All courses
Agentic AI
Agentic AI

IIIT Bangalore
Executive Programme in Generative AI for LeadersArtificial Intelligence
Degree / Exec. PG

IIIT Bangalore
Executive Diploma in Machine Learning and AI
OPJ Global University
Master’s Degree in Artificial Intelligence and Data Science
Liverpool John Moores University
Master of Science in Machine Learning & AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIExecutive Certificate

IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership ProgrammeIIIT Bangalore
Executive Programme in Generative AI for Leaders
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceOffline Bootcamps

upGrad
Data Science and AI-MLDoctorate
For All Domains
IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
Swiss School of Business and Management
Global Doctor of Business Administration from SSBM
Edgewood University
Doctorate in Business Administration by Edgewood UniversityGolden Gate University
Doctor of Business Administration From Golden Gate University
Rushford Business School
Doctor of Business Administration from Rushford Business School, SwitzerlandGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)-d9bdeff6165f4eb1ba2adcebde78e961.svg)
University of Waterloo
Chief Technology and AI Officer ProgramLeadership / AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIMachine Learning
Machine Learning
Data Science
Degree / Exec. PG
O.P Jindal Global University
Master’s Degree in Artificial Intelligence and Data ScienceIIIT Bangalore
Executive Diploma in Data Science & AILiverpool John Moores University
Master of Science in Data ScienceExecutive Certificate
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceupGrad | Microsoft
Gen AI Mastery Certificate for Content CreationOffline Bootcamps
upGrad
Data Science and AI-MLupGrad
Data AnalyticsMBA
Masters

Paris School of Business
Master of Science in Business Management and TechnologyO.P.Jindal Global University
MBA (with Career Acceleration Program by upGrad)Edgewood University
MBA from Edgewood UniversityO.P.Jindal Global University
MBA from O.P.Jindal Global UniversityGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)Executive Certificate

IMT, Ghaziabad
Advanced General Management ProgramMarketing
Executive Certificate
Offline Bootcamps
upGrad
Digital MarketingManagement
Degree
O.P Jindal Global University
MSc in International Accounting & Finance (ACCA integrated)Paris School of Business
Master of Science in Business Management and Technology
Golden Gate University
Master of Arts in Industrial-Organizational PsychologyExecutive Certificate

IIM Kozhikode
Human Resource Analytics Course from IIM-KupGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftEducation
Education

Northeastern University
Master of Education (M.Ed.) from Northeastern UniversityEdgewood University
Doctor of Education (Ed.D.)Edgewood University
Master of Education (M.Ed.) from Edgewood UniversityCertifications
Project Management
Certification

Knowledgehut
Leadership And Communications In ProjectsKnowledgehut
Microsoft Project 2007/2010-ae8d039bbd2a41318308f8d26b52ac8f.svg)
Knowledgehut
Financial Management For Project ManagersKnowledgehut
Fundamentals of Earned Value Management (EVM)Knowledgehut
Fundamentals of Portfolio ManagementKnowledgehut
Fundamentals of Program Management-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
Knowledgehut
CAPM® CertificationsKnowledgehut
Microsoft® Project 2016Certifications & Trainings
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)
Knowledgehut
PMP® CertificationKnowledgehut
PMI-RMP® CertificationKnowledgehut
PMP Renewal Learning PathKnowledgehut
Oracle Primavera P6 V18.8Knowledgehut
Microsoft® Project 2013Knowledgehut
PfMP® Certification CourseKnowledgehut
Project Planning and MonitoringPrince2 Certifications

Knowledgehut
PRINCE2® FoundationKnowledgehut
PRINCE2® PractitionerKnowledgehut
PRINCE2 Agile Foundation and PractitionerKnowledgehut
PRINCE2 Agile® Foundation CertificationKnowledgehut
PRINCE2 Agile® Practitioner CertificationManagement Certifications
Knowledgehut
Project Management Masters Certification ProgramKnowledgehut
Change ManagementKnowledgehut
Project Management TechniquesKnowledgehut
Product Management Certification ProgramKnowledgehut
Project Risk Management- Study abroad
- Offline centres
- uGSOT - B.Tech
More
%20(1)-d5498f0f972b4c99be680c2ee3b792d7.svg)




49. Variance in ML
Epoch in Machine Learning Explained: Meaning, Role, and Why It Matters in ML
Did You Know? In machine learning, training a model for around 50 epochs often yields diminishing returns, where further epochs result in only slight improvements. However, over 100 epochs can lead to overfitting, where the model memorizes the training data and performs poorly on new, unseen data. This is why finding the sweet spot with techniques like early stopping is crucial to avoid overtraining.
An epoch in machine learning is one full cycle through the training dataset during model training. It helps the model adjust weights to reduce error, which highlights what are epochs in machine learning as key to performance optimization. The number of epochs affects performance, where too few can cause underfitting and too many may lead to overfitting.
Epochs are crucial in applications like image recognition, NLP, and speech processing. This tutorial explains the epoch meaning in machine learning, their role in training, and how to choose the right number for better model accuracy.
Build expert skills with upGrad's AI and ML Courses, designed by top 1% global universities. Specializing in Data Science, Deep Learning, NLP, and more. Learn core topics like epoch in machine learning and apply them in industry settings.
What Is Epoch in Machine Learning? Definition and Importance
An epoch in machine learning refers to one complete pass through the entire dataset during training, where the model processes every example and adjusts its parameters based on feedback from its predictions.
