All courses
Agentic AI
Agentic AI
Artificial Intelligence
Degree / Exec. PG

IIIT Bangalore
Executive Diploma in Machine Learning and AI
OPJ Global University
Master’s Degree in Artificial Intelligence and Data Science
Liverpool John Moores University
Master of Science in Machine Learning & AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIExecutive Certificate

IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
IIIT Bangalore
Executive Programme in Generative AI for Leaders
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceOffline Bootcamps

upGrad
Data Science and AI-MLDoctorate
For All Domains
IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
Swiss School of Business and Management
Global Doctor of Business Administration from SSBM
Edgewood University
Doctorate in Business Administration by Edgewood UniversityGolden Gate University
Doctor of Business Administration From Golden Gate University
Rushford Business School
Doctor of Business Administration from Rushford Business School, SwitzerlandGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)-d9bdeff6165f4eb1ba2adcebde78e961.svg)
University of Waterloo
Chief Technology and AI Officer ProgramLeadership / AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIMachine Learning
Machine Learning
Data Science
Degree / Exec. PG
O.P Jindal Global University
Master’s Degree in Artificial Intelligence and Data ScienceIIIT Bangalore
Executive Diploma in Data Science & AILiverpool John Moores University
Master of Science in Data ScienceExecutive Certificate
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceupGrad | Microsoft
Gen AI Mastery Certificate for Content CreationOffline Bootcamps
upGrad
Data Science and AI-MLupGrad
Data AnalyticsMBA
Masters

Paris School of Business
Master of Science in Business Management and TechnologyO.P.Jindal Global University
MBA (with Career Acceleration Program by upGrad)Edgewood University
MBA from Edgewood UniversityO.P.Jindal Global University
MBA from O.P.Jindal Global UniversityGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)Executive Certificate

IMT, Ghaziabad
Advanced General Management ProgramMarketing
Executive Certificate
Offline Bootcamps
upGrad
Digital MarketingManagement
Degree
O.P Jindal Global University
MSc in International Accounting & Finance (ACCA integrated)Paris School of Business
Master of Science in Business Management and Technology
Golden Gate University
Master of Arts in Industrial-Organizational PsychologyExecutive Certificate

IIM Kozhikode
Human Resource Analytics Course from IIM-KupGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftEducation
Education

Northeastern University
Master of Education (M.Ed.) from Northeastern UniversityEdgewood University
Doctor of Education (Ed.D.)Edgewood University
Master of Education (M.Ed.) from Edgewood UniversityCertifications
Project Management
Certification

Knowledgehut
Leadership And Communications In ProjectsKnowledgehut
Microsoft Project 2007/2010-ae8d039bbd2a41318308f8d26b52ac8f.svg)
Knowledgehut
Financial Management For Project ManagersKnowledgehut
Fundamentals of Earned Value Management (EVM)Knowledgehut
Fundamentals of Portfolio ManagementKnowledgehut
Fundamentals of Program Management-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
Knowledgehut
CAPM® CertificationsKnowledgehut
Microsoft® Project 2016Certifications & Trainings
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)
Knowledgehut
PMP® CertificationKnowledgehut
PMI-RMP® CertificationKnowledgehut
PMP Renewal Learning PathKnowledgehut
Oracle Primavera P6 V18.8Knowledgehut
Microsoft® Project 2013Knowledgehut
PfMP® Certification CourseKnowledgehut
Project Planning and MonitoringPrince2 Certifications

Knowledgehut
PRINCE2® FoundationKnowledgehut
PRINCE2® PractitionerKnowledgehut
PRINCE2 Agile Foundation and PractitionerKnowledgehut
PRINCE2 Agile® Foundation CertificationKnowledgehut
PRINCE2 Agile® Practitioner CertificationManagement Certifications
Knowledgehut
Project Management Masters Certification ProgramKnowledgehut
Change ManagementKnowledgehut
Project Management TechniquesKnowledgehut
Product Management Certification ProgramKnowledgehut
Project Risk Management- Study abroad
- Offline centres
- uGSOT - B.Tech
More



49. Variance in ML
What Is Scaling in Machine Learning? Methods, Benefits, and Use Cases
Did you know? Back in the 1960s, researchers discovered that gradient descent struggled to converge efficiently on unscaled data – it was like trying to run a race with one leg! This led to an innovative breakthrough in the 1980s when normalization and standardization techniques were adopted to supercharge model training and make it much more efficient.
Have you ever wondered what is scaling in machine learning and why it is crucial for your models' performance? Scaling refers to the process of standardizing or normalizing the range of features in a dataset to improve model performance and maintain a consistent machine learning structure.
Some of the common scaling methods include normalization and standardization. Applying these techniques can make models converge faster, reduce bias, and achieve more accurate predictions. Scaling is particularly critical in algorithms like SVM, KNN, and neural networks, where the scale of input features directly impacts the algorithm's performance.
In this article, we’ll examine the common methods of scaling in machine learning, how to implement learning procedures in Python, several benefits, use cases, and much more.
If you want to build AI and ML skills to improve your financial analysis capabilities, upGrad’s online AI and ML courses can help you. By the end of the program, you will have all the relevant skills to build AI models, analyze complex data, and solve industry-specific challenges.
What is Scaling in Machine Learning?
Scaling adjusts the range of features in a dataset to ensure consistent influence on machine learning models. Without scaling, features with differing magnitudes may skew model predictions.
Feature transformation through scaling adjusts the range of the data, aligning with the broader machine learning structure and making it much easier for algorithms to interpret and process information effectively.
Scaling ensures that no single feature adversely influences the model, particularly in algorithms that rely on distance calculations or gradient-based optimization methods.
Example:
Consider a linear regression model using gradient descent to minimize the cost function. If the features are unscaled, gradient descent might struggle with convergence because the updates to the weights may be inconsistent. Features with larger ranges will cause larger updates, while smaller features will make tiny adjustments.
