Moores University
Master of Science in Data ScienceExecutive Certificate
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceupGrad | Microsoft
Gen AI Mastery Certificate for Content CreationOffline Bootcamps
upGrad
Data Science and AI-MLupGrad
Data AnalyticsMBA
Masters

Paris School of Business
Master of Science in Business Management and TechnologyO.P.Jindal Global University
MBA (with Career Acceleration Program by upGrad)Edgewood University
MBA from Edgewood UniversityO.P.Jindal Global University
MBA from O.P.Jindal Global UniversityGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)Executive Certificate

IMT, Ghaziabad
Advanced General Management ProgramMarketing
Executive Certificate
Offline Bootcamps
upGrad
Digital MarketingManagement
Degree
O.P Jindal Global University
MSc in International Accounting & Finance (ACCA integrated)Paris School of Business
Master of Science in Business Management and Technology
Golden Gate University
Master of Arts in Industrial-Organizational PsychologyExecutive Certificate

IIM Kozhikode
Human Resource Analytics Course from IIM-KupGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftEducation
Education

Northeastern University
Master of Education (M.Ed.) from Northeastern UniversityEdgewood University
Doctor of Education (Ed.D.)Edgewood University
Master of Education (M.Ed.) from Edgewood UniversityCertifications
Project Management
Certification

Knowledgehut
Leadership And Communications In ProjectsKnowledgehut
Microsoft Project 2007/2010-ae8d039bbd2a41318308f8d26b52ac8f.svg)
Knowledgehut
Financial Management For Project ManagersKnowledgehut
Fundamentals of Earned Value Management (EVM)Knowledgehut
Fundamentals of Portfolio ManagementKnowledgehut
Fundamentals of Program Management-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
Knowledgehut
CAPM® CertificationsKnowledgehut
Microsoft® Project 2016Certifications & Trainings
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)
Knowledgehut
PMP® CertificationKnowledgehut
PMI-RMP® CertificationKnowledgehut
PMP Renewal Learning PathKnowledgehut
Oracle Primavera P6 V18.8Knowledgehut
Microsoft® Project 2013Knowledgehut
PfMP® Certification CourseKnowledgehut
Project Planning and MonitoringPrince2 Certifications

Knowledgehut
PRINCE2® FoundationKnowledgehut
PRINCE2® PractitionerKnowledgehut
PRINCE2 Agile Foundation and PractitionerKnowledgehut
PRINCE2 Agile® Foundation CertificationKnowledgehut
PRINCE2 Agile® Practitioner CertificationManagement Certifications
Knowledgehut
Project Management Masters Certification ProgramKnowledgehut
Change ManagementKnowledgehut
Project Management TechniquesKnowledgehut
Product Management Certification ProgramKnowledgehut
Project Risk Management- Study abroad
- Offline centres
- uGSOT - B.Tech
More
%20(1)-d5498f0f972b4c99be680c2ee3b792d7.svg)



49. Variance in ML
What Is Stacking Machine Learning? Techniques and Model Structure Simplified
Did you know? In platforms like Netflix and Amazon, employing stacking techniques with different recommendation algorithms can significantly boost the accuracy and personalization of suggestions. Studies also found that a stacked recommender system combining collaborative filtering and content-based methods improved click-through rates by an average of 10-12% compared to the best individual algorithm. |
Ensemble methods are employed in machine learning to enhance the performance and robustness of models by combining the predictions of multiple individual learners. The primary motivation behind using ensembles is to reduce either the bias (systematic error) or the variance (sensitivity to fluctuations in the training data) of the overall prediction, often achieving a better trade-off between the two.
While techniques like bagging (e.g., Random Forests) focus on reducing variance by training multiple models on different subsets of the data in parallel, and boosting (e.g., Gradient Boosting) aims to reduce bias by sequentially training models to correct the errors of previous ones, stacking offers a distinct approach.
Let’s explore what stacking is, how this powerful ensemble technique works, and when it is most beneficial to apply it in your machine learning projects.
Learn how to build and optimize various machine learning models, including ensemble methods like stacking, to tackle complex real-world problems! Explore upGrad’s comprehensive online AI and ML programs to equip you with in-demand skills.
What is Stacking Machine Learning? A Structured Ensemble Approach
Stacking in machine learning is an ensemble learning technique that combines the predictions of multiple base models (also known as level-0 or first-layer models) by training a meta-learner (also known as a level-1 or second-layer model) to output a final prediction.
Instead of using simple averaging or voting, stacking learns the optimal way to weigh the contributions of each base model. The projections of the base models become the input features for the meta-learner.
To gain a deep understanding of these powerful ensemble techniques, including stacking, and learn how to apply them effectively, explore our comprehensive AI and ML courses to master ensemble techniques:
- Executive Diploma in Machine Learning and AI: Gain a strong foundation in data science, covering essential machine learning algorithms, including ensemble methods.
- Master of Science in Data Science: Deepen your expertise in advanced data science concepts and techniques, focusing on building sophisticated predictive models.
- Master’s Degree in Artificial Intelligence and Data Science: Designed for working professionals, this program offers practical knowledge in AI and ML, including advanced ensemble methods like stacking.
Unlike bagging, where multiple instances of the same base learner are trained on different subsets of the data in parallel (aiming to reduce variance), and boosting, where base learners are taught sequentially with each trying to correct the errors of its predecessor (aiming to reduce bias), stacking leverages diverse types of base models whose predictions are then combined by a separate learning algorithm.
Why Use Stacking in Machine Learning Models?
 Why Use Stacking in Machine Learning Models_ - visual selection (1)-f427888ed9474576a329b810feb17260.png)
Stacking offers several benefits, primarily improving generalization performance. By combining the strengths of different models, a stacked model can often achieve higher accuracy and robustness on unseen data compared to any of the individual base models.