It is crucial to understand the epoch meaning in machine learning and how it affects model training. To learn effectively, models typically require multiple epochs in ML, as each pass refines the model's ability to generalize and predict accurately.
More epochs improve model performance, reinforcing why understanding epoch machine learning is essential for training stability and generalization, though the optimal number depends on the complexity of the model and dataset.
For more in-depth insights into machine learning and AI, consider exploring the following programs to sharpen your skills:
- Master's in Artificial Intelligence and Machine Learning
- Executive Diploma in Machine Learning and AI
- Executive Post Graduate Certificate Programme in Data Science & AI

The number of epochs in machine learning affects how well a model learns. Neural networks often require 20 to 100 epochs, while simpler models like linear regression need fewer. Ensemble methods gain accuracy through repeated training rounds. The learning rate is also crucial. A higher rate speeds up training but may cause instability, while a lower rate ensures stable but slower progress.
Task type influences epoch count. Complex classification problems or deep learning regression need more epochs. Each epoch helps the model adjust weights, improve predictions, and maintain a balance between underfitting and overfitting.
Now that we've defined what is epoch in machine learning and why it's important, let's explore how epochs contribute to the overall training process and model performance.
Also Read: Top 5 Machine Learning Models Explained For Beginners
Why Epoch Matters in ML Model Training?
Epochs are fundamental to how well a machine learning model learns from data, converges toward optimal performance, and generalizes to unseen inputs. Each epoch provides a chance for parameter adjustment, which ties into what Is epoch in machine learning and its impact on model convergence.
How Epochs Contribute to Learning Stability and Generalization:
- Each epoch improves model performance by iteratively minimizing loss.
- Too few epochs can lead to underfitting, where the model fails to capture important data patterns.
- Too many epochs can cause overfitting, where the model memorizes training data instead of generalizing.
- The learning rate works in tandem with epochs. A high rate may need fewer epochs but risks instability, while a low rate requires more epochs for smoother convergence.
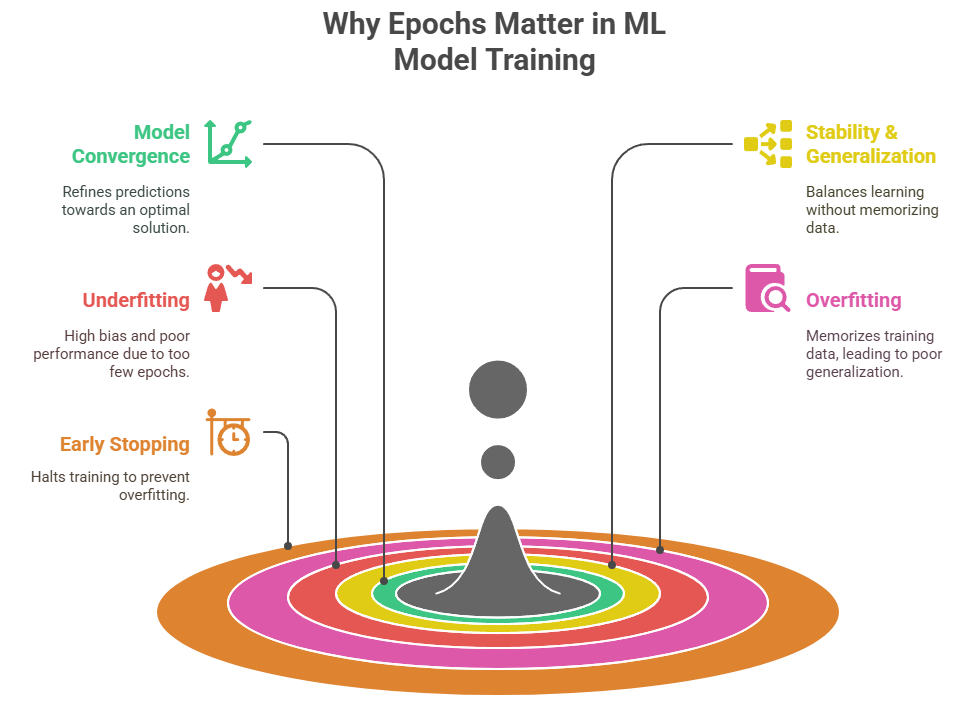
Underfitting vs. Overfitting and the Role of Epochs
Choosing the right number of epochs is key to model performance and reflects a deep understanding of epoch machine learning principles. This balance ensures the model neither underfits nor overfits the data.
Risks of Improper Epoch Count:
- Underfitting: Happens with too few epochs; the model doesn’t learn enough.
- Overfitting: Happens with too many epochs; the model memorizes training data, harming generalization.
Best Practices to Avoid Over/Underfitting:
- Monitor both training and validation loss.
- Use early stopping to halt training when validation loss stops improving.
- Adjust the learning rate and batch size alongside epochs for optimal tuning.
Managing Epochs: Early Stopping and Monitoring Validation Loss
Monitoring model performance during training is essential, often using early stopping to avoid underfitting and overfitting. This technique halts training when the model's performance on the validation set stops improving, preventing overfitting.
- Validation Loss Monitoring: If validation loss increases while training loss decreases, it signals overfitting. Monitoring this trend helps decide whether to stop early or continue training.
- Patience for Early Stopping: Early stopping includes a “patience” parameter, which specifies how many additional epochs the model can train without improvement before halting. Setting the right patience value is crucial—too low, and the model stops prematurely; too high, and overfitting may occur. Typically, patience values range from 3 to 10 epochs, depending on the dataset.