- Unscaled data:
Feature 1: "Price" (ranging from 10 to 100,000)
Feature 2: "Age" (ranging from 18 to 70)
In this case, the price feature, due to its larger range, will dominate the weight adjustments, while the age feature will barely influence the model, leading to slower convergence and biased model training.
- Scaled data: Scaling both features ensures that the updates are consistent for all features, allowing gradient descent to converge faster and more reliably, resulting in an optimized model.
- Impact of unscaled data: Unscaled features lead to uneven learning rates for different features, meaning the algorithm may take many more iterations to converge or get stuck in a local minimum. Scaling helps the model learn uniformly across all features.
In 2025, professionals who have a good understanding of machine learning concepts like scaling will be in high demand. If you're looking to develop skills in AI and ML, here are some top-rated courses to help you get there:
- Master's in Artificial Intelligence and Machine Learning
- Executive Diploma in Machine Learning and AI
- Master’s Degree in Artificial Intelligence and Data Science
How Does Scaling in Machine Learning Differ from Normalization and Standardization?
Scaling in machine learning refers to adjusting the range of feature values to ensure consistent input for algorithms. However, it's often confused with normalization and standardization, which are specific types of scaling techniques.
All three techniques aim to prepare data for machine learning models, but they achieve this in different ways. Here’s a look at how they differ:
1. Scaling
Scaling refers to adjusting the data to a specific range, often 0 to 1 or -1 to 1. It's a broad term that includes various techniques, such as Min-Max Scaling and Z-score Standardization.
- Use Case: This is best for distance-based algorithms like KNN or SVM, where the magnitude of features directly influences the model's performance.
- Example: For a dataset with varying scales (e.g., "income" from $20,000 to $100,000 and "age" from 20 to 80), scaling helps prevent the income feature from dominating the distance calculations
2. Normalization
Normalization adjusts the data to fit within a specified range, usually between 0 and 1. It is particularly useful when the data must remain within a specific boundary.
- Use Case: This method is best for neural networks and image processing models that require input values to fall within a range, especially when using activation functions like sigmoid or tanh.
- Example: In neural networks, unnormalized features could cause slow convergence due to the wide range of input values. Min-Max scaling ensures all features are treated equally by normalizing values between 0 and 1.
3. Standardization
Standardization transforms the data by deducting the mean and dividing it by the standard deviation, thereby resulting in a dataset with a mean of 0 and a standard deviation of 1.
- Use Case: This method is best for linear models, logistic regression, and SVMs, where the assumption is that the data is normally distributed. It’s also effective for models like PCA that require data to be centered.
- Example: If the features (e.g., "income" and "age") in a regression model have different units and magnitudes, standardization ensures that the learning process is not dominated by just one feature.
If you want to learn more about linear regression, try upGrad’s free Linear Regression - Step by Step Guide. It will help you build a strong foundation in predictive modeling, and you will learn simple and multiple regression, performance metrics, and applications across data science domains.
Also Read: Mastering Data Normalization in Data Mining: Techniques, Benefits, and Tools
Why Scaling Matters for Machine Learning Algorithms?
Scaling plays a vital role in machine learning as many algorithms depend on scale-sensitive calculations. Algorithms such as Support Vector Machines and K-Nearest Neighbors are particularly sensitive to the scale of input features.
When features aren’t scaled, those with larger ranges or magnitudes can disproportionately influence the model, disrupting the balance of the machine learning structure and leading to biased or incorrect predictions.
Let’s dive into the different algorithms that require scale-sensitive computations and understand why scaling is essential for achieving optimal performance:
1. Support Vector Machines (SVM)
SVM works by identifying the optimal hyperplane that maximizes the separation between classes. It calculates distances between data points to define this hyperplane. If the data is not scaled, features with larger ranges, such as salary versus height, can dominate the margin calculation, resulting in suboptimal classification outcomes.
Impact of Unscaled Data:
The main aim of SVM is to find the optimal hyperplane that separates classes. When data is unscaled, features with larger values dominate the distance calculations, leading to a biased hyperplane. This results in poor classification and suboptimal model performance.
With Scaling:
Scaling ensures that all features contribute equally, enabling SVM to find a better decision boundary and improving classification accuracy.
2. K-Nearest Neighbors (KNN)
KNN is a distance-based algorithm that classifies data points by measuring their proximity to neighboring points. When features aren't scaled, those with larger numerical ranges can dominate the distance calculations, causing incorrect neighbor selection and ultimately leading to misclassification.
Impact of Unscaled Data:
KNN classifies data based on the distance to its neighbors. Without scaling, features with larger ranges (e.g., "income" vs. "age") disproportionately affect the distance metric, leading to incorrect neighbor selection and misclassification.
With Scaling:
Scaling makes sure that all features influence the distance equally, leading to more accurate predictions and better model performance.
3. Gradient Descent
Gradient descent is employed in algorithms like linear regression and neural networks to minimize the cost function. The scale of input features highly influences the optimization process, as the algorithm adjusts weights according to the gradients. If the features are not scaled, this can lead to slow convergence or poor results.
Impact of Unscaled Data:
Gradient descent optimizes the model by adjusting weights based on feature gradients. Unscaled features can cause uneven weight updates, slowing down convergence or causing the algorithm to get stuck in local minima.
With Scaling:
Scaling helps gradient descent converge faster and more reliably by providing consistent gradient updates across all features, leading to quicker optimization.
Also Read: Gradient Descent Algorithm: Methodology, Variants & Best Practices
How Can Unscaled Features Distort Model Training?
Unscaled features can considerably affect the quality of model training and its final performance. If the features aren't scaled, those with larger ranges or values will overpower the model's computations, resulting in skewed predictions and reduced accuracy.
Let’s examine in more detail how unscaled features can affect model training:
- Impact on Distance-Based Algorithms (e.g., KNN, SVM): Algorithms like KNN and SVM rely on calculating the distance between data points. Unscaled features with larger values (like salary vs. age) can adversely influence these distances, leading to incorrect classifications or misidentification of neighbors.
Example: Without scaling, a feature like "salary" (e.g., 50,000) will overshadow "age" (e.g., 25). This causes the model to prioritize salary over age, leading to poor classification or clustering results.
