All courses
Agentic AI
Agentic AI
Artificial Intelligence
Degree / Exec. PG

IIIT Bangalore
Executive Diploma in Machine Learning and AI
OPJ Global University
Master’s Degree in Artificial Intelligence and Data Science
Liverpool John Moores University
Master of Science in Machine Learning & AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIExecutive Certificate

IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
IIIT Bangalore
Executive Programme in Generative AI for Leaders
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceOffline Bootcamps

upGrad
Data Science and AI-MLDoctorate
For All Domains
IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
Swiss School of Business and Management
Global Doctor of Business Administration from SSBM
Edgewood University
Doctorate in Business Administration by Edgewood UniversityGolden Gate University
Doctor of Business Administration From Golden Gate University
Rushford Business School
Doctor of Business Administration from Rushford Business School, SwitzerlandGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)-d9bdeff6165f4eb1ba2adcebde78e961.svg)
University of Waterloo
Chief Technology and AI Officer ProgramLeadership / AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIMachine Learning
Machine Learning
Data Science
Degree / Exec. PG
O.P Jindal Global University
Master’s Degree in Artificial Intelligence and Data ScienceIIIT Bangalore
Executive Diploma in Data Science & AILiverpool John Moores University
Master of Science in Data ScienceExecutive Certificate
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceupGrad | Microsoft
Gen AI Mastery Certificate for Content CreationOffline Bootcamps
upGrad
Data Science and AI-MLupGrad
Data AnalyticsMBA
Masters

Paris School of Business
Master of Science in Business Management and TechnologyO.P.Jindal Global University
MBA (with Career Acceleration Program by upGrad)Edgewood University
MBA from Edgewood UniversityO.P.Jindal Global University
MBA from O.P.Jindal Global UniversityGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)Executive Certificate

IMT, Ghaziabad
Advanced General Management ProgramMarketing
Executive Certificate
Offline Bootcamps
upGrad
Digital MarketingManagement
Degree
O.P Jindal Global University
MSc in International Accounting & Finance (ACCA integrated)Paris School of Business
Master of Science in Business Management and Technology
Golden Gate University
Master of Arts in Industrial-Organizational PsychologyExecutive Certificate

IIM Kozhikode
Human Resource Analytics Course from IIM-KupGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftEducation
Education

Northeastern University
Master of Education (M.Ed.) from Northeastern UniversityEdgewood University
Doctor of Education (Ed.D.)Edgewood University
Master of Education (M.Ed.) from Edgewood UniversityCertifications
Project Management
Certification

Knowledgehut
Leadership And Communications In ProjectsKnowledgehut
Microsoft Project 2007/2010-ae8d039bbd2a41318308f8d26b52ac8f.svg)
Knowledgehut
Financial Management For Project ManagersKnowledgehut
Fundamentals of Earned Value Management (EVM)Knowledgehut
Fundamentals of Portfolio ManagementKnowledgehut
Fundamentals of Program Management-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
Knowledgehut
CAPM® CertificationsKnowledgehut
Microsoft® Project 2016Certifications & Trainings
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)
Knowledgehut
PMP® CertificationKnowledgehut
PMI-RMP® CertificationKnowledgehut
PMP Renewal Learning PathKnowledgehut
Oracle Primavera P6 V18.8Knowledgehut
Microsoft® Project 2013Knowledgehut
PfMP® Certification CourseKnowledgehut
Project Planning and MonitoringPrince2 Certifications

Knowledgehut
PRINCE2® FoundationKnowledgehut
PRINCE2® PractitionerKnowledgehut
PRINCE2 Agile Foundation and PractitionerKnowledgehut
PRINCE2 Agile® Foundation CertificationKnowledgehut
PRINCE2 Agile® Practitioner CertificationManagement Certifications
Knowledgehut
Project Management Masters Certification ProgramKnowledgehut
Change ManagementKnowledgehut
Project Management TechniquesKnowledgehut
Product Management Certification ProgramKnowledgehut
Project Risk Management- Study abroad
- Offline centres
- uGSOT - B.Tech
More



49. Variance in ML
Comprehensive Guide on Grid Search in Machine Learning
Did you know that the average Machine Learning engineer earns around $133,336 per year? This shows the immense potential the field holds for those seeking lucrative careers in technology and innovation.