- Improved Generalization: Stacking machine learning can effectively capture different aspects of the data as learned by the diverse base models. The meta-learner then learns to synthesize these various perspectives, leading to a more well-rounded and generalizable final prediction.
- Leveraging Varied Model Performance: Stacking is particularly useful when you have a set of base models that perform well in different regions of the feature space or have different strengths and weaknesses. The meta-learner can learn to trust the predictions of the more accurate base model depending on the input instance.
Let's say we have particular ads related to a specific hobby. Having learned complex patterns in user behavior related to this hobby, the random forest model consistently outperforms the other two models for these ads. The meta-learner can learn to recognize when the input features correspond to these hobby-related ads and give more credence to the random forest's prediction in those instances.
- Mitigating Individual Model Weaknesses: If one base model consistently underperforms on a specific subset of the data, the meta-learner can learn to downweight its predictions in those scenarios, relying more on the strengths of other models.
Also Read: Random Forest Hyperparameter Tuning in Python: Complete Guide With Examples
Comparison: Stacking vs Other Ensemble Techniques
To further clarify the distinctions, the following table summarizes the key differences between stacking and the other prominent ensemble methods, bagging and boosting.
Feature | Stacking | Bagging (e.g., Random Forest) | Boosting (e.g., Gradient Boosting) |
Base Learners | Typically diverse types of models (e.g., linear, tree-based, neural nets) | Typically the same base learner (e.g., multiple decision trees) | Typically the same base learner (e.g., numerous weak learners/trees) |
Training | Base models trained in parallel; meta-learner trained on base predictions | Base models trained independently and in parallel on data subsets | Base models trained sequentially, each trying to correct previous errors |
Combination | Meta-learner (trained model) learns how to weight base model predictions | Predictions are typically combined by simple averaging or voting | Predictions are combined through a weighted sum, with weights determined by model performance |
Goal | Improve predictive accuracy by leveraging different model capabilities | Reduce variance and overfitting | Reduce bias and improve model accuracy |
Data Sampling | Base models trained on the full dataset (predictions on hold-out used for meta-learner) | Each base model is trained on a random subset (with replacement - bootstrapping) | Each base model is trained on a weighted version of the data, emphasizing misclassified instances |
Complexity | Generally more complex to implement and tune due to the meta-learner | Relatively simpler to implement | It can be complex to tune due to the learning rate and number of estimators |
Overfitting Risk | Higher risk of overfitting if the meta-learner is too complex or not enough data for training it | Can reduce overfitting compared to a single complex model | Can be prone to overfitting if the number of boosting rounds is too high |
Further your data science journey! Explore our comprehensive data science course- Unsupervised Learning: Clustering and master essential skills like clustering, data visualization, and statistical analysis. Discover how to leverage tools like Google Analytics to uncover meaningful patterns in your data.
Also Read: Top 5 Machine Learning Models Explained For Beginners
To understand the practical application of this powerful technique, let's examine how stacking in machine learning works step-by-step.
How Stacking in Machine Learning Works?
Stacking machine learning, also known as stacked generalization, is a powerful ensemble learning technique that combines the predictions of multiple base models (also called level-0 models) to build a more robust and accurate final model using a meta-learner (also called a level-1 model).
Think of it as a committee of experts making initial assessments and a final judge synthesizing their opinions to conclude.
The Two-Layer Structure
- Base Learners (Level-0): These individual machine learning models are trained on the original training data. Each base learner makes its predictions for the training and test sets.
- Meta Learner (Level-1): This model is trained on the predictions made by the base learners. Instead of using the original features, the meta-learner takes the outputs of the base models as its input features and learns how to combine these predictions best to make the final prediction.
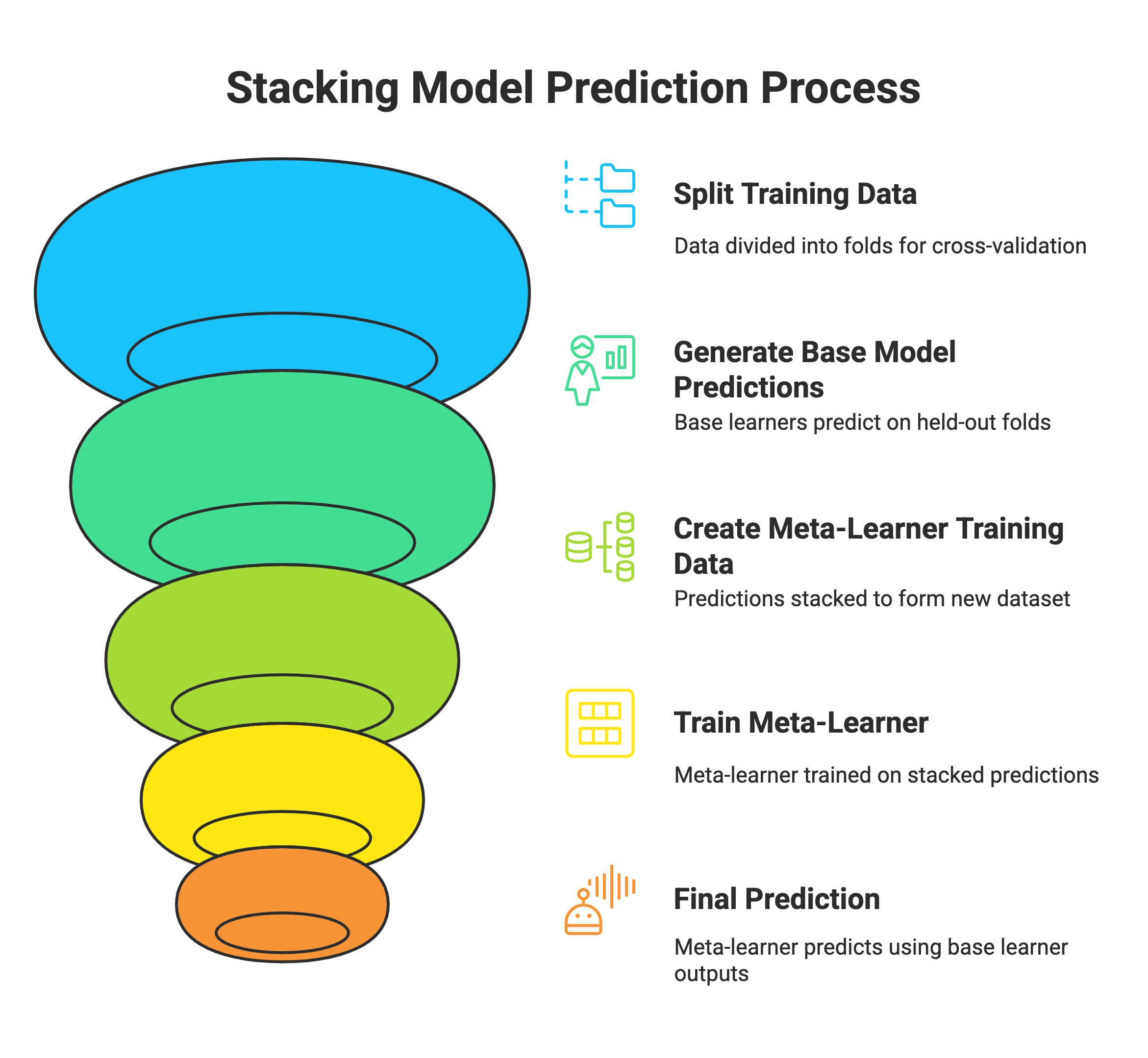
The crucial aspect of stacking is to avoid data leakage during the process. Here's how the data typically flows:
Splitting the Training Data: The original training data is split into multiple folds (e.g., using k-fold cross-validation).
Generating Base Model Predictions (Without Leakage):