- Slow or Inaccurate Convergence in Gradient Descent: Unscaled features can cause inefficient learning in algorithms like linear regression or neural networks using gradient descent. Large feature values lead to larger gradients, slowing convergence, while smaller values may cause the algorithm to converge too quickly without exploring optimal solutions.
Example: Features with a large scale (e.g., "income" in the thousands) could cause slow gradient updates, delaying convergence or making the training process inefficient.
- Biased Model Performance: Features with larger values or units can dominate the learning process. For instance, a feature like income (in the thousands) can overpower smaller-scale features like age or education level, leading to a model that is biased toward the larger features and resulting in suboptimal performance.
Example: In a logistic regression model, unscaled features might make "income" (in thousands) dominate the learning process, even if "education level" (a smaller-range feature) is more predictive.
- Poor Interpretation of Feature Importance: When features are not scaled, the coefficients or weights assigned to them in linear models or neural networks may not truly represent their significance. This can complicate model interpretation and lead to misleading conclusions about which features are actually influencing the predictions.
Example: In a linear regression model, the coefficient for "income" may appear much higher than that for "age," even though "age" could be more relevant in predicting the outcome.
- Reduced Accuracy and Model Generalization: Models trained with unscaled features may perform well on training data but struggle to generalize to unseen data. This is because the unscaled features may lead to overfitting or poor decision boundaries, limiting the model’s ability to handle new, varied input data effectively.
Example: An unscaled dataset may lead to a model that overfits to features with large ranges, reducing its ability to generalize to unseen data and lowering accuracy on test sets.
Unlock your potential in machine learning with upGrad’s Executive Diploma in Machine Learning and AI. This program offers a hands-on, practical approach to mastering key concepts like SVM and KNN, empowering you to turn theory into impactful real-world solutions. Gain the expertise required to excel in high-demand roles in AI and data science.
Also Read: KNN in Machine Learning: Understanding the K-Nearest Neighbors Algorithm and Its Applications
Now that we've explored the importance of scaling in machine learning, let's examine the common scaling methods and how each technique can be applied to improve model performance.
Common Methods of Scaling in Machine Learning
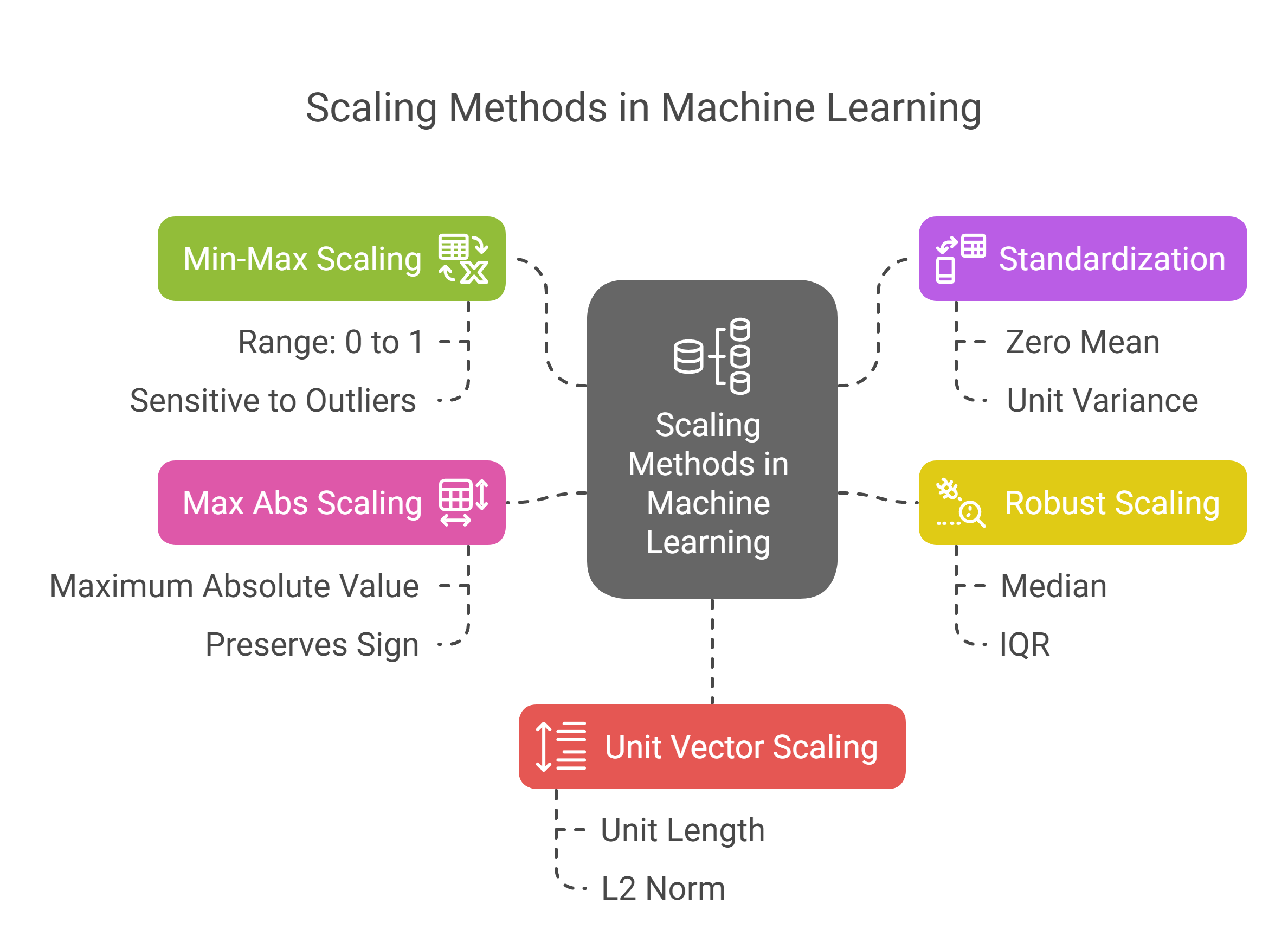
Scaling is a critical step in machine learning, particularly when dealing with algorithms that are sensitive to the magnitude of input features. The choice of scaling method depends on the algorithm you are using and the characteristics of your data, such as the presence of outliers or the distribution of the data.