Grid search machine learning is a widely used method for tuning hyperparameters, which are key settings that influence how a model learns from data. By systematically evaluating combinations of these parameters, Grid Search helps identify the configuration that delivers the best performance. It is a reliable approach applied across supervised, unsupervised, reinforcement, and deep learning models.
This guide explains the importance of Grid Search, key concepts, how it works, and how to implement it in Python, along with a quiz to test your understanding.
Advance your career with upGrad's specialised AI and Machine Learning programs. Backed by 1,000+ hiring partners and a proven 51% average salary increase, these online courses are built to help you confidently move forward.
What is Grid Search in Machine Learning
Grid Search is a systematic method to identify the best hyperparameters for a machine learning model. Though computationally intensive, Grid Search ensures no potential configuration is overlooked, providing a robust foundation for model optimization.
Grid search guarantees the best model configuration within a defined space, boosting accuracy and reliability. The following are the main reasons why it’s important.
- Boosts Model Accuracy: It thoroughly tests various hyperparameter combinations to pinpoint the best set that enhances validation performance, ensuring the model is finely tuned for precise predictions.
- Automates Parameter Tuning: This process saves you time compared to fiddling with settings manually, as it evaluates combinations automatically. Rather than adjusting one parameter at a time, Grid Search explores every possible combination on its own.
- Ensures Reproducibility: Grid search provides a systematic and clear-cut method for hyperparameter tuning, making it easy to replicate and verify model selection.
- Prevents Under/Overfitting: It fine-tunes the complexity of the model, helping to minimize generalization errors. For example, if you set a high max_depth in a decision tree, it might lead to overfitting; Grid Search assists in finding the optimal value to avoid this issue.
- Improves Comparability: Grid search creates a consistent framework for benchmarking and comparing different models or configurations under the same conditions.
If you're looking to dive deeper into ML AI concepts, tools and frameworks, upGrad offers a wide range of courses designed to familiarize you with all the latest. Enroll in top-rated ML courses and take the next step toward landing your dream job in ML!
- Executive Learning in Machine Learning and AI - IIIT Bangalore
- Master’s Degree in Artificial Intelligence and Data Science
- DBA in Emerging Technologies with Concentration in Generative AI
Understanding the working of grid search vis-a-vis decision tree model helps place it in better context. While Grid Search is more computationally intensive, it provides optimal tuning across models. Decision Trees are less costly to run but rely on well-chosen parameters to balance bias and variance.
Suppose you have a Random Forest model built using the random forest algorithm and are trying to tune it. You might try different values of n_estimators (number of trees) and max_depth (maximum tree depth) to decide which values yield the best accuracy.
It is important to familiarize yourself with certain key terms for grid search in machine learning.
Key Terms for Grid Search in Machine Learning
-16de8c04ab4e46279b5f65e484a271b7.png)
Knowing key terms in Grid Search enhances your ability to use it efficiently, while also helping you make informed decisions when tuning your model. Here are some essential terms you'll come across when diving into Grid Search in machine learning:
- Hyperparameters
Hyperparameters are the settings or configurations of a machine learning model that dictate how it learns and ultimately impacts its performance. Unlike model parameters, which are learned from the data, hyperparameters are set manually before training begins. Selecting the right hyperparameters can greatly affect how well your model performs.
Examples:
- Learning rate: This is the step size used during training to adjust the model's parameters.
- Number of trees (n_estimators): In models like Random Forest or Gradient Boosting, this indicates how many decision trees the algorithm will create.
- Max depth: This refers to the maximum depth allowed for each tree, which influences the model's complexity and its chances of overfitting.
Hyperparameters play a vital role in ensuring that the model strikes the right balance between bias and variance. Grid Search is a handy tool for exploring different values of these hyperparameters to discover the best combination.
- Parameter Grid
A parameter grid is a set range of hyperparameter values that you plan to test during Grid Search. This grid outlines the hyperparameter values and combinations that Grid Search will methodically evaluate.
Examples:
- param_grid = {'n_estimators': [50, 100], 'max_depth': [5, 10]}
- The param_grid includes potential values for hyperparameters like n_estimators (the number of trees) and max_depth (the maximum depth of the trees).
- Grid Search will thoroughly test each combination from the parameter grid, ensuring that the model is assessed under all possible configurations.
- Cross-Validation
Cross-validation is a technique used to evaluate how well a model performs across different data splits. It divides the dataset into several subsets or folds, training the model on some folds while testing it on others. This process is repeated multiple times to ensure a robust assessment of the model's performance.