- Hyperparameter Tuning: Combining early stopping with hyperparameter tuning, such as grid search or random search, helps find the optimal number of epochs. Adjusting parameters like learning rate and batch size alongside early stopping can ensure the best performance without overtraining.
Here’s a table showing what are epochs in machine learning and how they affect training loss and validation loss. This will help you understand the progression of model training:
Epoch Number | Training Loss | Validation Loss | Model State |
1 | High | High | Underfitting |
5 | Lower | Moderate | Optimizing |
15 | Very Low | Plateaued/Increase | Potential Overfitting |
25 | Low | High | Overfitting |
Key Takeaways:
- Too few epoch in machine learning can lead to underfitting, where the model doesn’t learn enough from the data.
- Too many epochs in ML can cause overfitting, where the model becomes overly specialized to the training data.
- Early stopping and monitoring validation loss allow you to balance the training process, improving model performance without overtraining.
Practical Tips:
- Use early stopping to stop training when the validation loss stops improving.
- Monitor both training loss and validation loss to determine when the model is at risk of overfitting.
- Combine early stopping with hyperparameter tuning using grid or random search to find your model's best epoch in ML settings.
Once you’ve mastered these techniques, the next step is determining the optimal number of epochs based on your model’s requirements and data.
Advance your ML career with the Executive Diploma in Machine Learning and AI with IIIT-B and upGrad. Get trained in a comprehensive curriculum covering Cloud Computing, Big Data, Deep Learning, Gen AI, NLP, and MLOps. Build strong fundamentals like epochs in machine learning to ensure your models learn, converge, and generalize effectively.
Setting Epoch Values: How Many Epochs Are Enough?
Choosing the correct number of epoch in machine learning for training your model is crucial and can directly impact the model's performance. Epoch in ML represents one complete pass through the entire dataset, and selecting too few epochs may lead to underfitting, while too many could cause overfitting.
The ideal number of epoch in machine learning depends on several factors, including dataset size, model complexity, and learning rate. Let’s take a detailed look at each:
- Dataset Size:
Larger datasets typically require more epochs to ensure the model effectively learns all data patterns.
For tasks like image or text classification, datasets with around 100,000 samples often need between 50 and 100 epochs to generalize well. In contrast, smaller datasets, such as those with 10,000 samples, need fewer epochs to avoid overfitting while still capturing the essential features.
The number of epochs is also task-dependent, with image and text classification tasks often requiring more epochs due to the complexity of the patterns involved. While more epochs help larger datasets generalize better, too many epochs on smaller datasets can lead to overfitting, where the model becomes too specialized to the training data.
- Model Complexity
The complexity of the model plays a significant role in determining the number of epochs needed for training. Deep neural networks (DNNs), with their multiple layers and numerous parameters, require more epochs to converge, typically ranging from 50 to 150 epochs.
On the other hand, simpler models such as linear regression or decision trees generally need fewer epochs, often under 50, to achieve optimal performance. Complex models require more epochs to adjust the many weights across layers and effectively learn from the data, while simpler models can converge more quickly due to fewer parameters.
Also Read: Deep Learning vs Neural Networks: What’s the Difference?
- Learning Rate
The learning rate influences how many epochs are needed for effective model training. A high learning rate enables larger weight adjustments, often requiring fewer epochs, but it can cause the model to overshoot the optimal solution. Conversely, a low learning rate necessitates more epochs as it makes smaller adjustments, allowing for stable convergence without overshooting.
Example:
A learning rate of 0.01 may require fewer epochs, while a learning rate of 0.001 typically needs more epochs to fine-tune the model effectively.
To dive deeper into the fundamentals, consider exploring the Fundamentals of Deep Learning and Neural Networks course. This program covers the architecture of neural networks, inspired by the human brain, and provides a solid foundation in AI-driven models. Whether new to AI or looking to upskill, it offers basic and advanced techniques for mastering deep learning.
Guidelines for Choosing Epoch Values
To determine the correct number of epoch in machine learning, consider factors like empirical testing, cross-validation, and early stopping to prevent overfitting. Understanding what epochs are in machine learning helps in adjusting for model complexity and dataset size.
1. Empirical Testing
Start by training the model with various epoch values and monitor the training and validation losses over time. This will help you visually identify when the model is beginning to overfit (when the validation loss starts to increase) or underfit (when the training loss remains high despite additional epochs).
- Track how the loss values change during training to gauge the optimal epoch number.
- Example: In image classification, you might observe that while training loss decreases steadily, the validation loss flattens after a certain point, signaling that further epochs won't yield much improvement.
2. Cross-Validation
Cross-validation involves splitting the dataset into multiple folds, training on each fold, and evaluating performance to check how well the model generalizes. This method helps determine the ideal number of epochs, balancing the need for model accuracy without overfitting.
- Use cross-validation to test multiple epochs on different subsets of the data for a more reliable measure of model performance.
- Example: In time-series forecasting, more epochs might be needed due to sequential dependencies, while in classification tasks with structured data, fewer epochs may suffice.
3. Grid/Random Search
Grid and random search techniques allow you to systematically explore different combinations of epoch values along with other hyperparameters like learning rate and batch size. This approach helps find the optimal setup for improved performance.
- These methods work well when testing different epoch values alongside other key parameters to refine your model's performance.
- Example: In CNN-based image classification, grid search can help fine-tune the number of epochs and learning rate for the most optimal setup, improving model efficiency.
As you refine your model, mastering epoch machine learning implementation in tools like TensorFlow and PyTorch becomes essential for real-world success.