Here’s a detailed exploration of some of the most commonly used scaling methods:
1. Min-Max Scaling (Normalization)
Min-Max Scaling, also known as normalization, scales the data to a fixed range, usually between 0 and 1. The formula for Min-Max scaling is:
X scaled = max(X)−min(X)X−min(X)
Where min(X) and max(X) are the minimum and maximum values of the feature, respectively.
Min-Max scaling is especially beneficial for neural networks because it ensures that the input data is within a specific range, which can help the activation functions (like sigmoid or tanh) work more effectively.
2. Standardization (Z-Score Scaling)
Standardization, also known as Z-score scaling, transforms features by subtracting the mean and dividing by the standard deviation. This process centers the data at 0, with a standard deviation of 1.
X scaled = σX−μ
Where 𝜇 is the mean and 𝜎 is the standard deviation of the feature.
Standardization ensures that features are centered around zero, thereby making it extremely easy for neural networks to learn the optimal weights. Without standardization, some features may cause the learning process to slow down or lead to poor convergence.
3. Robust Scaling
Robust scaling is a technique specifically designed to manage outliers. Rather than using the mean and standard deviation like standardization, it utilizes the median and interquartile range (IQR) for scaling. The data is adjusted by subtracting the median and dividing by the IQR, which reduces the impact of outliers.
X scaled = IQR(X)−median(X)
Where IQR(𝑋) is the interquartile range and the median (X) is the median of the feature.
This method is particularly effective when the dataset includes extreme values or non-normal distributions, ensuring that outliers don't distort the scaling. When outliers are present, KNN can be significantly impacted, as it is based on distance. Robust scaling ensures that outliers do not overly influence the distance metric, leading to more reliable predictions.
4. Max Abs Scaling
Max Abs Scaling scales the data by dividing each feature by its maximum absolute value, keeping the data's sign intact. This method is particularly useful for data that is already centered around zero and is sparse, such as in text mining or other high-dimensional datasets.
X scaled = max(∣X∣)
Where max(∣X∣) is the maximum absolute value of the feature.
Max Abs Scaling is particularly useful for sparse data where most values are zero, such as in natural language processing (NLP) or text data. It preserves the dataset's sparsity while scaling it to a suitable range for algorithms.
5. Unit Vector Scaling (L2 Norm Scaling)
Unit Vector Scaling, or L2 norm scaling, adjusts feature values so that the sum of their squared values equals 1, effectively placing the data points on a unit sphere. This method is frequently used in algorithms like support vector machines (SVM) and principal component analysis (PCA), which depend on vector operations.
X scaled = ∥X∥ 2
Where ∥𝑋∥2 is the L2 norm (the square root of the sum of squared values).
L2 normalization is ideal when the magnitude of feature vectors is important, but the actual scale is not. This scaling technique is useful when training neural networks, particularly when input data is sparse or has a high number of features, as it reduces the impact of large values and improves convergence.
You can also showcase your experience in advanced machine learning concepts with upGrad’s Professional Certificate Program in Data Science and AI. Along with earning Triple Certification from Microsoft, NSDC, and an Industry Partner, you will build Real-World Projects on Snapdeal, Uber, Sportskeeda, and more.
Also Read: Fraud Detection in Machine Learning: What You Need To Know [2024]
Now that we’ve explored the common scaling methods in machine learning, let’s explore how to implement these scaling techniques efficiently using Python, utilizing popular libraries like scikit-learn.
How to Implement Scaling Techniques in Python?
Implementing scaling techniques in Python is simple, thanks to powerful libraries like scikit-learn. These libraries offer intuitive classes and functions that make it easy to apply various scaling methods to your dataset.
In this section, we’ll walk through the implementation of common scaling methods such as Min-Max Scaling, Standardization, and Robust Scaling using Python. We will also highlight key parameters and outputs for each technique to give you a clear understanding of how scaling adjusts the data.
1. Min-Max Scaling (Normalization): Min-Max Scaling rescales the data to typically [0, 1]. This is helpful for algorithms that require a specific range of input data, such as neural networks or KNN.
Code:
# Importing necessary libraries
from sklearn.preprocessing import MinMaxScaler
import numpy as np
# Sample data
data = np.array([[100, 0.001], [200, 0.005], [300, 0.009]])
# Applying Min-Max Scaling
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(data)
print("Scaled Data (Min-Max Scaling):")
print(scaled_data)
Output:
Scaled Data (Min-Max Scaling):
[[0. 0. ]
[0.5 0.5 ]
[1. 1. ]]
Explanation:
- The MinMaxScaler transforms the features to a [0, 1] range.
- The fit_transform() method first fits the scaler to the data and then applies the transformation.
- The data now lies between 0 and 1, with the smallest value at 0 and the largest at 1.
2. Standardization (Z-Score Scaling): Standardization, also known as Z-score scaling, adjusts the data with a mean of 0 and a standard deviation of 1. This method is commonly applied when the data approximates a Gaussian distribution, ensuring that the features are centered and scaled appropriately for various machine learning algorithms.
Code:
# Importing necessary libraries
from sklearn.preprocessing import StandardScaler
# Sample data
data = np.array([[100, 0.001], [200, 0.005], [300, 0.009]])
# Applying Standardization
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
print("Scaled Data (Standardization):")
print(scaled_data)
Output:
Scaled Data (Standardization):
[[-1.22474487 -1.22474487]
[ 0. 0. ]
[ 1.22474487 1.22474487]]
Explanation:
- The StandardScaler standardizes the data by subtracting the mean and dividing by the standard deviation.
- The mean of the transformed data becomes 0, and the standard deviation becomes 1.
- The fit_transform() method scales the data and returns a centered dataset with equal variance.