The most popular technique out there is k-fold cross-validation. In this method, we split the dataset into k subsets and then train and validate the model k times. Each time, we use a different subset for validation.
With these key terms in mind, let’s explore how Grid Search actually works to optimize model performance.
How Grid Search in Machine Learning Works?
Grid Search in machine learning takes a thorough and methodical approach to optimizing hyperparameters, making sure that no possible combination is missed. This extensive testing helps pinpoint the best model setup for enhanced performance.
-a76e76fb54614cbaa39d74473a8a3e72.png)
Let’s break down how grid search works in machine learning step by step.
1. Define the Model: Choose the Machine Learning Model You Want to Optimize
Before diving into grid search, the first step is to select the machine learning model you’re working with. Some popular options include:
- Support Vector Machine (SVM)
- XGBoost
- Random Forest
The choice of machine learning model is crucial for hyperparameter optimization because different models have unique hyperparameters, and the range of these values directly impacts their performance and the search space for Grid Search. Your choice of model will depend on the specific problem you’re tackling, whether it’s classification, regression, or something else.
Once you’ve settled on a model, you can use grid search to pinpoint the best hyperparameters that will help your model perform better. For instance, if you’re using a Random Forest model, grid search can assist you in determining the ideal number of trees or the optimal depth of those trees.
2. Set Hyperparameter Grid: Specify the Hyperparameters and Their Corresponding Values to Test
In Grid Search, you need to create a "grid" of hyperparameters, which are the values you want to explore for different model configurations. These values can have a significant impact on how well your model performs.
To make sure everything is properly evaluated, Grid Search employs cross-validation, which tests every combination across various data splits. This approach gives you a clearer picture of how well the model performs and helps minimize the risk of overfitting. Ultimately, this leads to a more trustworthy selection of the best hyperparameters.
For example, if you’re working with a Random Forest model, you might want to test:
- Number of trees (n_estimators): How many decision trees should be in the forest? The possible values could be 50, 100, or 200.
- Maximum depth (max_depth): How deep should each tree be allowed to grow? You might consider depths of 3, 5, or 7.
- Learning rate (learning_rate): This parameter controls how much the model adjusts with each training step. You could test values like 0.01, 0.1, or 1.
Here’s a quick example of how you might set up the grid in Python:
```python
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [3, 5, 7],
'learning_rate': [0.01, 0.1, 1]
}
Grid search will then evaluate each combination of these hyperparameters, allowing you to find the best settings for your model.
Output:
(50, 3, 0.01)
(50, 3, 0.1)
(50, 3, 1)
(50, 5, 0.01)
(50, 5, 0.1)
(50, 5, 1)
(50, 7, 0.01)
(50, 7, 0.1)
(50, 7, 1)
(100, 3, 0.01)
(100, 3, 0.1)
(100, 3, 1)
(100, 5, 0.01)
(100, 5, 0.1)
(100, 5, 1)
(100, 7, 0.01)
(100, 7, 0.1)
(100, 7, 1)
(200, 3, 0.01)
(200, 3, 0.1)
(200, 3, 1)
(200, 5, 0.01)
(200, 5, 0.1)
(200, 5, 1)
(200, 7, 0.01)
(200, 7, 0.1)
(200, 7, 1)
These 27 combinations represent all possible pairs of the hyperparameters n_estimators, max_depth, and learning_rate in the grid, and will be tested during Grid Search.
3. Model Training: Training and Evaluating the Model with Each Set of Hyperparameters
Once you have the hyperparameter grid ready, grid search begins to train the model for every possible combination of those hyperparameters. Each time, the model undergoes training using cross-validation, which is a method that divides the training data into several subsets. This way, the model gets tested on different data each time, helping to ensure that its performance remains consistent and doesn’t just fit perfectly to one specific subset of data. After training, you get to evaluate how well the model performs using a validation set or through cross-validation, giving you insight into how it might handle new, unseen data.
4. Evaluate Performance: Recording Performance Metrics for Each Combination
Once each model configuration has been trained, grid search takes note of how each combination of hyperparameters performed. Typically, you need to look at a few key performance metrics, such as:
- Accuracy: This tells us how many predictions the model got right out of all the predictions it made. It’s like checking how many answers you got right on a quiz.
- Precision: This indicates how many of the positive predictions the model made were actually correct. Think of it as predicting “yes” on a survey. Precision reveals how many of those “yes” responses were indeed true.