Also Read: Top 15 Deep Learning Frameworks You Need to Know in 2025
Epoch in Machine Learning: Practical Implementation Tips
 Epoch in Machine Learning_ Practical Implementation Tips - visual selection-0f2f0589da1b428dac1163d3871aaec4.png)
When implementing epoch in machine learning, setting the right number of passes through the training dataset is essential for achieving optimal model performance. The process of configuring epochs differs based on the machine learning framework you're using, such as TensorFlow or PyTorch. This section will explore practical ways to set and monitor epochs while working with simple models and common datasets.
How do we set epochs in TensorFlow and PyTorch?
Setting the number of epochs correctly ensures that your model learns effectively. Here are examples of how to set epochs in TensorFlow/Keras and PyTorch, explaining each step and the rationale behind it. We will demonstrate this using basic models and synthetic datasets to show the process clearly.
1. TensorFlow/Keras Example: Model.fit()
To start, let’s examine how epochs are handled in TensorFlow. The following code sets up a simple model with 10 epochs, trains it on a dummy dataset, and displays the training and validation metrics at each epoch.
import tensorflow as tf
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# Generate a dummy dataset
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Build a simple MLP model
model = Sequential([
Dense(64, input_dim=20, activation='relu'),
Dense(32, activation='relu'),
Dense(1, activation='sigmoid')
])
# Compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model for 10 epochs
history = model.fit(X_train, y_train, epochs=10, validation_data=(X_test, y_test))
# Display the loss and accuracy over epochs
print(history.history['loss'])
print(history.history['accuracy'])
Output:
Epoch 1/10
25/25 ━━━━━━━━━━━━━━━━━━━━ 4s 12ms/step - accuracy: 0.6136 - loss: 0.6523 - val_accuracy: 0.8250 - val_loss: 0.5017
Epoch 2/10
25/25 ━━━━━━━━━━━━━━━━━━━━ 1s 11ms/step - accuracy: 0.8138 - loss: 0.4755 - val_accuracy: 0.8350 - val_loss: 0.4035
Epoch 3/10
25/25 ━━━━━━━━━━━━━━━━━━━━ 0s 14ms/step - accuracy: 0.8419 - loss: 0.3727 - val_accuracy: 0.8300 - val_loss: 0.3705
Epoch 4/10
25/25 ━━━━━━━━━━━━━━━━━━━━ 0s 11ms/step - accuracy: 0.8458 - loss: 0.3563 - val_accuracy: 0.8350 - val_loss: 0.3585
Epoch 5/10
25/25 ━━━━━━━━━━━━━━━━━━━━ 0s 11ms/step - accuracy: 0.8447 - loss: 0.3333 - val_accuracy: 0.8400 - val_loss: 0.3567
Epoch 6/10
25/25 ━━━━━━━━━━━━━━━━━━━━ 1s 11ms/step - accuracy: 0.8881 - loss: 0.2625 - val_accuracy: 0.8400 - val_loss: 0.3596
Epoch 7/10
25/25 ━━━━━━━━━━━━━━━━━━━━ 0s 9ms/step - accuracy: 0.8573 - loss: 0.3071 - val_accuracy: 0.8350 - val_loss: 0.3562
Epoch 8/10
25/25 ━━━━━━━━━━━━━━━━━━━━ 0s 8ms/step - accuracy: 0.8739 - loss: 0.2775 - val_accuracy: 0.8450 - val_loss: 0.3567
Epoch 9/10
25/25 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.9115 - loss: 0.2363 - val_accuracy: 0.8550 - val_loss: 0.3569
Epoch 10/10
25/25 ━━━━━━━━━━━━━━━━━━━━ 0s 8ms/step - accuracy: 0.8884 - loss: 0.2688 - val_accuracy: 0.8450 - val_loss: 0.3559
[0.6056856513023376, 0.4496045410633087, 0.3756351172924042, 0.3386367857456207, 0.31940457224845886, 0.3050905168056488, 0.29119133949279785, 0.28094273805618286, 0.26918426156044006, 0.26122114062309265]
[0.6700000166893005, 0.8187500238418579, 0.8387500047683716, 0.8537499904632568, 0.8537499904632568, 0.8550000190734863, 0.8675000071525574, 0.8774999976158142, 0.893750011920929, 0.887499988079071]
Explanation:
- epochs=10: This argument defines the number of times the model will process the entire dataset. Each epoch represents a complete pass through all training data, where the model updates its weights based on the loss function.
- model.fit(): This function is where training happens. It runs for the defined number of epochs, adjusting weights in every iteration. The validation_data parameter ensures that the model’s performance is evaluated on unseen data after each epoch.
The output will show how the loss and accuracy change with each epoch, indicating whether the model is improving and how it generalizes to the validation data.
