All courses
Agentic AI
Agentic AI

IIIT Bangalore
Executive Programme in Generative AI for LeadersArtificial Intelligence
Degree / Exec. PG

IIIT Bangalore
Executive Diploma in Machine Learning and AI
OPJ Global University
Master’s Degree in Artificial Intelligence and Data Science
Liverpool John Moores University
Master of Science in Machine Learning & AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIExecutive Certificate

IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership ProgrammeIIIT Bangalore
Executive Programme in Generative AI for Leaders
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceOffline Bootcamps

upGrad
Data Science and AI-MLDoctorate
For All Domains
IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
Swiss School of Business and Management
Global Doctor of Business Administration from SSBM
Edgewood University
Doctorate in Business Administration by Edgewood UniversityGolden Gate University
Doctor of Business Administration From Golden Gate University
Rushford Business School
Doctor of Business Administration from Rushford Business School, SwitzerlandGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)-d9bdeff6165f4eb1ba2adcebde78e961.svg)
University of Waterloo
Chief Technology and AI Officer ProgramLeadership / AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIMachine Learning
Machine Learning
Data Science
Degree / Exec. PG
O.P Jindal Global University
Master’s Degree in Artificial Intelligence and Data ScienceIIIT Bangalore
Executive Diploma in Data Science & AILiverpool John Moores University
Master of Science in Data ScienceExecutive Certificate
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceupGrad | Microsoft
Gen AI Mastery Certificate for Content CreationOffline Bootcamps
upGrad
Data Science and AI-MLupGrad
Data AnalyticsMBA
Masters

Paris School of Business
Master of Science in Business Management and TechnologyO.P.Jindal Global University
MBA (with Career Acceleration Program by upGrad)Edgewood University
MBA from Edgewood UniversityO.P.Jindal Global University
MBA from O.P.Jindal Global UniversityGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)Executive Certificate

IMT, Ghaziabad
Advanced General Management ProgramMarketing
Executive Certificate
Offline Bootcamps
upGrad
Digital MarketingManagement
Degree
O.P Jindal Global University
MSc in International Accounting & Finance (ACCA integrated)Paris School of Business
Master of Science in Business Management and Technology
Golden Gate University
Master of Arts in Industrial-Organizational PsychologyExecutive Certificate

IIM Kozhikode
Human Resource Analytics Course from IIM-KupGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftEducation
Education

Northeastern University
Master of Education (M.Ed.) from Northeastern UniversityEdgewood University
Doctor of Education (Ed.D.)Edgewood University
Master of Education (M.Ed.) from Edgewood UniversityCertifications
Project Management
Certification

Knowledgehut
Leadership And Communications In ProjectsKnowledgehut
Microsoft Project 2007/2010-ae8d039bbd2a41318308f8d26b52ac8f.svg)
Knowledgehut
Financial Management For Project ManagersKnowledgehut
Fundamentals of Earned Value Management (EVM)Knowledgehut
Fundamentals of Portfolio ManagementKnowledgehut
Fundamentals of Program Management-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
Knowledgehut
CAPM® CertificationsKnowledgehut
Microsoft® Project 2016Certifications & Trainings
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)
Knowledgehut
PMP® CertificationKnowledgehut
PMI-RMP® CertificationKnowledgehut
PMP Renewal Learning PathKnowledgehut
Oracle Primavera P6 V18.8Knowledgehut
Microsoft® Project 2013Knowledgehut
PfMP® Certification CourseKnowledgehut
Project Planning and MonitoringPrince2 Certifications

Knowledgehut
PRINCE2® FoundationKnowledgehut
PRINCE2® PractitionerKnowledgehut
PRINCE2 Agile Foundation and PractitionerKnowledgehut
PRINCE2 Agile® Foundation CertificationKnowledgehut
PRINCE2 Agile® Practitioner CertificationManagement Certifications
Knowledgehut
Project Management Masters Certification ProgramKnowledgehut
Change ManagementKnowledgehut
Project Management TechniquesKnowledgehut
Product Management Certification ProgramKnowledgehut
Project Risk Management- Study abroad
- Offline centres
- uGSOT - B.Tech
More
%20(1)-d5498f0f972b4c99be680c2ee3b792d7.svg)