- Recall: This measures the model’s ability to spot all the actual positive cases. It can be compared to a treasure hunt wherein you’re expected to recall how many treasures the model discovered out of all the hidden ones.
- F1 Score: This is a balance between precision and recall, and it’s particularly useful when you want to ensure we’re getting positive results right while also not missing any. It’s especially handy when the data is skewed, like having a lot more “no” answers than “yes” ones.
- Log Loss: This metric gauges how confident the model is in its predictions. A lower log loss means the model is more certain about its predictions, much like how confidently you’d place a bet on an answer in a quiz.
All these metrics are documented for each combination, and the aim is to compare the performance across different setups to pinpoint which one works best.
5. Select Best Hyperparameters: Choosing the Top Performers
After evaluating all the combinations, grid search picks out the hyperparameters that delivered the best performance based on your chosen metric, such as the highest accuracy or precision. This final selection rests on which combination scored the highest across all the tested hyperparameter setups. GridSearchCV automatically refits the model using the best-selected hyperparameters, ensuring that the final model is optimized for performance.
For instance, if a specific combination of n_estimators = 100, max_depth = 5, and learning_rate = 0.1 yields the best results, those hyperparameters would be deemed the optimal settings for our model.
Let’s look at how to implement grid search in Python using popular libraries like scikit-learn.
Grid Search in Machine Learning Using Python
GridSearchCV is a grid search machine learning utility in scikit-learn that thoroughly explores the best hyperparameter combinations for a specific model. It lets you thoroughly explore the best combinations of hyperparameters for a specific model. By defining a range of values for each hyperparameter, GridSearchCV evaluates every possible combination and picks the one that performs the best according to a chosen scoring method. This approach fits seamlessly into machine learning workflows, as it helps fine-tune models for peak performance.
-1c751682c0eb4237bb9b63b48c405e06.png)
Here’s a simple step-by-step guide to using grid search in Python with GridSearchCV from sklearn.
Step 1 – Import Libraries
First, we need to bring in the essential libraries. Although not used in this instance, pandas and numpy are commonly used to prepare and manage data before carrying out a grid search.
# Import necessary libraries
import pandas as pd
import numpy as np
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
- pandas: Python library used to handle and analyze data with functions like dropna() that remove rows with missing values.
- numpy: Python library used for numerical operations. An example is use of conditional logic using numpy.where() to clean array data.
- sklearn: Contains GridSearchCV and the tools for building models and evaluating them.
- RandomForestClassifier: Refers to the model that needs to be optimized.
- load_iris: A built-in sample dataset from sklearn for testing.
- train_test_split: Splits the data into training and testing sets.
- Classification_report: Evaluates the model’s performance.
Step 2 – Load Data
Next, we’ll load a demo dataset. In this case, we’ll use the Iris dataset, which is a simple dataset for classification. It will help demonstrate the load data process.
# Load the Iris dataset
data = load_iris()
# Split the dataset into features (X) and target (y)
X = data.data
y = data.target
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
- X contains the feature data (flower attributes like sepal length, sepal width, etc.).
- Y contains the target data (species of the flower).
- train_test_split splits the data into training (70%) and testing (30%) sets.
Step 3 – Define the Model and Hyperparameters
In this step, we’re going to outline the model we want to fine-tune along with the hyperparameters we aim to optimize. For this, we’re using the RandomForestClassifier, which is a well-known method in ensemble learning.
# Define the model
rf_model = RandomForestClassifier(random_state=42)
# Define hyperparameters to tune
param_grid = {
'n_estimators': [50, 100, 200], # Number of trees in the forest
'max_depth': [3, 5, 7], # Maximum depth of the tree
'min_samples_split': [2, 5, 10] # Minimum samples required to split an internal node
}
- n_estimators: The number of trees in the forest.
- max_depth: The maximum depth of the trees, which controls overfitting.
- min_samples_split: The minimum number of samples required to split a node.
These are just a few hyperparameters for demonstration purposes; you can tune other parameters based on your model.
Step 4 – Perform Grid Search
Now, let's dive into using GridSearchCV to carry out our grid search. We’ll provide the model, the parameter grid, and also set some extra options like cross-validation (cv) and the scoring metric (scoring).
# Perform grid search with cross-validation
grid_search = GridSearchCV(estimator=rf_model, param_grid=param_grid, cv=5, scoring='accuracy')
# Fit the grid search to the training data
grid_search.fit(X_train, y_train)
- cv=5: This indicates 5-fold cross-validation. The training set is split into 5 subsets, and the model is trained and validated 5 times.