2. PyTorch Example: train() Loop
Next, let’s explore how to implement epochs in PyTorch. PyTorch requires more manual setup compared to TensorFlow. Here’s how you would implement epochs and train a simple model using PyTorch:
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from torch.utils.data import DataLoader, TensorDataset
# Generate a dummy dataset
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Convert data to tensors
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.float32).view(-1, 1)
X_test_tensor = torch.tensor(X_test, dtype=torch.float32)
y_test_tensor = torch.tensor(y_test, dtype=torch.float32).view(-1, 1)
# Define a simple MLP model
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.fc1 = nn.Linear(20, 64)
self.fc2 = nn.Linear(64, 32)
self.fc3 = nn.Linear(32, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.sigmoid(self.fc3(x))
return x
# Initialize the model, loss function, and optimizer
model = MLP()
loss_fn = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Train the model for 10 epochs
for epoch in range(10):
model.train()
optimizer.zero_grad()
output = model(X_train_tensor)
loss = loss_fn(output, y_train_tensor)
loss.backward()
optimizer.step()
# Print loss for every epoch
print(f'Epoch {epoch+1}/{10}, Loss: {loss.item()}')
Output:
Epoch 1/10, Loss: 0.6873610019683838
Epoch 2/10, Loss: 0.6817536950111389
Epoch 3/10, Loss: 0.6761901378631592
Epoch 4/10, Loss: 0.6706458926200867
Epoch 5/10, Loss: 0.6651002764701843
Epoch 6/10, Loss: 0.6595401763916016
Epoch 7/10, Loss: 0.6539290547370911
Epoch 8/10, Loss: 0.6482622027397156
Epoch 9/10, Loss: 0.6425193548202515
Epoch 10/10, Loss: 0.6366933584213257
Explanation:
- For epoch in range(10): This loop runs 10 times, where each iteration corresponds to an epoch. In each epoch, the model processes the training data, computes the loss, and adjusts the weights using backpropagation.
- optimizer.zero_grad() and optimizer.step(): These functions clear previous gradients and apply the gradient updates after each backpropagation step.
The loss is printed after each epoch to observe how it decreases, indicating that the model is learning.
Also read: Machine Learning Tutorial: Learn ML from Scratch
Monitoring Training Performance Over Epochs
Tracking performance over multiple epochs is key to understanding if the model is learning effectively. It’s important to monitor both training and validation loss/accuracy. Below, we’ll demonstrate how to visualize these metrics using Matplotlib or Seaborn in both frameworks.
1. TensorFlow: Monitoring Loss and Accuracy
Below is the code to plot training and validation loss in TensorFlow/Keras after each epoch.
import matplotlib.pyplot as plt
# Plot training & validation loss
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.title('Training and Validation Loss Over Epochs')
plt.show()
Output:
-6be198c88ffe4b138eec834f433e6414.png)
Explanation:
- Plotting the loss: The graph shows how the model’s training and validation loss evolve over epochs. This helps visually inspect whether the model is underfitting (high loss), optimizing (decreasing loss), or overfitting (validation loss increases while training loss decreases).
- The history.history object tracks the loss and accuracy at each epoch, making it easy to visualize the model's learning progress.
2. PyTorch: Monitoring Loss and Implementing Early Stopping
Now let’s look at how we can monitor loss in PyTorch and implement early stopping to avoid overfitting.
import matplotlib.pyplot as plt
# Initialize lists to store loss values
train_losses = []
# Train the model for 10 epochs, manually logging the loss
for epoch in range(10):
model.train()
optimizer.zero_grad()
output = model(X_train_tensor)