3. Robust Scaling: Robust Scaling utilizes the median and interquartile range (IQR) to scale data, making it less sensitive to outliers. This method is particularly effective when dealing with datasets that contain extreme values or outliers, as it prevents them from skewing the scaling process.
Code:
# Importing necessary libraries
from sklearn.preprocessing import RobustScaler
# Sample data with outliers
data = np.array([[100, 0.001], [200, 0.005], [3000, 0.009]])
# Applying Robust Scaling
scaler = RobustScaler()
scaled_data = scaler.fit_transform(data)
print("Scaled Data (Robust Scaling):")
print(scaled_data)
Output:
Scaled Data (Robust Scaling):
[[-0.5 -0.5 ]
[ 0. 0. ]
[ 1.5 1. ]]
Explanation:
- The RobustScaler scales the data using the median and IQR, which is less sensitive to outliers compared to other scaling methods.
- This transformation reduces the impact of extreme values, providing a more stable scaling when outliers are present.
- The scaled data shows that the effect of the extreme value (3000) is minimized.
4. Max Abs Scaling: Max Abs Scaling adjusts each feature by dividing it by its maximum absolute value, preserving the data's sign. This method is often used for sparse datasets centered around zero, ensuring that the scaling does not distort the data's inherent structure.
Code:
# Importing necessary libraries
from sklearn.preprocessing import MaxAbsScaler
# Sample data
data = np.array([[100, 0.001], [200, 0.005], [300, 0.009]])
# Applying Max Abs Scaling
scaler = MaxAbsScaler()
scaled_data = scaler.fit_transform(data)
print("Scaled Data (Max Abs Scaling):")
print(scaled_data)
Output:
Scaled Data (Max Abs Scaling):
[[0.03333333 0.00011111]
[0.06666667 0.00055556]
[0.1 0.00088889]]
Explanation:
- The MaxAbsScaler scales each feature by its maximum absolute value, so all features lie within the range [-1, 1].
- This method retains the data's sparsity, which is useful in applications like text mining or high-dimensional datasets.
- The scaling doesn’t shift or center the data, so it’s well-suited for maintaining the original distribution.
5. Unit Vector Scaling (L2 Norm Scaling): Unit Vector Scaling, or L2 Norm Scaling, transforms the features so that the sum of the squared values of each feature vector equals 1, effectively placing the data points on a unit sphere.
Code:
# Importing necessary libraries
from sklearn.preprocessing import Normalizer
# Sample data
data = np.array([[100, 0.001], [200, 0.005], [300, 0.009]])
# Applying Unit Vector Scaling (L2 Norm Scaling)
scaler = Normalizer(norm='l2')
scaled_data = scaler.fit_transform(data)
print("Scaled Data (Unit Vector Scaling - L2 Norm):")
print(scaled_data)
Output:
Scaled Data (Unit Vector Scaling - L2 Norm):
[[9.99999000e-01 1.00000000e-05]
[9.99999000e-01 2.50000000e-05]
[9.99997000e-01 2.99997000e-05]]
Explanation:
- The Normalizer with norm='l2' scales each row of the data so that the L2 norm (the sum of squares of the vector) equals 1.
- The transformed data has each feature vector with a length (magnitude) of 1, which is especially useful for models that focus on the direction of data vectors, such as when working with high-dimensional data.
- This technique is ideal for text mining and natural language processing (NLP), where the relative direction of data points (not the magnitude) is of importance.
If you want to build a higher-level understanding of Python, upGrad’s Learn Basic Python Programming course is what you need. You will master fundamentals with real-world applications & hands-on exercises. Ideal for beginners, this Python course also offers a certification upon completion.
Also Read: Exploring the Scope of Machine Learning: Trends, Applications, and Future Opportunities
Now that we understand the importance of scaling in machine learning, let's explore how to implement these scaling techniques in Python and the benefits they bring to model performance.
Benefits of Scaling in Machine Learning
Scaling is an essential preprocessing step in machine learning that helps ensure all features contribute equally, boosting model accuracy, convergence speed, and overall performance.
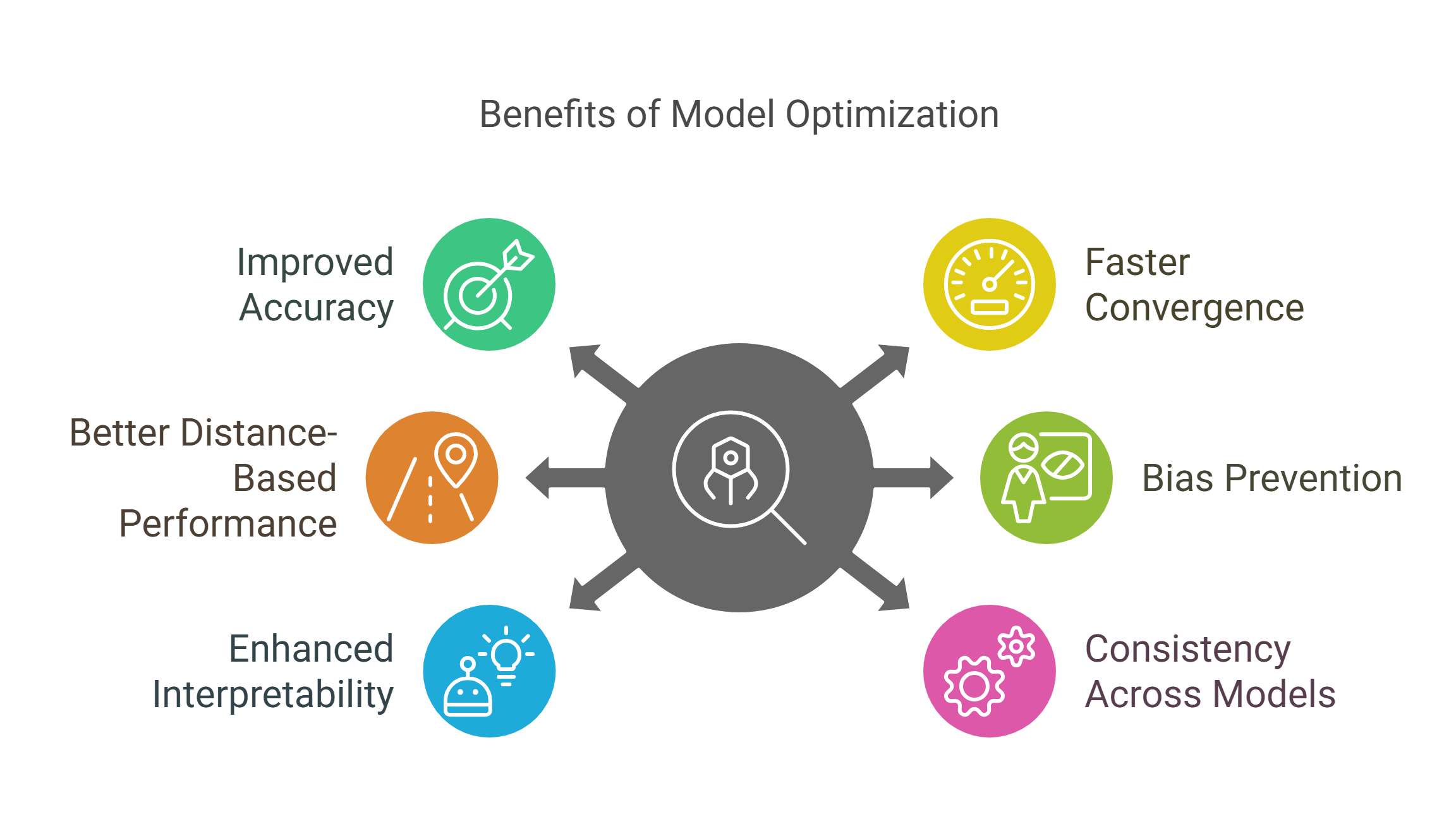
Let’s explore the key advantages of scaling and understand why it plays a vital role in optimizing the training process for machine learning models:
1. Improved Model Accuracy: Scaling enhances model accuracy by ensuring that all features contribute equally to the learning process. When data features are on different scales, models tend to give more weight to features with larger numerical values, which can distort the model's predictions.
For example, in linear regression, the model might focus too much on a feature like "income" (ranging in thousands) over "age" (ranging in single digits), leading to biased results. By scaling the features to a similar range, each feature is treated with equal importance, resulting in more balanced model training.