- scoring='accuracy': We use accuracy as the evaluation metric for model performance.
- fit: Fits the model to the training data and performs the grid search.
GridSearchCV will now test all possible combinations of the hyperparameters in the param_grid and evaluate them based on accuracy.
Become and expert in ML and AI with an advanced, Advanced Generative AI Certification Course, offering 10+ GenAI tools and 6+ industry-relevant projects. Don’t let this chance to add to your skillset and elevate your career in ML technologies slip by!
Step 5 – Refit the Best Model After Grid Search
After performing grid search, it’s essential to retrain the model on the entire training dataset using the best-found hyperparameters. This ensures the final model leverages all available data and is ready for predictions or further evaluation. In scikit-learn’s GridSearchCV, this is handled automatically when refit=True.
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
# Assume X_train, y_train are prepared and param_grid is defined
grid_search = GridSearchCV(RandomForestClassifier(), param_grid, scoring='f1', cv=5, refit=True)
grid_search.fit(X_train, y_train)
# The best estimator is refit on the whole training set
best_model = grid_search.best_estimator_
predictions = best_model.predict(X_test)
Sample Output:
Best Parameters: {'max_depth': 10, 'n_estimators': 100}
Predictions on Test Set: [1 0 0 1 1 0 1 0 1 0]
The best_params_ attribute shows you the hyperparameter combination that achieved the highest cross-validation score. The best_estimator_ is the model that has been refitted using the entire training set with those selected parameters. Predictions represent the class labels that your model has predicted for the test data, and they’re all set for further evaluation or deployment.
This refitting step is crucial because it ensures that your final model is as strong and accurate as possible, making the most of all the training data available.
Step 6 – Output Results
Once the grid search is complete, you can view the best hyperparameters and the performance score associated with those hyperparameters.
# Display the best hyperparameters and the best score
print(f"Best hyperparameters: {grid_search.best_params_}")
print(f"Best score: {grid_search.best_score_}")
# Use the best model to predict on the test set
best_model = grid_search.best_estimator_
y_pred = best_model.predict(X_test)
# Evaluate the model performance
print(classification_report(y_test, y_pred))
After you've implemented Grid Search and fine-tuned your model, it's really important to take a step back and assess the pros and cons that this approach brings to the table.
Benefits of using Grid Search in Machine Learning
-3c029cf447624e6095aa3290d7645aee.png)
Grid search machine learning is a powerful way to fine-tune hyperparameters, helping businesses improve model performance and achieve more reliable results. By automating the testing of different hyperparameter combinations, grid search ensures that finding the best settings for your model is not left to chance. This means your model can be both accurate and efficient, ultimately leading to more successful machine learning projects.
Its key benefits include the following.
- Comprehensive Hyperparameter Exploration:
Grid search thoroughly examines every possible hyperparameter combination, ensuring that no potential optimal configuration gets missed.
- Automates Model Tuning:
By taking the manual labor out of the equation, grid search streamlines the search for the best parameters, saving you time and minimizing the chance of human error.
- Improved Model Accuracy:
With grid search, fine-tuning hyperparameters means your model can reach its peak performance, resulting in greater accuracy and reliability.
- Reproducible Results:
Grid search delivers consistent and repeatable outcomes, making it easier to compare different model setups and choose the best one.
- Better Resource Allocation:
Grid search helps you allocate resources more effectively by focusing on the most relevant hyperparameters, which enhances overall testing efficiency and cost-effectiveness.
As is to be expected, the use of grid search in machine learning is not without its fair share of challenges.
Challenges of Using Grid Search
Understanding the challenges that come with grid search is crucial for maximizing its effectiveness and overcoming any limitations. Here are a few of the key hurdles you might face.