- For each fold, the base learners are trained on the remaining folds.
- These trained base learners then make predictions on the held-out fold. This ensures that the projections used to train the meta-learner for a specific data point were made by a model that has not seen that data point during its training.
- This process is repeated for all folds, resulting in a set of out-of-fold predictions for each base learner's entire training dataset.
- The base learners are also trained on the entire original training dataset to generate predictions on the unseen test dataset.
Creating the Meta-Learner Training Data:
The out-of-fold predictions from each base learner for the training data are stacked together to form a new training dataset. The target variable remains the same as in the original training data.
Training the Meta-Learner:
The meta-learner is trained on this new training dataset, where the input features are the predictions of the base learners, and the target variable is the original target.
Final Prediction:
To predict a new, unseen data point (the test set):
- Each base learner (trained on the original training data) makes a prediction.
- These predictions are then fed as input features to the trained meta-learner.
- The meta-learner outputs the final stacked prediction.
Also Read: What Is Ensemble Learning Algorithms in Machine Learning?
Common Model Combinations in Stacking
Stacking in machine learning often combines diverse base models to achieve superior predictive performance compared to individual models. Some common and effective combinations include decision trees with logistic regression, support vector machines (SVMs) with random forests, and various other pairings of fundamentally different algorithms. The key to stacking success lies in the diversity of the base models.
Why Model Diversity Enhances Stacking Performance?
The strength of an ensemble method like stacking stems from the idea that different algorithms have different strengths and weaknesses. They learn different aspects of the underlying data patterns and make different errors. When these diverse models are combined intelligently (through a meta-learner), the ensemble can often:
1. Reduce Variance
Like decision trees, models that are prone to overfitting (high variance) can be stabilized by combining them with models with lower variance, such as logistic regression or k-nearest neighbors. The meta-learner can learn to weigh the predictions of the less stable model appropriately.
2. Reduce Bias
Models with high bias (strong assumptions about the data), like linear models, might miss complex non-linear relationships. Combining them with more flexible models like SVMs with non-linear kernels or tree-based methods can help capture these complexities, thus reducing the overall bias.
3. Correct Different Types of Errors
Different algorithms make errors on various subsets of the data. For instance, a decision tree might struggle with smooth decision boundaries, while a linear model might fail on highly non-linear data.
Combining their predictions allows the ensemble to "average out" these individual errors, leading to more robust and accurate predictions across the entire dataset.
4. Capture Different Data Perspectives
Each algorithm approaches the learning problem from a unique perspective. Linear models look for linear relationships, tree-based models partition the feature space, and instance-based methods rely on similarity to training examples.
Combining these different perspectives allows the ensemble to capture a more comprehensive understanding of the data.
Illustrative Examples in a Table:
Base Model 1 | Base Model 2 | Rationale | Stacking Benefit |
Decision Tree | Tree captures non-linearity (high variance); Logistic Regression offers stability (low variance). | Meta-learner balances detailed (but potentially noisy) tree predictions with stable linear predictions, improving generalization. | |
Support Vector Machine (SVM) | Random Forest | SVM models complex boundaries (sensitive); Random Forest is robust and handles feature interactions well. | Random Forest provides stable predictions; SVM excels at intricate boundaries, allowing the meta-learner to leverage both strengths. |
KNN learns local patterns (sensitive); Naive Bayes is a simple, global probabilistic model. | Meta-learner combines local instance-based learning with global probability assessments for a more comprehensive data view. | ||
Gradient Boosting Machine (GBM) | Neural Network | GBM is accurate (overfit risk); Neural Network learns complex features (data-intensive). | Ensemble leverages GBM's strength with Neural Network's complex feature learning for potentially higher accuracy on large, intricate datasets. |
In essence, the more diverse the base models in a stacking ensemble are in terms of their learning algorithms, the types of errors they make, and the aspects of the data they emphasize, the greater the potential for the meta-learner to learn a sophisticated way to combine their predictions and achieve superior generalization performance.