49. Variance in ML
Variance in ML: How Low Variance Filters Improve Model Performance
Did you know? In machine learning, features with almost no variation-like a sensor that always reads the same value-can actually drag down your model’s performance. That’s why data scientists use low variance filters to weed out these “static” features, helping models focus on what really matters and boosting their predictive power. |
Variance in ML plays a critical role in determining the effectiveness of machine learning models. Low variance filters are an essential technique for improving model performance, as they help eliminate features that contribute little to the model's predictive power. By filtering out features with low variance, models become more efficient and less prone to overfitting, especially when working with high-dimensional or noisy data.
In this blog, we will learn about the concept of variance in ML, its relationship with feature selection. You will learn practical methods for applying low variance filters using Python, explore the advantages and limitations of this technique.
Want to boost your career in AI and ML? upGrad’s Artificial Intelligence & Machine Learning - AI ML Courses cover everything from data science to deep learning, taught by Top 1% Global Universities. With 1,000+ hiring partners and an average 51% salary hike, start your journey to a smarter, more successful future today!
What Is Variance in ML and Why It Matters in Feature Selection
Variance in ML refers to the extent to which the values of a feature differ from the mean in a dataset. It is a measure of data spread, which helps to understand how much variability exists in the feature values. The higher the variance, the more the feature can potentially provide information for the machine learning model.
 What Is Variance in ML and Why It Matters in Feature Selection - visual selection-79ce792b35494de5a063bb91f1e42768.png)
However, features with high variance may also introduce noise, leading to overfitting if not handled carefully. Techniques like feature scaling, dimensionality reduction, and regularization are often applied to manage variance effectively.
- High Variance: Features with high variance provide more variability and might offer useful insights for model predictions. However, these features can also contribute to overfitting. For example, a feature with high variance can learn irrelevant patterns from noise in the data, causing the model to perform poorly on new, unseen data.
- Low Variance: Features with low variance have values that are almost the same across the dataset. These features are often not useful in model training because they do not provide sufficient information for the model to differentiate between instances.
The following courses can help you succeed if you want to learn essential ML skills to understand and apply Low Variance Filters for managing variance in ML effectively.
- Executive Diploma in Machine Learning and AI with IIIT-B
- Master’s Degree in Artificial Intelligence and Data Science
- Generative AI Mastery Certificate for Software Development
Impact of Low and High Variance Features on Model Performance
The impact of low and high variance features is fundamental to feature selection. Let’s break down how each type influences the model’s performance:
Low Variance Features:
- Contribution to the Model: Features with low variance don’t change much across samples, which means they provide limited information for the model to learn. They often do not help in differentiating between different data points, making them less useful for prediction.
- Example: A feature like "Gender" in a dataset where only two values (Male and Female) are present with minimal variation would have low variance. Removing such features improves model efficiency, allowing the model to focus on more informative attributes.
- Additional Example: A feature like "country code" in a region where most users come from the same country might exhibit very low variance. This reduces its utility in predicting outcomes.
High Variance Features:
- Risk of Overfitting: While high variance features may seem useful because of their ability to capture a wide range of data, they often introduce overfitting. Overfitting occurs when the model becomes too closely tied to specific patterns or noise in the training data. This reduces its ability to generalize to new, unseen data.
- Example: A feature like "income", which has a broad range across different demographics, can cause the model to overemphasize extreme values. This leads to fit noise and outliers instead of general trends. This can severely degrade model performance on unseen data by causing the model to predict based on extreme data points rather than real patterns.
- Additional Example: In financial datasets, a feature like "transaction amount" with high variance may make the model overly sensitive to very large or small values. This will lead to poor generalization and increased risk of overfitting.
Also read: Regularization in Machine Learning: How to Avoid Overfitting?
The next step is to understand how low variance filters help mitigate the challenges of both low and high variance features by simplifying the model without sacrificing performance.
Understanding the Low Variance Filter Technique in ML
A low variance filter is a statistical feature selection method used to remove features with a variance lower than a predefined threshold. It’s a univariate feature selection method because it evaluates each feature independently, based on its individual variance, and does not take into account interactions between features.