loss = loss_fn(output, y_train_tensor)
loss.backward()
optimizer.step()
train_losses.append(loss.item())
print(f'Epoch {epoch+1}/{10}, Loss: {loss.item()}')
# Plot the training loss across epochs
plt.plot(train_losses, label='Training Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.title('Training Loss Over Epochs')
plt.show()
Output:
Epoch 1/10, Loss: 0.6362267136573792
Epoch 2/10, Loss: 0.6295813918113708
Epoch 3/10, Loss: 0.6228248476982117
Epoch 4/10, Loss: 0.6159353852272034
Epoch 5/10, Loss: 0.6089053153991699
Epoch 6/10, Loss: 0.6017091274261475
Epoch 7/10, Loss: 0.5943432450294495
Epoch 8/10, Loss: 0.5867988467216492
Epoch 9/10, Loss: 0.5790607929229736
Epoch 10/10, Loss: 0.5711707472801208
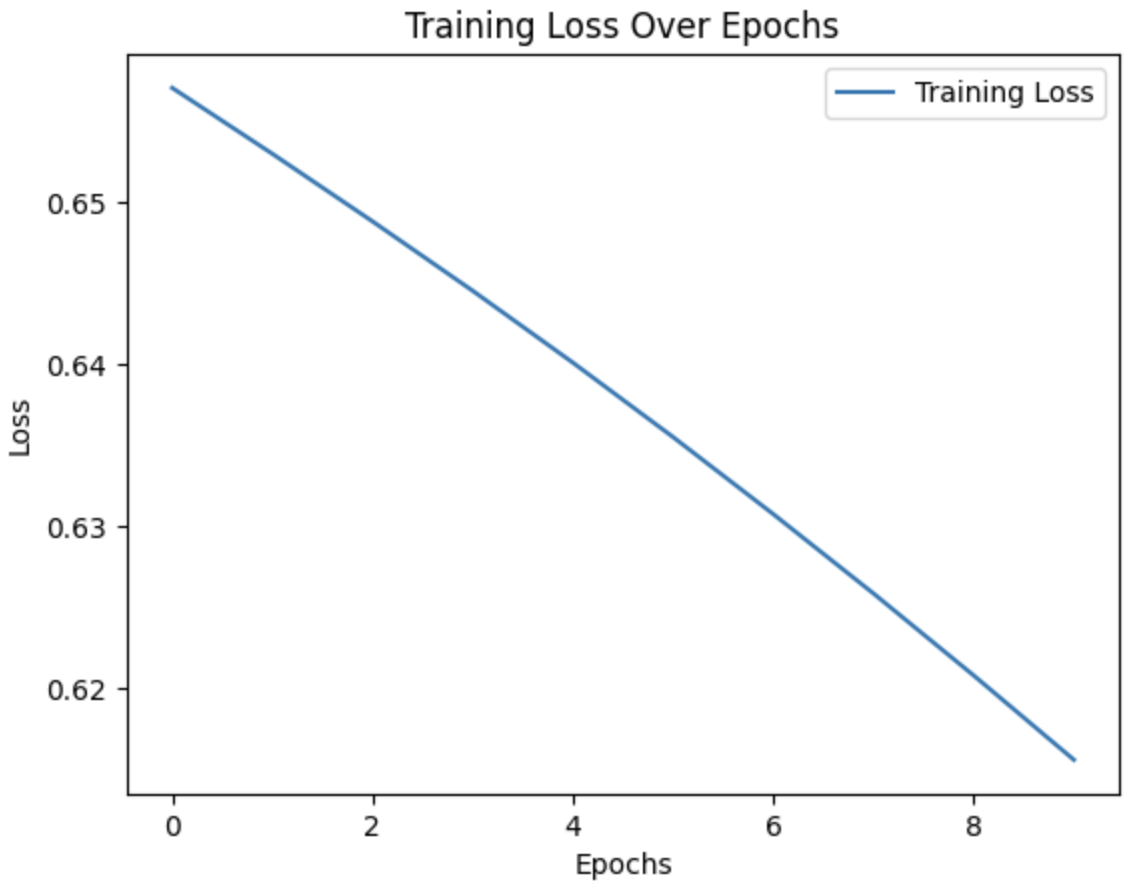
Explanation:
- This code tracks the training loss after each epoch, storing the values in train_losses and then plotting them to visualize how the model’s loss decreases over time.
- Early stopping: Implementing early stopping would prevent the model from continuing to train if the validation loss doesn’t improve, saving computational resources and preventing overfitting.
3. Early Stopping in TensorFlow:
TensorFlow and PyTorch offer different ways to implement early stopping.
from tensorflow.keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(monitor='val_loss', patience=3, restore_best_weights=True)
# Train with EarlyStopping callback
history = model.fit(X_train, y_train, epochs=50, validation_data=(X_test, y_test), callbacks=[early_stopping])
Explanation:
EarlyStopping Callback: This callback monitors the validation loss and stops training if there is no improvement after a specified number of epochs (patience). This ensures that training halts when the model is no longer improving.
Expected Output: During the training, TensorFlow will print out the loss for each epoch, including both the training loss and the validation loss. The output will look something like this:
Epoch 1/50
32/32 [==============================] - 1s 15ms/step - loss: 0.6943 - val_loss: 0.6932
Epoch 2/50
32/32 [==============================] - 1s 15ms/step - loss: 0.6930 - val_loss: 0.6925
Epoch 3/50
32/32 [==============================] - 1s 15ms/step - loss: 0.6924 - val_loss: 0.6921
Epoch 4/50
32/32 [==============================] - 1s 15ms/step - loss: 0.6922 - val_loss: 0.6919
Epoch 5/50
32/32 [==============================] - 1s 15ms/step - loss: 0.6919 - val_loss: 0.6920
Epoch 6/50
32/32 [==============================] - 1s 15ms/step - loss: 0.6920 - val_loss: 0.6921
After several epochs (based on the patience=3), if the validation loss does not improve, training will stop early. For example, if the validation loss stops improving after 3 epochs, the output will look something like this:
Epoch 10/50
32/32 [==============================] - 1s 15ms/step - loss: 0.6918 - val_loss: 0.6922
Epoch 11/50
32/32 [==============================] - 1s 15ms/step - loss: 0.6917 - val_loss: 0.6923
Early stopping triggered at epoch 11
Note: The model will stop training after the 11th epoch because the validation loss did not improve for 3 consecutive epochs (patience=3).
Once the early stopping condition is triggered, the training will halt, and the model will restore the weights from the epoch with the best validation loss (due to restore_best_weights=True).
The history object will contain the training and validation loss for each epoch, which you can use for plotting or analysis:
history.history['loss'] # Training loss over epochs
history.history['val_loss'] # Validation loss over epochs
The model will train for a few epochs and then stop early if the validation loss does not improve for 3 consecutive epochs, as specified by the patience=3 parameter in the EarlyStopping callback.