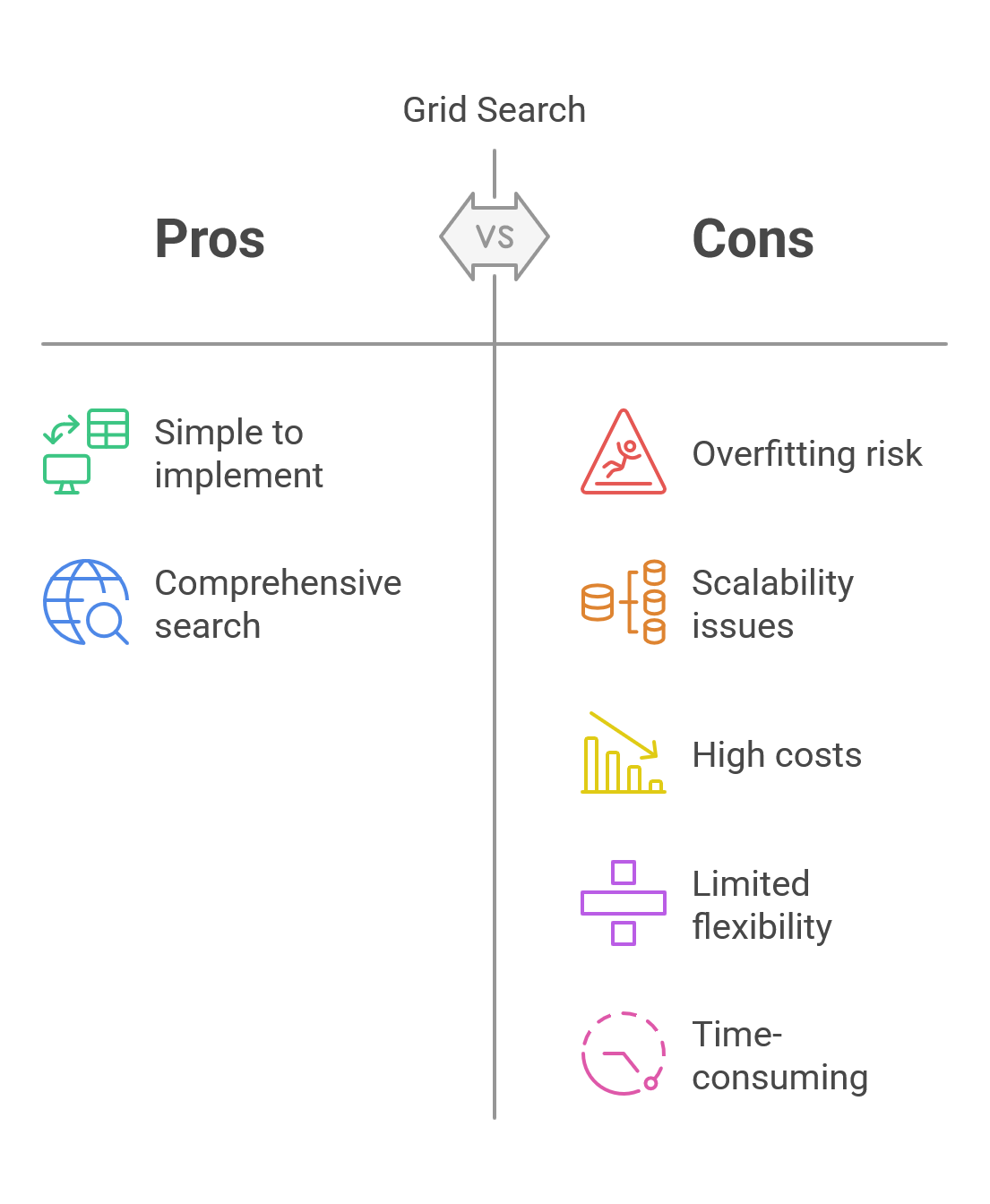
- High Computational Cost:
Grid search examines every possible combination of hyperparameters, which can significantly strain your computational time and resources.
- Scalability Issues:
As you add more hyperparameters and their potential values, the number of combinations can skyrocket, making the whole process less manageable.
- Risk of Overfitting:
Without proper cross-validation, grid search runs the risk of overfitting to the training data, which can result in poor performance on new, unseen data.
- Limited Flexibility in Search:
Grid search relies on a set grid of hyperparameters, which means it might overlook better options that lie outside the chosen range.
- Time-Consuming with Large Datasets:
When dealing with large datasets or complex models, grid search can become sluggish and inefficient, taking a considerable amount of time to test all the combinations.
Elevate your skills with upGrad's Job-Linked Data Science Advanced Bootcamp. With 11 live projects and hands-on experience with 17+ industry tools, this program equips you with certifications from Microsoft, NSDC, and Uber, helping you build an impressive AI and machine learning portfolio.
Next, let's dive into how grid search compares with other hyperparameter optimization techniques.