 Understanding the Low Variance Filter Technique in ML - visual selection-0b19230122e0480fa619a3c6290c973c.png)
How It Works:
- Step 1: Compute the variance of each feature in the dataset. This calculates how much each feature’s values vary, identifying features that show little change across data points.
- Step 2: Set a threshold for variance (e.g., 0.1). This threshold defines the minimum amount of variability a feature must have to be considered useful for the model.
- Step 3: Remove features whose variance is below the threshold, as they are considered uninformative. Features with variance below the threshold provide minimal information and are excluded to simplify the model and reduce noise.
Example:
Let’s say you have a dataset with multiple features, including "zip code", where most of the data points belong to a specific geographical region. Since the zip code has little variation (e.g., almost everyone is from the same region), it would have low variance. A low variance filter would remove this feature before model training because it doesn’t provide meaningful information for prediction.
Example Code:
from sklearn.feature_selection import VarianceThreshold
import numpy as np
# Example dataset with features and their corresponding values
X = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]])
# Apply low variance filter with threshold
selector = VarianceThreshold(threshold=0.1)
X_new = selector.fit_transform(X)
print("Original Feature Count:", X.shape[1])
print("New Feature Count:", X_new.shape[1])
Output:
Original Feature Count: 3
New Feature Count: 3
Explanation:
- In this example, we apply the low variance filter with a threshold of 0.1. The dataset initially has 3 features, but after applying the filter, the number of features does not change. This is because none of the features in this dataset has a variance below the threshold.
- If any feature had a variance lower than 0.1, it would be removed, resulting in a reduction of the feature set.
Now that we have a clear understanding of how low variance filters work, let's discuss when and why you should use them in your machine learning workflow.
When Should You Use a Low Variance Filter?
There are specific situations where applying a low variance filter is highly beneficial:
- High-Dimensional Datasets: When your dataset has a large number of features, many of them may be irrelevant or redundant. In high-dimensional datasets, this can lead to increased model complexity and longer training times. By applying a low variance filter, you can significantly reduce the number of features, eliminating those with minimal contribution to model performance. This speeds up model training and improves computational efficiency, making it easier to manage large datasets.
- Example: In a financial dataset with thousands of customer attributes, many features like customer ID or region code may have little variance. This can be discarded to reduce dimensionality, allowing the model to focus on more relevant features.
- Text Data: In natural language processing (NLP) tasks, many words or phrases appear in almost every document, providing little to no meaningful contribution to the task at hand. Words like stopwords (e.g., "the", "and") have low variance because they are found in nearly all documents, making them less informative. A low variance filter can help eliminate these words, reducing the size of the dataset and improving the model's focus on more meaningful terms.
- Example: In a sentiment analysis task, removing stopwords from a text corpus can enhance model performance. Using a low variance filter ensures that the model focuses on more discriminative words, conserving resources.
- Preprocessing for Feature Engineering: It's advisable to start with a low variance filter to remove the least useful features. This step should be taken before utilizing more complex feature selection techniques such as recursive feature elimination (RFE) or mutual information. This ensures that only significant features are retained for further analysis, simplifying the process and reducing noise in the dataset.
- Example: In a dataset with various numerical and categorical features, using a low variance filter first removes columns with little variability, which can then be followed by more sophisticated methods like RFE to fine-tune the feature set.
We now understand when and why to use low variance filters. Next, let’s look at a practical implementation of this technique using Python's scikit-learn library.
Example: Applying a Low Variance Filter in Python (With scikit-learn)
Let’s walk through a Python example using the VarianceThreshold class from the scikit-learn library. This class allows us to apply a low variance filter to our dataset to remove uninformative features.
from sklearn.feature_selection import VarianceThreshold
import numpy as np
# Example dataset with features and their corresponding values
X = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]])
# Apply low variance filter with threshold
selector = VarianceThreshold(threshold=0.1)
X_new = selector.fit_transform(X)
print("Original Feature Count:", X.shape[1])
print("New Feature Count:", X_new.shape[1])
Explanation:
- We have a dataset X with three features.
- The VarianceThreshold is set to filter out features whose variance is lower than 0.1.
- The original feature count is compared to the new feature count after the filter is applied. If the variance of a feature is below the threshold, it is removed.
Output:
Original Feature Count: 3
New Feature Count: 3
Output Interpretation: In this example, no features are removed because all have variance above the threshold of 0.1. If the dataset contained features with little or no variance (such as a column of identical values), those features would be removed, and the new feature count would be lower.
Setting the Right Threshold:
- The threshold value is critical to the effectiveness of the low variance filter:
- Too low: Retains many features, possibly including noisy ones.
- Too high: Removes too many features, possibly losing important ones.
- Optimal threshold: The ideal value can be determined by experimentation, cross-validation, or domain knowledge.
Example of threshold impact: A threshold of 0.1 might be appropriate for some datasets, but for others, a higher or lower threshold could perform better. You might need to adjust it based on your data’s variability or use cross-validation to determine the best threshold.
Now that we’ve covered the practical implementation, let’s explore some other feature selection techniques that can be used in conjunction with or as alternatives to low variance filters.
Alternatives to Low Variance Filters for Feature Selection
-911d9369c8ff47c19483ce3cf3088afb.png)
While low variance filters are effective, they are not the only option for feature selection. Depending on the dataset and problem at hand, you might consider other methods that could complement or replace the low variance approach. Here are some additional techniques for feature selection:
- Mutual Information: This method evaluates the dependency between features and the target variable. Features with high mutual information are considered more valuable for the model because they carry more relevant information for predicting the target.
- When to apply: Use mutual information when dealing with non-linear relationships or when you want to capture feature dependencies with the target variable. It’s especially useful in datasets where relationships between features and the target may not be purely linear.
- Example: In a classification task, you may have features like age, income, and education level. Mutual information can reveal that income and education level have a higher dependency on predicting whether a customer will purchase a product, while age may have a weaker relationship.
- Recursive Feature Elimination (RFE): RFE is a feature selection method that recursively removes features based on the model's performance. It starts with all the features and eliminates the least important ones based on their impact on model accuracy. The process continues until the optimal feature set is identified.
- When to apply: RFE is ideal when you need to improve model performance and interpretability by selecting a smaller subset of features. It is most useful when working with complex models (e.g., decision trees, SVM) where feature importance can be ranked and evaluated.
- Example: In a regression task, RFE could be used to identify which features, such as hours worked, age, or education level, contribute the most to predicting salary. Features with little impact on prediction accuracy, like marital status, could be removed.
- Embedded Methods: These methods, such as Lasso or Ridge Regression, perform feature selection during model training. They apply regularization to penalize less important features based on their coefficients, helping to reduce overfitting and improve model generalization.
- When to apply: Use embedded methods when you want to combine feature selection and model training in a single process. These methods work well for linear models and are efficient when you have many features and want to minimize overfitting.
- Example: In linear regression, Lasso can be used to shrink the coefficients of less important features to zero, effectively removing them from the model. For instance, in a dataset predicting house prices, features such as number of bathrooms or neighborhood could be regularized based on their predictive power.
Also Read: 18 Types of Regression in Machine Learning [Explained With Examples]
Now that we’ve covered some alternatives, let’s discuss the pros and cons of using low variance filters and when they should be part of your preprocessing pipeline.
Benefits and Limitations of Using Low Variance Filters
Low Variance Filters are simple yet powerful tools in feature selection, offering both efficiency gains and potential trade-offs. Understanding their pros and cons can help you apply them more effectively in real-world ML projects.
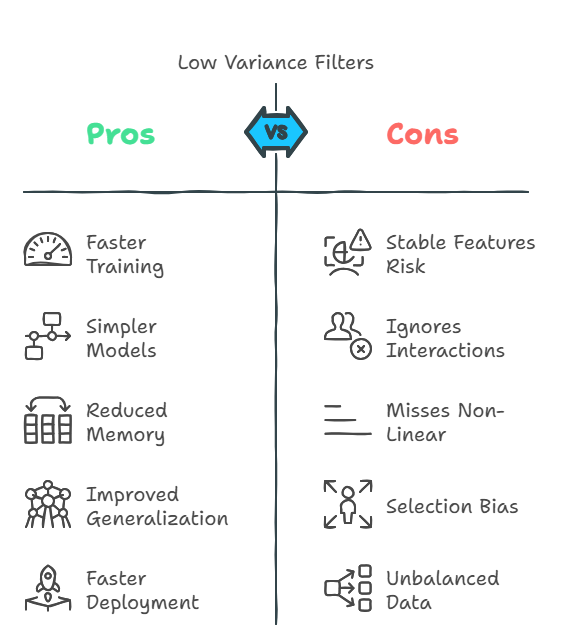
Advantages of Low Variance Filters for Model Training and Speed
Low Variance Filters streamline the feature set by removing columns with minimal variability. This helps in building faster, more efficient machine learning models without significantly compromising performance.
- Faster Model Training: By eliminating low variance features, the dataset becomes smaller and more manageable, leading to quicker training.
Example: Removing a feature like "constant product code" that doesn’t change speeds up training in a retail sales model.
- Simpler Models: Fewer features mean a simpler model, which is easier to interpret and less likely to overfit.
Example: Excluding nearly identical sensor readings in a predictive maintenance model reduces complexity and clarifies insights.
- Reduced Memory Usage: With fewer features, the model requires less memory and storage, improving computational efficiency.
Example: Dropping redundant location codes in a logistics dataset lowers memory demand during processing.