4. PyTorch Early Stopping:
In PyTorch, we can implement early stopping manually by monitoring the validation loss during training:
import torch
import torch.nn as nn
import torch.optim as optim
# Define a simple neural network model
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(10, 64) # 10 input features, 64 output units
self.fc2 = nn.Linear(64, 2) # 64 input units, 2 output classes
def forward(self, x):
x = torch.relu(self.fc1(x)) # Apply ReLU activation
x = self.fc2(x) # Output layer
return x
# Create a model instance
model = SimpleModel()
# Define an optimizer and loss function
optimizer = optim.SGD(model.parameters(), lr=0.01)
loss_fn = nn.CrossEntropyLoss()
# Define the early stopping parameters
best_val_loss = float('inf')
patience = 3
epochs_without_improvement = 0
# Example data (dummy data for the purpose of the example)
X_train_tensor = torch.randn(100, 10) # 100 samples, 10 features
y_train_tensor = torch.randint(0, 2, (100,)) # 100 samples, binary labels (0 or 1)
X_test_tensor = torch.randn(20, 10) # 20 test samples
y_test_tensor = torch.randint(0, 2, (20,)) # 20 test labels (0 or 1)
# Training loop with early stopping
for epoch in range(50):
model.train() # Set the model to training mode
optimizer.zero_grad() # Clear gradients
output = model(X_train_tensor) # Forward pass
loss = loss_fn(output, y_train_tensor) # Calculate loss
loss.backward() # Backpropagate
optimizer.step() # Update model parameters
# Validation step (use validation data)
model.eval() # Set the model to evaluation mode
with torch.no_grad(): # Disable gradient calculation during validation
val_output = model(X_test_tensor) # Forward pass on test data
val_loss = loss_fn(val_output, y_test_tensor) # Calculate validation loss
print(f'Epoch {epoch+1}, Training Loss: {loss.item()}, Validation Loss: {val_loss.item()}')
# Early stopping check
if val_loss < best_val_loss:
best_val_loss = val_loss
epochs_without_improvement = 0
else:
epochs_without_improvement += 1
if epochs_without_improvement >= patience:
print("Early stopping")
break
Output:
Epoch 1, Training Loss: 0.6889626383781433, Validation Loss: 0.7165713310241699
Epoch 2, Training Loss: 0.6863915324211121, Validation Loss: 0.7165313959121704
Epoch 3, Training Loss: 0.6839296817779541, Validation Loss: 0.7165387272834778
Epoch 4, Training Loss: 0.681571364402771, Validation Loss: 0.7165896892547607
Epoch 5, Training Loss: 0.6793110370635986, Validation Loss: 0.7166805863380432
Early stopping
Explanation:
- This code demonstrates early stopping in both TensorFlow and PyTorch, halting training when the model's performance on the validation set stops improving for a specified number of epochs (patience).
- The plot helps visualize how the loss decreases over time, giving insights into whether early stopping should have been triggered.
By implementing and monitoring these training processes, you can ensure your model trains effectively, prevents overfitting, and converges to the optimal solution.
Get hands-on with training machine learning models by learning the fundamentals of machine learning. upGrad’s Deep Learning and Neural Networks course will guide you through concepts like epochs, loss tracking, and early stopping to improve model efficiency and prevent overfitting. Perfect for those looking to excel in AI and machine learning roles!
Also Read: Types of Machine Learning Algorithms with Use Cases and Examples
Let’s now address some of the common misunderstandings that can arise when working with epoch in machine learning.
Common Misunderstandings About Epochs in Machine Learning
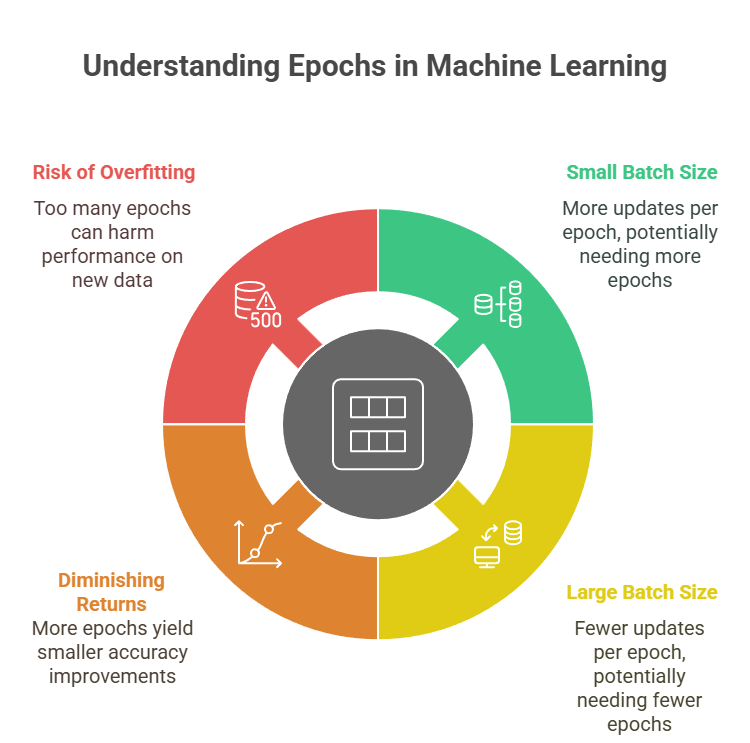
When working with machine learning, it's easy to confuse terms like epoch, iteration, and batch size. These terms are often used interchangeably, but they each have distinct meanings and roles in the training process. Understanding what are epochs in machine learning and these differences is crucial for optimizing model performance and training efficiency. Let's clarify these common misunderstandings to help you better navigate the training process.
Epoch vs Iteration vs Batch Size
The relationship between epoch in machine learning, iterations, and batch size is critical in determining how training time and model performance are impacted. Here's a detailed comparison to clear up any confusion:
Below is a table with the definitions and examples of epoch in machine learning, iteration, and batch:
Term | Definition | Example |
Epoch | A complete pass through the entire training dataset. | Training a model on 1000 data points for 10 epochs means the model will process all 1000 data points 10 times. |
Iteration | One update of the model’s parameters. An iteration refers to a single step during training when the model processes a batch of data. | If you have 1000 data points and a batch size of 100, you’ll have 10 iterations per epoch. |
Batch Size | The number of data points the model processes at once during each iteration. Smaller batch sizes can speed up training but might increase variance. | With a batch size of 100, the model processes 100 data points before updating its weights. |
How Batch Size Impacts Epoch Count?
The batch size used during training influences how many epochs are needed for effective learning:
- Smaller batches perform more updates per epoch, often requiring more epochs for the model to converge.
- Larger batches reduce the number of updates per epoch, which may lower the total epochs needed but can introduce training instability or reduce generalization.