The meta-learner acts as an intelligent arbitrator, learning when to trust the predictions of each base model based on the input data.
Want to handle data like an expert? UpGrad's comprehensive learning course, Advanced SQL: Functions and Formulas can guide you through this essential skillset. Join over 15,000 learners, and dedicate approximately 11 hours to elevating your SQL proficiency.
Also Read: Types of Machine Learning Algorithms with Use Cases Examples
Now that you understand the value of combining diverse models, let's delve into the mechanics of this powerful ensemble technique.
Step-by-Step Process of Stacking Machine Learning Models
A carefully orchestrated process of data handling, model training, and meta-learning is essential to harness the power of stacking. This section will break down the key stages of building a successful stacked ensemble, emphasizing the critical considerations at each step.
Data Splitting and Cross-Validation Strategy
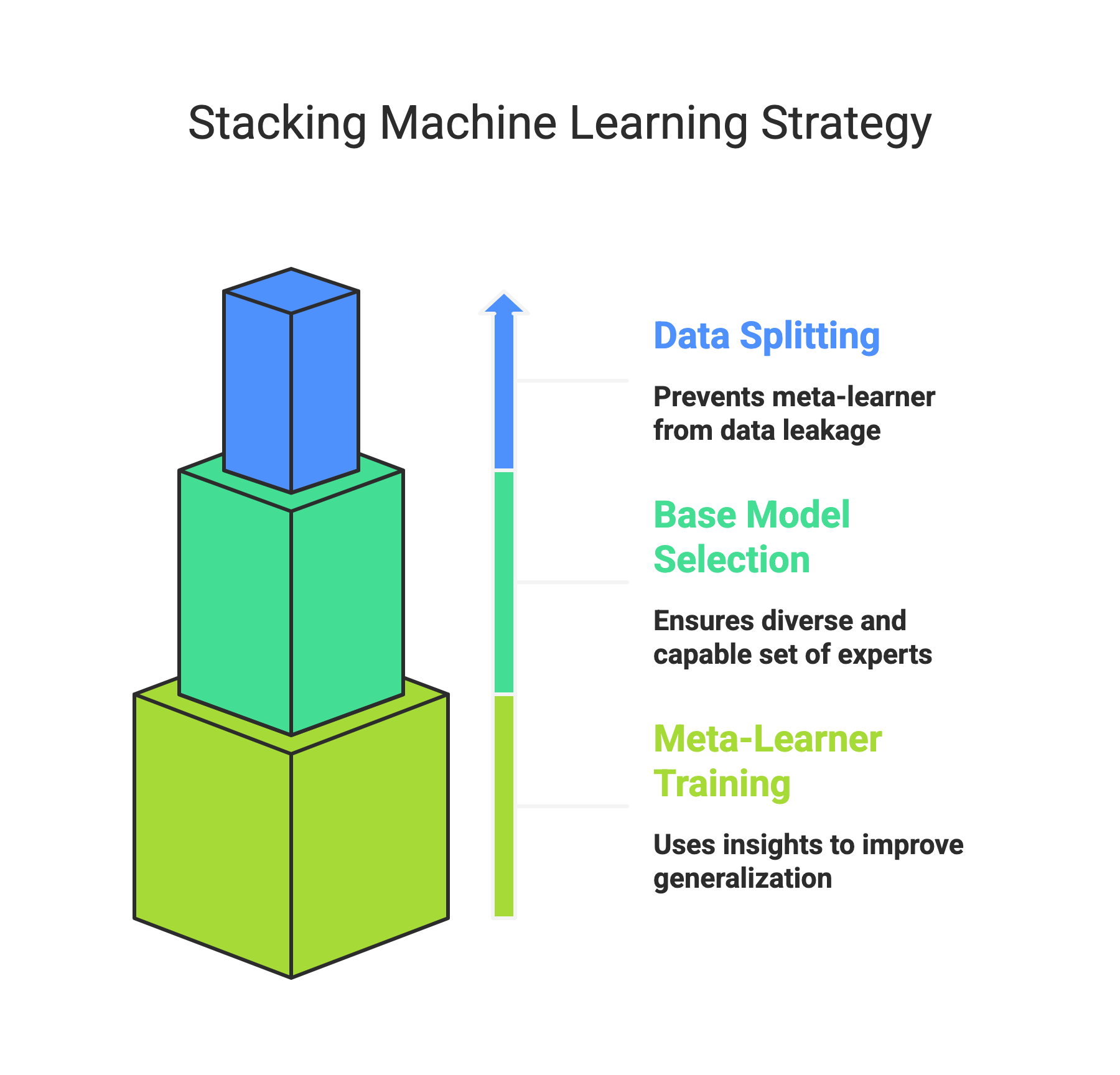
In stacking machine learning, splitting and validating our data across different layers is critical for building a robust and generalizable ensemble. We don't simply train all base models on the entire training set and then train the meta-learner on their predictions on the same data.
This would lead to data leakage, where the meta-learner unfairly benefits from seeing predictions on data the base models were trained on, resulting in an overly optimistic performance estimate on unseen data.
Here's a common strategy outlining how training and validation sets are used in the layers:
First Layer (Base Models):
- The original training data is typically split into several folds using a cross-validation technique (e.g., K-Fold Cross-Validation).
- For each fold, the base models are trained on the remaining folds.
- After training, each base model predicts the held-out fold. These out-of-fold predictions become the training data for the next layer.
- This process is repeated for all folds, ensuring that each data point in the original training set has a corresponding prediction from each base model, generated by a model that hasn't seen that specific data point during its training.
- Optionally, the base models can also be trained on the entire original training set to make predictions on a separate hold-out test set, which will be used for the final evaluation of the stacked model.