This improves the overall accuracy, as the model will be able to make more informed predictions based on the full spectrum of features. For instance, models like Support Vector Machines (SVMs) and K-Nearest Neighbors (KNN) benefit significantly from scaling, as it enhances their ability to classify or cluster data points correctly, leading to fewer misclassifications.
2. Faster Convergence in Gradient-Based Algorithms: Scaling plays a crucial role in speeding up the convergence of gradient-based algorithms like Gradient Descent. In machine learning, optimization algorithms, such as linear regression, logistic regression, and neural networks, aim to minimize a loss or cost function.
If the input data is not scaled, the gradient updates become inconsistent across features. Features with larger scales will dominate the gradient updates, resulting in slow convergence or even failure to converge.
By applying scaling techniques such as Standardization, the algorithm converges faster because all features are within similar ranges. This reinforces a stable machine learning structure and allows for more consistent gradient updates. This reduces the number of iterations needed to reach the optimal solution and improves the efficiency of the learning process.
For example, in neural networks, using scaled data can significantly reduce training time while also improving the precision of the model's results.
3. Better Performance for Distance-Based Algorithms: Distance-based algorithms such as K-Nearest Neighbors (KNN), Support Vector Machines (SVM), and K-Means Clustering are highly sensitive to the scale of features because they rely on calculating distances between data points to classify or cluster them. If the features are not scaled, those with larger values dominate the distance calculations, skewing the results.
For example, in KNN, if one feature is much larger in scale than the others, the algorithm may give it more importance, leading to inaccurate neighbor selection and poor classification. Scaling ensures that all features contribute equally to the distance metric, improving the model's performance.
In SVM, scaling helps in finding an optimal hyperplane that better separates the classes, leading to better classification accuracy.
4. Preventing Model Bias: Unscaled data can lead to biased models because features with larger numerical ranges disproportionately influence the model’s training process. For instance, if one feature has a much larger range than others, such as salary vs. age, it can dominate the decision-making process, even though other features may also be critical for making predictions.
Scaling addresses this issue by ensuring that all features are on a similar scale, thereby preventing any single feature from dominating the model’s decision-making. In logistic regression, this helps to avoid bias in feature selection, allowing the model to identify the true relationship between the features and the target variable, which results in more accurate and reliable predictions.
5. Enhanced Interpretability: Scaling enhances the interpretability of machine learning models, particularly in algorithms like Linear Regression and Logistic Regression. When features are scaled, the weights assigned to each feature are more comparable, making it easier to interpret their importance in the model’s predictions.
For example, in a scaled logistic regression model, the coefficients can be compared directly, giving insights into how much each feature influences the target variable. If the features weren’t scaled, the coefficients of features with larger values might dominate, making it harder to draw meaningful conclusions from the model.
Scaled data allows for clearer analysis of feature importance, which is especially valuable in fields like healthcare or finance, where model transparency is critical.
6. Consistency Across Different Models: When working with multiple machine learning models, scaling ensures consistency in the way features are treated. Different algorithms may be sensitive to feature scaling to varying degrees. For example, KNN, SVM, and neural networks require scaling to function optimally, while tree-based models like Decision Trees and Random Forests are not as sensitive to scaling.
By scaling your data upfront, you create a consistent feature space that ensures improved performance across different algorithms. This is especially beneficial when combining models in an ensemble learning approach or when experimenting with various types of models.
Scaling provides a uniform foundation that ensures that the results from different models are comparable, facilitating model selection and boosting overall predictive performance.
Acquiring knowledge and mastering Power BI is crucial, but taking your skills to the next level can set you apart. With upGrad’s Master’s Degree in Artificial Intelligence and Data Science, you'll gain the expertise necessary to drive AI innovation and lead transformative projects in your organization.