Choosing the Right Hyperparameter Tuning Strategy: Grid Search vs. the Rest
-536f378a4ee0413fb1b32de19cc6668a.png)
Curious whether to use grid search machine learning or try other hyperparameter tuning techniques like random search or Bayesian optimization? Here’s a comparison table that contrasts Grid Search with other popular hyperparameter tuning strategies, such as Random Search and Bayesian Machine Learning, highlighting their key features and differences.
Hyperparameter Tuning Strategy | Description | Advantages | Disadvantages |
Grid Search | An exhaustive method that tests all combinations of hyperparameters from a predefined grid. |
|
|
Random Search | Randomly samples hyperparameters from a predefined range of values. |
|
|
Bayesian Optimization | Uses probabilistic models to find the best hyperparameters by predicting the performance of different values. |
|
|
Genetic Algorithms | Uses evolutionary processes to iteratively improve the set of hyperparameters. |
|
|
Hyperband | A resource allocation technique that fine-tunes hyperparameters by utilizing early stopping. |
|
|
Now that we've taken a look at how Grid Search stacks up against other tuning methods, it's time to see how well you've grasped the concepts with a quick set of multiple-choice questions on Grid Search.
Quiz to Test Your Knowledge on Grid Search in Machine Learning
Put your knowledge of Grid Search in machine learning to the test with this quick quiz! Answer the questions to see how well you understand how Grid Search operates and its role in optimizing models.
1. What’s the main goal of Grid Search in machine learning?
A) To pick the best dataset for training
B) To fine-tune hyperparameters for improved model performance
C) To find the best model for classification
D) To carry out feature engineering
2. What’s a downside of using Grid Search?
A) It guarantees the best model will be found
B) It can be computationally heavy, especially with numerous hyperparameters
C) It doesn’t test every combination of hyperparameters
D) It doesn’t need any computational resources
3. What exactly is a hyperparameter in machine learning?
A) Parameters that are learned from the data
B) Settings that guide the model’s learning process
C) Parameters that can’t be altered during training
D) Metrics used to assess model performance
4. In Grid Search, what does the “cv” parameter refer to?
A) The type of model being used
B) The number of iterations in the search
C) The type of hyperparameters to optimize
D) The number of folds in cross-validation
5. What’s a valid alternative to Grid Search for optimizing hyperparameters?
A) Bayesian Optimization
C) Linear Programming
6. Which of the following isn’t a key parameter in the Grid Search process?
A) Hyperparameter grid
B) Cross-validation strategy
C) Model architecture
D) Scoring metric
7. In Grid Search, what does the "scoring" parameter indicate?
A) The time it takes to train the model
B) The data used for validation
C) The metric for evaluating model performance
D) The number of hyperparameters to test
Conclusion
Grid Search is a core machine learning technique for systematically identifying the best hyperparameters to enhance model performance. As ML evolves, it's increasingly integrated into AutoML systems and hybrid optimization methods, enabling it to handle larger datasets, complex models, and real-time tasks.
This growing adaptability positions Grid Search as a key tool for scalable, efficient tuning in areas like healthcare, edge computing, and generative AI. To stay current and learn advanced tuning strategies, explore upGrad’s specialized machine learning courses.
Learn from industry experts through hands-on projects, while working on real-world case studies with the following courses in ML for enterprise-grade applications.
- Masters in Artificial Intelligence & Machine Learning
- Generative AI Foundations Certificate Program
- Learn Python Libraries: NumPy, Matplotlib & Pandas
Feeling a bit lost on which course to pick? upGrad is here to help with personalized counseling that guides you toward the ideal career path. Swing by our offline centers for expert advice, whether you're a student or a working professional looking to level up!
FAQs
1. How can grid search handle categorical hyperparameters in practical ML projects?
Categorical hyperparameters can be added to the parameter grid as discrete options, such as kernel type or criterion. When these are model inputs, use label encoding or one-hot encoding to convert categories into numerical form. For instance, setting kernel=['linear', 'rbf'] in SVM will allow the grid to test both variations. Ensure encoding happens inside a pipeline so the transformations apply consistently across cross-validation splits, avoiding leakage or inconsistencies.
2. What limitations does grid search face in high-dimensional hyperparameter spaces?
Grid search becomes inefficient as the number of hyperparameters increases. A grid with five parameters and five values each would result in 3,125 combinations. Testing each one can become computationally intensive. This leads to long runtimes and high resource usage, especially with complex models. In such scenarios, alternatives like random search or Bayesian optimization are more efficient, as they reduce search space coverage while still yielding good performance outcomes.