Second Layer (Meta-Learner):
- The out-of-fold predictions generated by the base models in the first layer form the new training dataset for the meta-learner. Each row in this new dataset corresponds to a row in the original training data, and the features are the predictions from the different base models.
- The target variable for this new training dataset remains the original target variable.
- The meta-learner is then trained on this new dataset to learn how to combine the base models' predictions best.
- Like the base models, cross-validation can be applied when training the meta-learner to ensure its robustness.
Why Avoiding Data Leakage is Crucial?
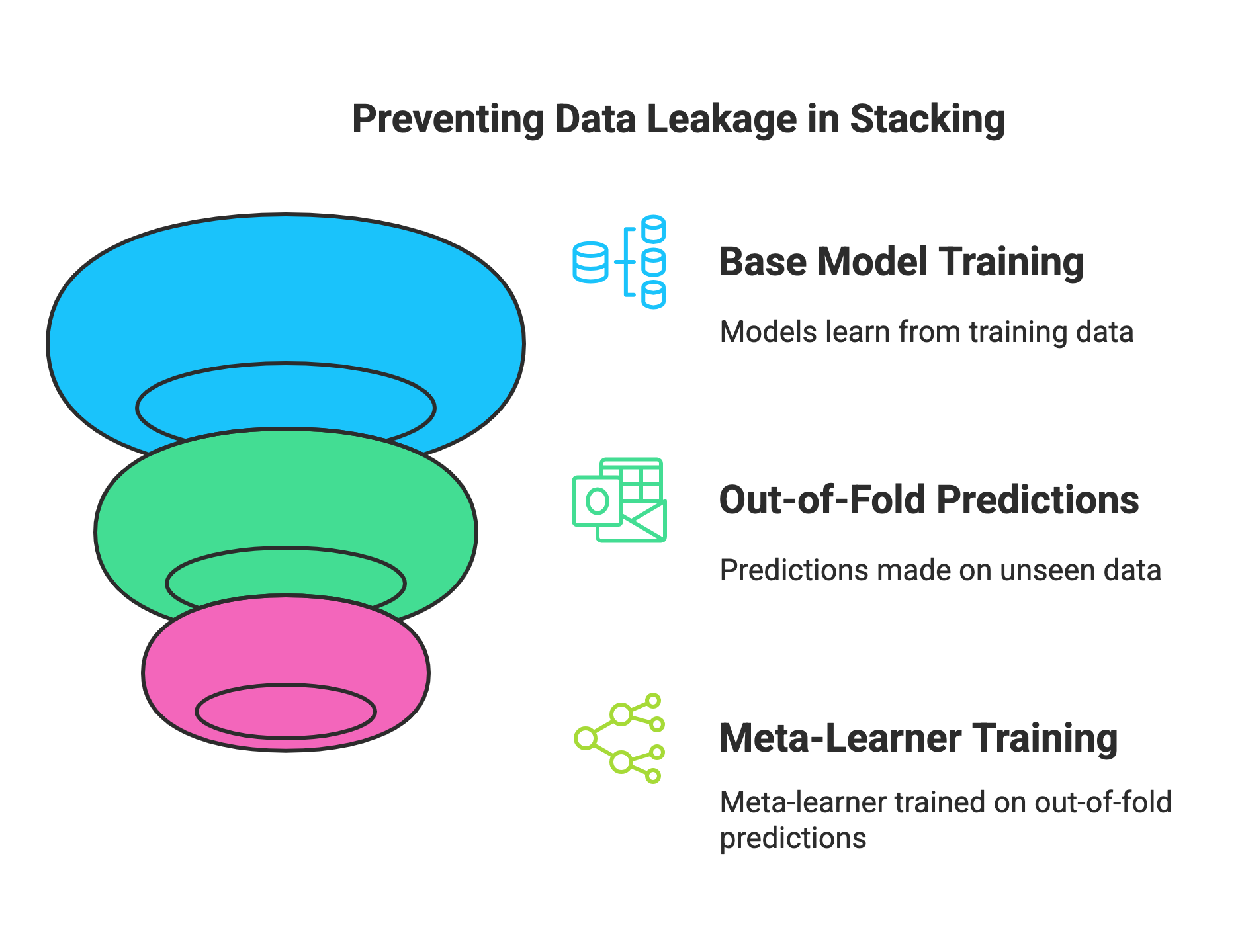
Data leakage in stacking leads to an inflated and unrealistic assessment of the ensemble's performance on new, unseen data. Training the meta-learner on predictions made by base models on the same data they were trained on allows them to learn their biases on that specific training set. This learned behavior won't generalize well to new data.
Example: If a decision tree-based model overfits to noise in the training data, and the meta-learner sees its predictions on that same noisy data, it might incorrectly learn to weight those flawed predictions heavily.
Employing careful cross-validation to generate out-of-fold predictions ensures the meta-learner learns to combine forecasts from base models that haven't seen the data they are predicting, providing a more accurate evaluation of the stacked model's true generalization capability.
Also Read: Stock Market Prediction Using Machine Learning
Building and Training the Meta Learner
The out-of-fold predictions from the base learners serve as the new features for training the meta-learner.
1. Creating the Meta-Feature Matrix
We compile the predictions from all base models into a new feature vector for each original data point. The original target variable remains the label for this new data.
Imagine you have three base models predicting whether a customer will click on an ad (0 or 1). For a single customer, the base models might predict [0.8, 0.3, 0.6]. This becomes the new feature vector for that customer for the meta-learner.
2. Training the Meta Model
A supervised learning algorithm (often simpler, like logistic or linear regression) is trained on this meta-feature matrix to predict the original target. The meta-learner's objective is to discover the optimal way to combine the base models' predictions, effectively learning which models to trust and how to aggregate their outputs for improved accuracy.