Also Read: What is Machine Learning and Why it Matters.
By understanding the key benefits of scaling, we can better appreciate how it directly enhances the performance of various machine learning models. Let’s explore specific use cases where data scaling plays a crucial role in improving model accuracy and efficiency.
Use Cases of Data Scaling in Machine Learning
 (1)-0a86232d209b48bd9e8edde8351a8dd2.png)
Data scaling plays a vital role in machine learning, with diverse applications across various algorithms and industries. By standardizing the scale of features, scaling enhances model efficiency, accuracy, and convergence speed.
In this section, we’ll dive into multiple use cases where data scaling significantly improves model performance and leads to better outcomes.
1. K-Nearest Neighbors (KNN): In KNN, classification is based on the distance between data points. If the features aren’t scaled, those with larger numerical ranges can dominate the distance calculation, leading to misclassifications.
Example:
Imagine you’re building a KNN model to classify species of flowers (e.g., the Iris dataset), where features include petal length, petal width, and sepal dimensions. These features have different units and ranges. Petal length might range from 1 to 6 cm, while petal width ranges from 0.1 to 2.5 cm. Without scaling, KNN will focus more on the feature with the largest range, potentially leading to poor classification.
2. Support Vector Machines (SVM): SVM works by identifying the optimal hyperplane that separates classes based on the distance between data points. Without scaling, features with larger values can skew the model’s calculations, resulting in an inefficient hyperplane.
Example:
Consider a dataset of customer data for churn prediction, with features like "annual income" ranging from USD 20k to USD 100k and "number of service calls" ranging from 1 to 30. In SVM, the decision boundary is defined by the distance between classes, and features with larger scales can dominate the decision-making process.
3. Neural Networks: Neural networks are highly sensitive to the scale of input features. Without scaling, the training process can be slow, inefficient, or even fail to converge due to imbalance in the underlying machine learning structure.
Example:
In a neural network designed for image recognition, pixel values range from 0 to 255. If these values are used directly in the network, they may cause issues in training, especially for activation functions like sigmoid, which is sensitive to large input values.
You can get a better understanding of neural networks with upGrad’s free Fundamentals of Deep Learning and Neural Networks course. Get expert-led deep learning training, hands-on insights, and earn a free certification.
4. Linear and Logistic Regression: In linear and logistic regression, scaling enhances the interpretation of coefficients and accelerates the convergence of gradient-based optimization methods. Without scaling, features with larger values can overshadow others, leading to a biased model that gives disproportionate weight to those features during the learning process.
Example:
In a logistic regression model predicting house prices, features such as "square footage", ranging from 500 to 5,000, and "number of rooms," ranging from 1 to 10, have vastly different scales. The larger feature (square footage) could dominate the optimization process.
5. Principal Component Analysis (PCA): PCA is a technique for dimensionality reduction that relies on the data's variance. If the features are not scaled, those with higher variance will dominate the principal components, distorting the reduction.
Example:
In PCA, which is used for dimensionality reduction, you may have a dataset with features like "annual income" and "age." The "annual income" feature might range from USD 20k to USD 100k, while "age" ranges from 20 to 70. Without scaling, PCA will give more importance to income due to its larger variance, resulting in a distorted principal component.
6. Clustering Algorithms (e.g., K-Means): Clustering algorithms such as K-Means create clusters by determining the distance between data points. Without scaling, features with larger scales can disproportionately influence the clustering process, leading to distorted clusters.
Example:
Consider a dataset of customer behavior with features like "monthly expenditure" ranging from USD 200 to USD 2k and "age" ranging from 18 to 65. Without scaling, K-Means clustering will assign more weight to "monthly expenditure" since it has a wider range, which could lead to misleading cluster centers.
7. Time Series Forecasting: In time series forecasting models, scaling is essential for managing the fluctuating ranges of data over time. Features like seasonal trends, temperature, or stock prices often vary widely in scale, which can introduce bias into predictions. By scaling the data, all features are treated equally, improving the accuracy of the forecasts.
Example:
In time series forecasting, features like "monthly temperature" and "monthly sales" can have vastly different ranges. If the temperature ranges from 0 to 40°C and sales fluctuate between USD 10k and USD 100k, the model may overly rely on sales due to the larger scale.
Also Read: Curse of dimensionality in Machine Learning: How to Solve The Curse?
Now that we’ve explored the key use cases of data scaling in machine learning, it’s important to understand how to choose the right scaling technique based on your data and model requirements.
How to Choose the Right Scaling Technique?
Choosing the right scaling technique is crucial to ensuring that your machine learning model performs optimally. The scaling method you choose should align with the type of algorithm you're using and the characteristics of your data.
In this section of the blog, we’ll explore how to select the appropriate scaling technique based on two key factors: algorithm sensitivity and data distribution/outliers.
1. Based on Algorithm Sensitivity
Different machine learning algorithms have varying sensitivities to the scale of input data. Choosing the right scaling technique ensures that the algorithm performs as intended and produces accurate results.
- Distance-Based Algorithms (e.g., KNN, SVM, K-Means): Algorithms like KNN, SVM, and K-Means rely heavily on distance metrics (like Euclidean distance) for their computations. For these algorithms, Min-Max Scaling or Standardization is recommended, as they bring all features to a comparable scale, preventing any feature from disproportionately affecting the distance calculations.
- Gradient-Based Algorithms (e.g., Neural Networks, Linear/Logistic Regression): Algorithms like neural networks and linear regression use gradient descent for optimization. They are sensitive to the scale of data because large features can dominate the gradient calculations, leading to slower convergence or suboptimal solutions.
- Tree-Based Algorithms (e.g., Decision Trees, Random Forests): Decision trees and ensemble methods like Random Forests are not sensitive to feature scaling. These models make decisions based on feature values, not distance or gradient, so scaling is typically not required. However, scaling might be useful when combining tree-based models with other algorithms in an ensemble.