3. Should data preprocessing steps be included within the grid search pipeline?
Yes, always integrate preprocessing steps into a single pipeline before performing grid search. This ensures consistent transformation across training folds during cross-validation. For example, using Pipeline() in scikit-learn lets you apply scaling, encoding, or imputation only to training data inside each fold, preventing leakage. Skipping this integration can lead to inflated scores and misleading conclusions. Always encapsulate the full workflow—from raw data to model fitting—in the grid search process.
4. How can I speed up grid search through parallelization in real projects?
Most implementations, like GridSearchCV in scikit-learn, support parallelization through the n_jobs parameter. Setting n_jobs=-1 allows the search to use all CPU cores, significantly reducing evaluation time. For large-scale experiments, you can distribute jobs across clusters using libraries like Dask or run on cloud infrastructure. This is especially useful when training time per model is high. Always monitor system memory and CPU usage to avoid bottlenecks while parallelizing.
5. How does grid search help ensure models generalize to unseen data?
Grid search uses cross-validation, typically k-fold, to evaluate each hyperparameter combination across multiple splits of the training data. This reveals how consistently the model performs and prevents over-reliance on any single fold. The selected configuration is one that performs well across all splits, not just one. As a result, the chosen model generalizes better to unseen data, which is crucial for robust performance in production settings.
6. What metrics should I use for evaluating grid search when working with imbalanced datasets?
For imbalanced datasets, accuracy is often misleading. Use metrics like F1-score, precision, recall, or AUC depending on the context. For instance, in fraud detection, precision is important to minimize false alarms, while recall matters in disease diagnosis. Set these as the scoring parameter in GridSearchCV to ensure appropriate model selection. Always validate these metrics on a separate holdout set to confirm their relevance outside the cross-validation loop.
7. How do I decide which hyperparameter values to include in the grid and their step size?
Start broad with a wide range of values to understand the general trend. For example, test max_depth=[3, 5, 10, 20] instead of small steps. Once promising regions are identified, refine the search with finer granularity like max_depth=[8, 10, 12]. Use previous experiments, model documentation, and domain knowledge to guide selection. Avoid too many combinations early on, especially with limited computational resources. Prioritize impactful hyperparameters first.
8. Can I use grid search on custom models not built with scikit-learn?
Yes, as long as your custom model follows the scikit-learn API with fit() and predict() methods. You can create a wrapper class that exposes these methods, making the model compatible with GridSearchCV. This allows you to apply grid search to models built using Keras, XGBoost, or any in-house code. Ensure the wrapper also supports scoring and accepts parameter dictionaries. This makes tuning more flexible for non-standard models.
9. In terms of efficiency, how does grid search compare to random search in real scenarios?
Grid search checks every combination within the defined grid, which ensures optimal selection but is slow with large grids. Random search, on the other hand, samples a fixed number of combinations, often finding good results faster. For example, when tuning three parameters with ten values each, grid search tests 1,000 combinations while random search may test just 100. In high-dimensional spaces, random search is more efficient without sacrificing much accuracy.
10. What are common mistakes to avoid when applying grid search in ML workflows?
Avoid using too wide or irrelevant hyperparameter ranges. Failing to wrap preprocessing into the pipeline can lead to data leakage. Using only accuracy as the metric, especially on imbalanced datasets, results in poor model selection. Also, not setting refit=True after the best model is found can miss the final training step. Always cross-validate properly and choose performance metrics that align with business goals and dataset characteristics.
11. Can I apply grid search to unsupervised learning tasks like clustering or dimensionality reduction?
Yes, grid search can be used for unsupervised tasks, but the evaluation requires different metrics. For clustering, use silhouette score, Davies–Bouldin index, or Calinski–Harabasz score. For dimensionality reduction, explained variance or reconstruction error are more appropriate. These metrics guide hyperparameter selection in the absence of labels. Ensure consistent evaluation across folds, especially when input features vary after dimensionality reduction or transformation during the grid search process.





upGrad Learner Support
Talk to our experts. We are available 7 days a week, 10 AM to 7 PM
Indian Nationals
Foreign Nationals
Disclaimer
The above statistics depend on various factors and individual results may vary. Past performance is no guarantee of future results.
The student assumes full responsibility for all expenses associated with visas, travel, & related costs. upGrad does not .