For example, the meta-learner might learn that when the first base model predicts a high probability (like 0.8), its prediction is generally more reliable for the outcome.
Also Read: 6 Types of Supervised Learning You Must Know About in 2025
Ready to transform your foundational Python skills into mastery? Our upGrad course, Python Libraries: NumPy, Matplotlib, and Pandas empowers you to leverage advanced techniques like stacking for building highly accurate and robust machine learning models.
Stacking Machine Learning Models in Python Using scikit-learn
Let's further understand the code implementation of stacking machine learning models using scikit-learn's StackingClassifier, providing a comprehensive walkthrough and explanation of each step.
Code Example:
1. Import Necessary Libraries
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
from mlxtend.classifier import StackingClassifier
import numpy as np
import warnings
warnings.simplefilter('ignore')
Explanation:
- We import essential libraries for data handling (datasets, train_test_split), model building (LogisticRegression, KNeighborsClassifier, GaussianNB, RandomForestClassifier), evaluation (cross_val_score), and the stacking classifier (StackingClassifier).
- The warnings module is used to suppress warnings that might clutter the output.
2. Load the Dataset
# Load Iris dataset
iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target
Explanation:
- We load the Iris dataset, a well-known dataset for classification tasks.
- We select only the second and third features (iris.data[:, 1:3]) to simplify visualization and focus on a 2D feature space.
- X represents the feature matrix, and y represents the target labels.
3. Define Base Models and Meta Model
# Define base models
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
# Define meta model
lr = LogisticRegression()
# Create StackingClassifier
sclf = StackingClassifier(classifiers=[clf1, clf2, clf3], meta_classifier=lr)
Explanation:
- We define three base models:
- clf1: K-Nearest Neighbors with 1 neighbor.
- clf2: Random Forest Classifier with a fixed random seed for reproducibility.
- clf3: Gaussian Naive Bayes.
- We define the meta-model (lr), which is a Logistic Regression classifier.
- We create the StackingClassifier by passing the base models and the meta-model.
4. Evaluate Models Using Cross-Validation
# Evaluate each model using 3-fold cross-validation
for clf, label in zip([clf1, clf2, clf3, sclf], ['KNN', 'Random Forest', 'Naive Bayes', 'StackingClassifier']):
scores = cross_val_score(clf, X, y, cv=3, scoring='accuracy')
print(f"Accuracy: {scores.mean():.2f} (+/- {scores.std():.2f}) [{label}]")
Explanation:
- We use 3-fold cross-validation to evaluate each model's performance.
- We compute the mean and standard deviation of accuracy scores for each model.
- We print the results for each model, including the base models and the stacking classifier.
Expected Output:
Accuracy: 0.91 (+/- 0.01) [KNN]
Accuracy: 0.95 (+/- 0.01) [Random Forest]
Accuracy: 0.91 (+/- 0.02) [Naive Bayes]
Accuracy: 0.95 (+/- 0.02) [StackingClassifier]
Explanation of Results:
- The base models KNN, Random Forest, and Naive Bayes each have their own strengths and weaknesses.
- The stacking classifier combines these models, leveraging their strengths to improve performance.
- The comparable accuracy scores for the stacking classifier and the best-performing base model (Random Forest) indicate that stacking can effectively enhance model performance.
Combining diverse base models (e.g., KNN, Random Forest, Naive Bayes) into a stacking ensemble often improves accuracy and robustness in predictive modeling. Furthermore, utilizing a meta-model like Logistic Regression to combine base model predictions allows the ensemble to leverage the strengths of individual classifiers, resulting in a more powerful and generalized model.
Also Read: Everything You Need to Know About Binary Logistic Regression
Having seen how stacking is implemented in Python, let's explore the practical scenarios in which this powerful ensemble technique proves most beneficial.
What Is Stacking in Machine Learning Used For? Use Cases
Stacking is a versatile ensemble learning technique employed across various machine learning tasks to enhance predictive performance and robustness. By intelligently combining the strengths of multiple diverse models, stacking can often achieve superior results compared to individual algorithms.
Use Cases of Stacking in ML Across Model Types
Stacking's versatility allows it to enhance various machine learning tasks by combining the strengths of different model types. It's applicable across classification, regression, and even more complex problems. By intelligently blending diverse models, stacking often yields superior and more robust predictions than individual models. This makes it a powerful technique across a wide range of applications.
- Classification Tasks
Stacking is frequently used to improve the accuracy and F1-scores in classification problems. For instance, combining a probabilistic classifier like Naive Bayes with a discriminative classifier like a Support Vector Machine can lead to more reliable class predictions. Another common application is image classification, where outputs from different convolutional neural network architectures can be stacked to boost recognition accuracy.
- Regression Tasks:
In regression, stacking can help to reduce the mean squared error or improve the R-squared value. Combining a linear model like Ridge Regression with a non-linear model like a Random Forest Regressor can capture linear and complex relationships in the data, leading to more precise predictions of continuous values such as house prices or stock prices.
- Custom Ensemble Tasks:
Stacking provides a framework for creating highly customized ensembles tailored to specific datasets and problem characteristics. Data scientists can strategically choose base models that are known to perform well on different aspects of the data and then train a meta-learner to weigh their contributions optimally. This flexibility allows for fine-tuning the ensemble's architecture for maximal performance.
- Use in Competitions like Kaggle:
Pursuing marginal performance improvements often leads competitors to build complex stacked ensembles comprising numerous diverse models. Stacking's ability to squeeze out extra predictive power makes it a crucial tool for achieving top rankings.
For example, winning solutions in competitions like the "Home Credit Default Risk" challenge often featured multi-layered stacks combining gradient boosting machines (such as XGBoost and LightGBM), neural networks tailored for tabular data, and regularized linear models like Ridge or Lasso.