- Improved Generalization: Focusing on higher variance features reduces overfitting, helping the model perform better on unseen data.
Example: Ignoring a feature like "fixed employee ID" in a churn prediction model helps prevent the model from memorizing irrelevant details.
- Faster Model Deployment: A smaller feature set makes deployment easier and more efficient.
Example: Streamlining features in a fraud detection system leads to quicker updates and smoother integration.
Limitations and What Low Variance Filters Might Miss
While helpful, Low Variance Filters are not without flaws. They can unintentionally discard features that appear insignificant but actually contribute valuable information.
- Risk of Removing Stable but Meaningful Features: Some features with low variance may still be valuable if they are consistent, but crucial for the model.
Example: In credit scoring, a feature like “has a mortgage” rarely changes but strongly predicts repayment behavior.
- Ignores Feature Interactions and Label Relevance: Low variance filters assess each feature individually and don’t account for how features work together.
Example: In marketing data, two features might each have low variance but combined can predict customer churn accurately.
- May Miss Important Non-Linear Relationships: This filter focuses on linear variance and may overlook features that relate to the target in a non-linear way.
Example: In sensor data, a feature might show little variance overall but have a non-linear pattern connected to equipment failure.
- Selection Bias: Choosing the wrong variance threshold can lead to discarding useful features.
Example: Setting a high threshold might remove a rare but critical indicator of fraud in financial transactions.
- Inappropriate for Highly Unbalanced Data: In datasets with imbalanced classes, features with low variance might still be key for minority classes.
Example: In medical diagnosis, a rare symptom may show low variance but be essential for identifying a disease.
With an understanding of the benefits and limitations, let’s test your knowledge of low variance filters and how they can be applied effectively in your machine learning projects.
Test Your Understanding of Low Variance Filters
To reinforce your understanding of low variance filters, we have created a series of questions that test your knowledge on this topic. These questions will cover the key aspects of variance in ML, feature selection, and model optimization.
1. What is the primary purpose of a Low Variance Filter in machine learning?
- To identify the most important features based on correlation
- To remove features with low predictive power by checking their variance
- To increase the complexity of the model
- To calculate the performance of the model
2. How does a low variance filter impact a high-dimensional dataset?
- It adds irrelevant features to the dataset
- It reduces the number of features, improving computational efficiency
- It increases training time by keeping more features
- It removes important features based on their value
3. Which of the following is an example of a feature that a low variance filter might remove?
- Age of individuals in a dataset
- Zip code for a region with very few variations
- Customer spending behavior
- Income levels in a diverse dataset
4. What type of features does the Low Variance Filter primarily evaluate?
- Correlated features
- Features with high dimensionality
- Features with minimal variability across data samples
- Features with complex interactions
5. Which of the following scenarios would benefit from using a low variance filter?
- A dataset with highly correlated features that contain meaningful patterns
- A dataset with multiple irrelevant features like customer IDs
- A dataset where all features have high variability
- A dataset with large amounts of missing values
6. What is one disadvantage of using a low variance filter?
- It removes features that might have important information despite their low variance
- It increases the risk of overfitting
- It can only be applied to categorical data
- It requires a high degree of domain knowledge to use
7. Which of the following techniques can be used to set the appropriate threshold for variance in a low variance filter?
- Cross-validation
- K-means clustering
- PCA (Principal Component Analysis)
- Grid search
8. Which type of data would a low variance filter typically be applied to?
- Numerical data with wide variations across features
- High-dimensional data with many irrelevant features
- Text data with diverse word frequencies
- Data with missing values
9. How does a high variance feature affect a machine learning model?
- It has minimal impact on the model’s performance
- It can lead to overfitting if not properly handled
- It is automatically eliminated by the model
- It simplifies the model by reducing feature space
10. Which of the following methods could be an alternative to using a low variance filter for feature selection?
- Mutual Information
- Decision Tree Classifier
- Naive Bayes Classifier
- K-means clustering
Also read: 50+ Must-Know Machine Learning Interview Questions for 2025
How Can upGrad Help You Become an Expert in ML?
Understanding the impact of variance in ML is crucial for optimizing your machine learning models. Low variance filters help eliminate irrelevant features, streamlining the model and enhancing its performance. By applying the right techniques and adjusting thresholds, you can ensure that your model focuses on the most informative features, improving both efficiency and accuracy.