- The ideal setup balances batch size and epoch count for efficient, stable training.
Do More Epochs Mean Better Accuracy?
While it might seem that more epochs always improve accuracy, that’s not necessarily true:
- Diminishing returns: After a point, each additional epoch adds little to no improvement in model performance.
- Risk of overfitting: Training for too many epochs may cause the model to memorize the training data, harming its ability to generalize.
Signs of overfitting include:
- High training accuracy but low validation accuracy.
- Strong performance on training data with poor results on new, unseen data.
To manage this, it’s important to:
- Monitor training and validation metrics closely.
- Use early stopping to end training when validation performance stops improving.
- Tune hyperparameters like learning rate and batch size along with epoch count for optimal results.
Also read: Understanding Recurrent Neural Networks: Applications and Examples
Now that we’ve clarified the key concepts, let’s look at how upGrad can help you master epochs and other critical machine learning concepts.
Why Choose upGrad to Expert in Epochs and Machine Learning?
Understanding epoch machine learning is crucial for training models that generalize well to unseen data. The number of epochs impacts model convergence and accuracy. Too few epochs can lead to underfitting, while too many may cause overfitting. Monitoring and adjusting epoch values is key to avoiding these issues.
upGrad’s advanced machine learning courses offer comprehensive training on the fundamentals. Through expert-led sessions and practical tools, you'll gain hands-on experience to master essential machine learning concepts and apply them effectively.
Here are some top courses to help you advance in your skills and career:
Here are some additional free courses to enhance your learning:
You can also receive personalized career counseling with upGrad to guide your professional journey, or visit your nearest upGrad center to start hands-on training today!
Similar Reads:
- Top 10 Machine Learning Applications in 2025 and the Role of Edge Computing
- Bagging in Machine Learning: Overview, Steps, Benefits & Applications
- Cost Function In Machine Learning
FAQs
1. How do epochs influence model learning in machine learning?
Epochs determine how many times the model sees the entire training dataset. More epochs typically help the model learn better by adjusting its parameters. However, too many epochs can lead to overfitting, which makes the model memorize the data rather than generalize. The key is to find the right balance between too few and too many epochs.
2. How can I prevent overfitting when using a large number of epochs?
Overfitting can be managed by using techniques like early stopping, which halts training when the validation performance ceases to improve. Additionally, monitoring validation loss during training helps to identify the point at which the model starts to overfit and allows you to stop before it starts memorizing the training data.
3. How does data augmentation impact model training?
Data augmentation artificially expands the size of your dataset by applying transformations like rotations, zooms, and flips to the original images or data. This technique helps improve model robustness by exposing it to more variations of the input data, enhancing generalization and reducing overfitting. It's beneficial in tasks like image recognition and natural language processing, where large, diverse datasets are crucial for model performance.
4. How do different machine learning models respond to varying epoch counts?
The response to epoch counts can vary depending on the model type. For simpler models like linear regression or decision trees, fewer epochs may suffice, as they converge quickly. However, more complex models such as deep neural networks require more epochs to adjust their intricate layers and parameters, as they need more data exposure to learn effectively. Understanding how your model behaves across epochs can help you determine the optimal training duration for the best generalization.
5. How do I determine the right number of epochs for my model?
The optimal number of epochs depends on factors like dataset size, model complexity, and learning rate. You can use techniques like cross-validation, empirical testing, and grid search to find the ideal number of epochs that balances underfitting and overfitting for your specific problem.
6. What happens if I use too few epochs for training?
Using too few epochs can result in underfitting, where the model does not learn enough from the training data. This leads to poor generalization, as the model hasn’t had enough exposure to identify key patterns and make effective predictions.
7. How can I track my model’s performance during epochs?
Monitoring the model's performance involves tracking metrics like loss and accuracy during each epoch. In frameworks like TensorFlow and PyTorch, you can visualize these metrics using tools like Matplotlib or TensorBoard, which help you identify trends and make real-time adjustments to the training process.
8. Can I change the number of epochs during training?
Yes, many machine learning frameworks allow you to adjust the number of epochs dynamically during training. This can be done through callbacks like early stopping or by manually updating the epoch count based on the model’s performance.
9. How does the learning rate interact with epochs?
The learning rate and the number of epochs are interrelated. A higher learning rate typically requires fewer epochs because the model makes larger adjustments per update. On the other hand, a smaller learning rate may require more epochs, providing a more stable learning process that can lead to better accuracy if tuned correctly.
10. What is the role of batch size in determining the number of epochs?
While batch size does affect training dynamics, its impact on the number of epochs is indirect. A larger batch size processes more data per update, potentially requiring fewer epochs. However, larger batch sizes can also introduce instability, so tuning both batch size and epochs is crucial for optimal model performance.
11. What role does regularization play in machine learning?
Regularization techniques, such as L1, L2, and dropout, help prevent overfitting by adding penalties to the model’s complexity. These methods force the model to focus on the most critical features, reducing the chance of it learning noise or irrelevant patterns in the data. By controlling the model’s capacity, regularization ensures better generalization and improves performance on unseen data, especially in deep learning models with many parameters.





upGrad Learner Support
Talk to our experts. We are available 7 days a week, 10 AM to 7 PM
Indian Nationals
Foreign Nationals
Disclaimer
The above statistics depend on various factors and individual results may vary. Past performance is no guarantee of future results.
The student assumes full responsibility for all expenses associated with visas, travel, & related costs. upGrad does not .