The meta-learners in these advanced setups could range from simple linear models to more complex architectures like another layer of gradient boosting or small neural networks, meticulously tuned to blend the unique strengths of the underlying base models optimally.
Performance Gains and Limitations of Stacking
While stacking offers significant potential for performance improvement, it's essential to consider both its advantages and disadvantages:
 Performance Gains and Limitations of Stacking - visual selection (1)-7720c9783d9e430fb5e023b1ba190798.png)
Performance Gains:
- Improved Accuracy/F1 Score: By leveraging the diverse perspectives of multiple models, stacking can often lead to higher accuracy in classification and improved F1 Scores, especially in complex datasets where no single model dominates.
- Reduced Variance: Combining models with different error patterns can help to smooth out individual model instabilities and reduce the overall variance of the ensemble, leading to more consistent predictions on unseen data.
- Reduced Bias: Stacking can help mitigate the inherent bias in individual models by combining models with different inductive biases. For example, combining a high-bias linear model with a low-bias tree-based model can capture more data relationships.
- Enhanced Robustness: Stacked models tend to be more robust to noise and outliers in the data than individual base models, as the meta-learner can learn to discount the predictions of models more susceptible to these issues.
- Better Generalization: The primary goal of stacking is to improve the model's generalization ability, leading to better performance on unseen data compared to the best individual base model.
Limitations:
- Increased Complexity: Stacked ensembles are inherently more complex than individual models or simpler ensemble methods like bagging or boosting. They involve training multiple base models and a meta-learner, making the overall system harder to interpret and debug.
- Longer Training Time: Training a stacked model requires training multiple base models, often with cross-validation, and then training the meta-learner. This can significantly increase the overall training time compared to teaching a single model.
- Potential for Overfitting the Meta-Learner: If the meta-learner is too complex or trained on a small dataset, it may overfit the predictions of the base models on the training data, leading to poor generalization.
- Reduced Interpretability: The final stacked model is often a black box, making it difficult to understand the specific reasons behind its predictions compared to more interpretable individual models.
- Careful Tuning Required: Achieving optimal performance with stacking often requires careful selection of base models, appropriate cross-validation strategies, and tuning of the meta-learner's hyperparameters. An improperly configured stacked model might not offer any performance advantage over the best individual base model.
Also read: 15 Key Techniques for Dimensionality Reduction in Machine Learning
To maximize this powerful technique, it's important to follow certain best practices. Let's explore some key tips for effective stacking in machine learning.
Tips for Effective Stacking in Machine Learning
Stacking blends predictions from various models for superior results. To build powerful and reliable stacked models, focus on these core principles:
- Employ Diverse Base Models: Leverage the unique strengths of different algorithm families (e.g., linear models for simple relationships, tree-based models for non-linearities, and nearest neighbors for local patterns). This variety allows the ensemble to capture a broader range of data characteristics and reduces reliance on the specific biases of a single model type.
- Use Robust Cross-Validation: Implement thorough cross-validation (like K-Fold or Stratified K-Fold) when generating the predictions that train the meta-learner. This ensures that the meta-learner learns how to combine predictions made on data each base model hasn't directly seen during its training phase for those specific predictions, preventing overfitting and providing a more realistic estimate of the stacked model's performance on new data.
- Keep the Meta-Learner Simple: Opt for a less complex algorithm (such as logistic regression for classification or linear regression for regression) as the meta-learner. Its primary role is to learn the optimal weights or combination of the base models' outputs, not to model intricate data patterns itself. A simpler meta-learner is less prone to overfitting the base models' predictions.
- Standardize Inputs When Needed: If your base models include algorithms sensitive to feature scaling (like Support Vector Machines, K-Nearest Neighbors, or Neural Networks), ensure that the input features are standardized or normalized before training. Apply the same scaling to the test data to maintain consistency and prevent certain models from dominating due to feature magnitude differences.
- Monitor Training Resources: Stacking can be computationally intensive due to the training of multiple base models and the meta-learner. Keep track of training time and resource consumption, especially with large datasets or numerous base models. Consider parallelization where feasible and weigh the potential performance gains against the increased computational cost.
Master the fundamentals of building predictive models with upGrad’s course Linear Regression - Step by Step Guide. Develop essential skills in Data Manipulation, Data Cleaning, and Problem Solving—the building blocks of practical analysis.
Quiz: What You Should Know About Stacking Machine Learning
Let's see how well you've grasped stacking concepts in machine learning! Choose the best answer for each question.
1. Which of the following is a primary benefit of using diverse base models in stacking?
a) It speeds up the training process.
b) It ensures all models make the exact predictions.
c) It allows the ensemble to capture different aspects of the data and error patterns.
d) It reduces the number of models needed in the ensemble.
2.What is the critical purpose of using cross-validation when generating training data for the meta-learner in stacking?
a) To optimize the hyperparameters of the base models.
b) To evaluate the final performance of the stacked model on unseen data.
c) To prevent data leakage by ensuring the meta-learner trains on out-of-fold predictions.
d) To reduce the computational cost of training the base models.
3. In the context of stacking, what is the role of the meta-learner?
a) To preprocess the input data for the base models.
b) To select the best-performing base model for the final prediction.
c) To learn the optimal way to combine the predictions of the base models.
d) To train the base models sequentially.
4. Why is using a simpler model as the meta-learner in stacking often recommended?
a) Simpler models train faster.
b) Simpler models are easier to interpret.
c) Simpler models are less prone to overfitting the predictions of the base models.
d) Simpler models always yield better performance.
5. Data leakage in stacking primarily occurs when:
a) The base models are too complex.
b) The meta-learner is trained on predictions made by base models on the same data they were trained on.
c) The cross-validation strategy uses too few folds.
d) The input features are not correctly scaled.