Suppose you’re looking to enhance your expertise in machine learning and want to get into advanced techniques like low variance filters. In that case, upGrad’s AI & ML programs are designed to provide you with the knowledge and hands-on experience you need. Whether you’re aiming for career growth or seeking to fill knowledge gaps, upGrad offers specialized courses to strengthen your ML skills and prepare you for real-world challenges. Explore courses like:
- Advanced Generative AI Certification Course
- Generative AI Mastery Certificate for Managerial Excellence
Curious which courses can help you excel in machine learning in 2025? Contact upGrad for personalized counseling and valuable insights. For more details, you can visit your nearest upGrad offline center.
FAQs
1. What is the main difference between high variance and low variance features in machine learning?
High variance features have large variations across the data, which might contribute valuable insights for predictions, but they can also cause overfitting. Low variance features, on the other hand, have minimal variability, making them less informative for model learning and more likely to be discarded during feature selection.
2. Why is a low variance filter important for preprocessing machine learning models?
A low variance filter helps reduce the dimensionality of the dataset by eliminating features with little variability. This process improves the model’s efficiency, reduces training time, and prevents overfitting by focusing on more informative features that contribute to the model's predictive power.
3. Can a low variance filter be used on all types of data, including categorical data?
No, low variance filters are typically applied to numerical features. For categorical data, techniques like frequency analysis or mode-based selection can be used to identify uninformative features. If a categorical feature has a dominant class, it might be removed using similar criteria.
4. How does a low variance filter improve model performance?
By removing features with low variance, a low variance filter allows the model to focus on features that show greater variation and have more predictive power. This reduces overfitting, improves generalization, and leads to faster training times by simplifying the dataset.
5. What threshold should be set for the variance when applying a low variance filter?
The threshold for the variance depends on the dataset. A threshold too low may retain features with little value, while a threshold too high might remove useful features. It’s ideal to experiment with different thresholds and use techniques like cross-validation to find the most effective value for your specific dataset.
6. Can removing low variance features lead to the loss of important information?
Yes, in some cases, removing low variance features can result in the loss of meaningful information, especially if the feature is stable but important for model predictions. Features with low variance but strong correlation to the target variable may be valuable and should not be discarded without careful consideration.
7. How can I combine low variance filters with other feature selection techniques?
Low variance filters can be used as an initial step in the feature selection process to remove irrelevant features, followed by more advanced techniques like Recursive Feature Elimination (RFE) or Mutual Information. This combination ensures that only the most relevant features are retained for model training.
8. Is the low variance filter suitable for text data in natural language processing (NLP)?
Yes, a low variance filter is particularly useful in text data preprocessing. It can help remove stopwords or frequently occurring terms that don’t contribute meaningfully to the prediction, allowing the model to focus on more relevant terms that vary across the documents.
9. When should I avoid using a low variance filter in my machine learning workflow?
A low variance filter should be avoided when working with features that, despite having low variance, could carry significant meaning for specific cases. For example, features in highly unbalanced datasets or features with low variance but strong relationships to the target variable should be carefully evaluated before removal.
10. Does the use of low variance filters affect the interpretability of the model?
Yes, using a low variance filter can improve interpretability by reducing the number of features in the model, making it easier to understand the key factors that influence predictions. However, it’s essential to ensure that important features are not removed, as this might affect the model’s overall clarity.
11. Can a low variance filter be used to improve model performance in high-dimensional datasets?
Yes, in high-dimensional datasets, where many features may be irrelevant or redundant, a low variance filter can significantly improve model performance. By removing features with low variance, the filter reduces the dimensionality, speeding up training, decreasing computational cost, and enhancing model efficiency by focusing on more relevant features.





upGrad Learner Support
Talk to our experts. We are available 7 days a week, 10 AM to 7 PM
Indian Nationals
Foreign Nationals
Disclaimer
The above statistics depend on various factors and individual results may vary. Past performance is no guarantee of future results.
The student assumes full responsibility for all expenses associated with visas, travel, & related costs. upGrad does not .