2. Based on Data Distribution and Outliers
The distribution of your data and the presence of outliers can significantly influence the choice of scaling technique. It's essential to choose a method that aligns with the characteristics of your dataset.
- Normally Distributed Data: If your data is approximately Gaussian or normally distributed, Standardization (Z-score scaling) is the best option. It works well when the data follows a bell curve, as it centers the data around 0 with a standard deviation of 1, making it suitable for algorithms that usually assume distributed features.
- Data with Outliers: When your data contains outliers, techniques like Min-Max Scaling or Standardization can be distorted by extreme values. In this case, Robust Scaling is often more effective, as it uses the median and interquartile range (IQR) to scale the data, making it less sensitive to outliers and ensuring that extreme values do not dominate the scaling.
- Skewed or Non-Normal Data: For data that is skewed or non-normal (e.g., income, population size), Robust Scaling or Log Transformation might be better choices. These techniques help normalize the data by reducing the impact of skewed values and outliers, creating a more even distribution that can improve model performance.
Master Your Scaling Techniques in Machine Learning with upGrad!
Scaling is an essential preprocessing step in machine learning that ensures all features contribute equally to the model’s performance. It improves model accuracy, accelerates convergence, and enhances efficiency, especially for algorithms like KNN, SVM, and neural networks that are sensitive to the scale of input data.
To gain a deeper understanding of scaling techniques and their applications, upGrad offers comprehensive courses that cover machine learning concepts in depth. With hands-on projects and practical insights, upGrad’s programs can help you master scaling techniques and apply them effectively in real-world scenarios.
If you're aiming to build expertise in quantum computing and machine learning, here are some additional highly regarded courses from upGrad to help you on your journey:
- Master's in Artificial Intelligence and Machine Learning
- Master’s Degree in Artificial Intelligence and Data Science
- Professional Certificate Program in Cloud Computing and DevOps
- Generative AI Foundations Certificate Program
- Executive Diploma in Machine Learning and AI with IIIT-B
If you're uncertain about the best path for your career, upGrad’s tailored career guidance will assist you in making informed decisions. Additionally, you can visit the nearest upGrad center to kickstart your hands-on training and begin your journey toward success today!
FAQs
1. What is the main purpose of scaling in machine learning?
The main purpose of scaling in machine learning is to standardize the range of feature values, ensuring that no single feature disproportionately influences the model. It helps algorithms perform more efficiently, improves model accuracy, speeds up convergence, and ensures fair treatment of all features.
2. What is scalable machine learning?
Scalable machine learning refers to the ability to efficiently process and analyze large volumes of data using machine learning algorithms. It involves designing models and systems that can handle increasing data sizes or complexities without compromising performance.
3. What are the uses of scaling techniques?
Scaling techniques standardize the range of features, ensuring fair treatment in machine learning models. They improve the accuracy and performance of algorithms, especially those relying on distance calculations (e.g., KNN, SVM) or gradient descent, by preventing the dominance of features with larger scales or values.
4. How important is scaling?
Scaling is crucial in machine learning because it ensures that all features contribute equally to the model's performance. Without scaling, features with larger ranges can dominate, leading to biased results. Proper scaling improves model accuracy, accelerates convergence, and ensures efficient learning.
5. What are scalable methods in machine learning?
Scalable methods in machine learning allow models to efficiently handle large datasets without compromising performance. These include stochastic gradient descent for optimization, distributed computing for parallel processing, and online education for real-time data processing.
6. How to scale machine learning models?
To scale machine learning models, use techniques like data parallelism to split datasets across multiple processors, model parallelism to divide model computation, and distributed computing for handling large-scale data. Additionally, optimize algorithms with efficient memory and processing techniques, and utilize cloud platforms for scalable infrastructure.
7. Which scaling method is good?
The best scaling method depends on the algorithm and data characteristics. Standardization (Z-score scaling) is ideal for most algorithms, such as SVM and linear regression. Min-Max scaling works well for neural networks and KNN. Robust scaling is best when the data contains outliers. Always consider the model and data distribution.
8. How does machine learning work on a scale?
Machine learning on a scale involves handling large volumes of data efficiently. By utilizing scalable algorithms and distributed computing techniques, models can process and learn from vast datasets. This ensures that performance remains consistent as data grows, enabling faster training, better accuracy, and improved predictions in real-time applications.
9. What are the 3 machine learning models?
The three main types of machine learning models are: Supervised Learning: Models learn from labeled data to make predictions (e.g., linear regression, decision trees).Unsupervised Learning: Models identify patterns in unlabeled data (e.g., clustering, principal component analysis).Reinforcement Learning: Models learn by interacting with an environment and receiving feedback. Supervised Learning: Models learn from labeled data to make predictions (e.g., linear regression, decision trees). Supervised Learning: Models learn from labeled data to make predictions (e.g., linear regression, decision trees). Unsupervised Learning: Models identify patterns in unlabeled data (e.g., clustering, principal component analysis). Unsupervised Learning: Models identify patterns in unlabeled data (e.g., clustering, principal component analysis). Reinforcement Learning: Models learn by interacting with an environment and receiving feedback. Reinforcement Learning: Models learn by interacting with an environment and receiving feedback.
10. What is the formula for scaling?
The general formula for scaling is: New Dimension = Original Dimension * Scale Factor. This formula is used in various applications, including resizing geometric shapes, normalizing data, or adjusting quantities in recipes. It ensures proportional adjustment by multiplying the original value by a constant scale factor.
11. What is overfitting in machine learning?
Overfitting in machine learning occurs when a model learns the details and noise in the training data to the extent that it negatively impacts its performance on new, unseen data. This results in a model that is too complex and fails to generalize well, leading to poor predictions.





upGrad Learner Support
Talk to our experts. We are available 7 days a week, 10 AM to 7 PM
Indian Nationals
Foreign Nationals
Disclaimer
The above statistics depend on various factors and individual results may vary. Past performance is no guarantee of future results.
The student assumes full responsibility for all expenses associated with visas, travel, & related costs. upGrad does not .