6. Which ensemble method typically involves parallel training base models and then averaging or voting on their predictions, without a meta-learner?
a) Boosting
b) Stacking
c) Bagging
d) Gradient Boosting
7. What data type is generated by the base learners and used as input features to train the meta-learner?
a) The original input features.
b) The true target variables.
c) The predictions of the base models.
d) The error terms of the base models.
8. Which of the following is a potential drawback of using stacking?
a) It always leads to significant performance improvements.
b) It reduces the complexity of the overall model.
c) It can increase training time and reduce interpretability.
d) It is only applicable to classification tasks.
9. When should you consider standardizing input features before applying stacking?
a) Only when using tree-based base models.
b) Only when the target variable is continuous.
c) When some of the base models are sensitive to the scale of the input features (e.g., SVM, KNN).
d) Feature scaling is never necessary for stacking.
10. Stacking can be effectively used for which types of machine learning tasks?
a) Only classification.
b) Only regression.
c) Both classification and regression.
d) Only unsupervised learning.
Also Read: 52+ Must-Know Machine Learning Viva Questions and Interview Questions for 2025
Expert in Machine Learning with upGrad!
To truly master stacking, hands-on experience across diverse projects (classification, regression, clustering, time series) is key. Contributing to open source fosters collaboration and learning. Explore advanced concepts like bagging, boosting, dimensionality reduction, and interpretability, while staying updated with research. Specializing in NLP, computer vision, or healthcare can deepen your expertise.
upGrad equips you with the knowledge and practical skills to effectively implement stacking machine learning and other advanced ensemble techniques to solve complex real-world challenges.
Elevate your machine learning skills and delve into the intricacies of stacking with upGrad's comprehensive programs:
Still feeling overwhelmed by the complexities of advanced machine learning techniques? Connect with our expert counselors to explore the right upGrad program for your career goals and gain personalized guidance! Alternatively, visit one of our conveniently located offline centers to experience our learning environment firsthand.
FAQs
1. Is it always better to have as many diverse base models as possible in a stacking ensemble?
Not necessarily. While diversity is crucial for a strong stacking ensemble, simply adding more models doesn't guarantee better performance. There's a point of diminishing returns. Adding too many redundant or poorly performing models can introduce noise and complexity without significant benefit, potentially leading to overfitting in the meta-learner. The key is to select a set of base models that are diverse in their approaches and reasonably performant individually. Careful validation and evaluation are essential to determine the optimal number and type of base models for your specific problem.
2. How do I choose the number of base models to include in a stacking ensemble?
There's no fixed rule, but it often involves experimentation. Too few base models might not capture sufficient diversity, while too many can lead to increased complexity and potential overfitting. Techniques like cross-validation can help evaluate the performance of the stacked model with varying numbers of base models and identify an optimal balance.
3. What are some common pitfalls to avoid when implementing stacking?
One common pitfall is using base models that are too similar, which reduces the diversity crucial for effective stacking. Another is overfitting the meta-learner, often due to using a too complex model or insufficient data for training it. Proper cross-validation and careful selection of base models and the meta-learner are essential to avoid these issues.
4. How might stacking improve predictive modeling outcomes in a real-world business scenario?
Imagine a marketing team trying to predict which customers will most likely convert after a campaign. Stacking different models trained on various customer features (demographics, browsing history, purchase behavior) can achieve a more robust and accurate prediction than any single model. This leads to more efficient targeting of marketing efforts and a higher return on investment.
5. Does stacking always guarantee better performance than the best individual model?
Not necessarily. While stacking often leads to improved performance by leveraging the strengths of multiple models, it's not guaranteed. If the base models are poorly chosen or the meta-learner is not appropriately trained, the stacked model might underperform the best individual model. Careful selection and tuning are crucial.
6. What kind of meta-learners are typically used in stacking?
Common meta-learners include simpler models like logistic regression for classification or linear regression for regression. However, more complex models like decision trees, support vector machines, or even neural networks can also be used, depending on the complexity of the combined predictions and the amount of training data available for the meta-learner.
7. How does stacking handle imbalanced datasets?
Stacking itself doesn't inherently solve class imbalance. However, you can incorporate techniques for handling imbalanced datasets within the individual base models (e.g., oversampling, undersampling, cost-sensitive learning) and potentially within the training of the meta-learner as well.
8. Can stacking be computationally expensive compared to using a single model?
Yes, stacking can be more computationally expensive as it involves training multiple base models and then the meta-learner. The prediction phase also requires running all the base models before feeding the predictions to the meta-learner. Consider the trade-off between performance gain and computational cost.
9. How do I evaluate the performance of a stacked model?
Standard evaluation metrics relevant to the specific task (e.g., accuracy, precision, recall, F1-score for classification; MAE, MSE, RMSE for regression) are used. It's crucial to perform proper cross-validation, especially nested cross-validation, to estimate the stacked model's generalization performance on unseen data.
10. Are there any open-source libraries that simplify the implementation of stacking?
Yes, several popular machine learning libraries like scikit-learn (with its StackingClassifier and StackingRegressor), MLxtend, and others provide convenient tools and functionalities for implementing stacking ensembles. These libraries often handle the complexities of training and predicting with multiple models.
11. When would it be particularly beneficial to use stacking over other ensemble techniques like bagging or boosting?
Stacking is particularly beneficial when you have a diverse set of well-performing base models that capture different aspects of the data. Unlike bagging (which focuses on reducing variance) and boosting (which focuses on reducing bias), stacking aims to learn the best way to combine the predictions of these diverse models, potentially leading to higher accuracy than either bagging or boosting alone in certain scenarios.





upGrad Learner Support
Talk to our experts. We are available 7 days a week, 10 AM to 7 PM
Indian Nationals
Foreign Nationals
Disclaimer
The above statistics depend on various factors and individual results may vary. Past performance is no guarantee of future results.
The student assumes full responsibility for all expenses associated with visas, travel, & related costs. upGrad does not .