All courses
Doctorate
For All Domains

IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
Swiss School of Business and Management
Global Doctor of Business Administration from SSBM
Edgewood University
Doctorate in Business Administration by Edgewood University
Golden Gate University
Doctor of Business Administration From Golden Gate University
Rushford Business School
Doctor of Business Administration from Rushford Business School, SwitzerlandGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)Leadership / AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIGolden Gate University
DBA in Digital Leadership from Golden Gate University, San FranciscoArtificial Intelligence
Degree / Exec. PG

IIIT Bangalore
Executive Diploma in Machine Learning and AI
OPJ Global University
Master’s Degree in Artificial Intelligence and Data Science
Liverpool John Moores University
Master of Science in Machine Learning & AIGolden Gate University
DBA in Emerging Technologies with Concentration in Generative AIExecutive Certificate
IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
IIIT Bangalore
Executive Programme in Generative AI for Leaders
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceOffline Bootcamps

upGrad
Data Science and AI-MLMachine Learning
Machine Learning
Data Science
Degree / Exec. PG
O.P Jindal Global University
Master’s Degree in Artificial Intelligence and Data ScienceIIIT Bangalore
Executive Diploma in Data Science & AILiverpool John Moores University
Master of Science in Data ScienceExecutive Certificate
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceupGrad | Microsoft
Gen AI Mastery Certificate for Content CreationOffline Bootcamps
upGrad
Data Science and AI-MLupGrad
Data AnalyticsGen AI & Agentic AI
Gen AI & Agentic AI
IIIT Bangalore
Executive Programme in Generative AI for LeadersMasters

Paris School of Business
Master of Science in Business Management and TechnologyO.P.Jindal Global University
MBA (with Career Acceleration Program by upGrad)Edgewood University
MBA from Edgewood UniversityO.P.Jindal Global University
MBA from O.P.Jindal Global UniversityGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)Executive Certificate

IMT, Ghaziabad
Advanced General Management ProgramMarketing
Executive Certificate
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Content CreationOffline Bootcamps
upGrad
Digital MarketingManagement
Degree
O.P Jindal Global University
MSc in International Accounting & Finance (ACCA integrated)Paris School of Business
Master of Science in Business Management and Technology
Golden Gate University
Master of Arts in Industrial-Organizational PsychologyExecutive Certificate

IIM Kozhikode
Human Resource Analytics Course from IIM-KupGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftEducation
Education

Northeastern University
Master of Education (M.Ed.) from Northeastern UniversityEdgewood University
Doctor of Education (Ed.D.)Edgewood University
Master of Education (M.Ed.) from Edgewood UniversityProject Management
Certification

Knowledgehut
Leadership And Communications In ProjectsKnowledgehut
Microsoft Project 2007/2010-ae8d039bbd2a41318308f8d26b52ac8f.svg)
Knowledgehut
Financial Management For Project ManagersKnowledgehut
Fundamentals of Earned Value Management (EVM)Knowledgehut
Fundamentals of Portfolio ManagementKnowledgehut
Fundamentals of Program Management-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
Knowledgehut
CAPM® CertificationsKnowledgehut
Microsoft® Project 2016Certifications & Trainings
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)
Knowledgehut
PMP® CertificationKnowledgehut
PMI-RMP® CertificationKnowledgehut
PMP Renewal Learning PathKnowledgehut
Oracle Primavera P6 V18.8Knowledgehut
Microsoft® Project 2013Knowledgehut
PfMP® Certification CourseKnowledgehut
Project Planning and MonitoringPrince2 Certifications

Knowledgehut
PRINCE2® FoundationKnowledgehut
PRINCE2® PractitionerKnowledgehut
PRINCE2 Agile Foundation and PractitionerKnowledgehut
PRINCE2 Agile® Foundation CertificationKnowledgehut
PRINCE2 Agile® Practitioner CertificationManagement Certifications
Knowledgehut
Project Management Masters Certification ProgramKnowledgehut
Change ManagementKnowledgehut
Project Management TechniquesKnowledgehut
Product Management Certification ProgramKnowledgehut
Project Risk ManagementFresh graduates
Data Science
Bootcamp
Offline Bootcamps
upGrad
Data Science and AI-MLupGrad
Data AnalyticsManagement
Marketing
Bootcamp
upGrad Campus
Advanced Certificate in Performance MarketingOffline Bootcamps
upGrad
Digital Marketing- Study abroad
- Offline centres
More

%20(1)-d5498f0f972b4c99be680c2ee3b792d7.svg)



49. Variance in ML
Everything You Need to Know About Deep Q Learning and Its Applications in AI
Latest Update: Recent universal approximation theoretical analyses confirm that DQNs can approximate the optimal Q-function with arbitrary accuracy in continuous-time settings when using stochastic control and Forward-Backward Stochastic Differential Equations (FBSDEs)., broadening their applicability to complex systems.
Deep Q Learning (DQL) is a reinforcement learning algorithm that allows AI agents to make decisions by learning optimal actions through trial and error. It has applications in areas like robotics, gaming, and autonomous vehicles, driving innovations in intelligent systems.
In this blog, we’ll discuss the key concepts of Deep Q Learning, its significance in modern AI applications, highlighting how DQL facilitates intelligent decision-making in complex environments.
Struggling to understand Deep Q Learning and its applications in AI? Enroll in upGrad’s Online Artificial Intelligence and Machine Learning courses, where you’ll gain hands-on experience with 17+ practical projects. Learn from industry experts and build a strong foundation in AI technologies. Join today!
What is Deep Q Learning? Core Components
Deep Q Learning (DQN) is an advanced reinforcement learning (RL) algorithm that takes the strengths of Q-learning and combines it with the power of deep neural networks. This enables an agent to navigate complex, high-dimensional environments and make decisions to maximize long-term rewards.
In essence, deep Q learning allows an agent to learn how to make a series of decisions by exploring its environment, aiming to optimize actions that result in the highest rewards over time. It's applied in diverse fields, from gaming (e.g., AlphaGo) to robotics, finance, and beyond.
Here’s a breakdown of why deep Q learning is impactful:
- Combines Q-learning with Deep Learning:
- Traditional Q-learning uses a Q-table to store state-action values, but deep Q learning replaces this with a deep neural network to approximate Q-values, making it more effective for high-dimensional state spaces.
- Improved Scalability and Generalization:
- The use of deep neural networks enables the model to generalize better to previously unseen states, which is crucial in environments with large or continuous state and action spaces.
- Solving Complex Problems:
- Deep Q learning is applied to complex decision-making tasks such as game playing (like AlphaGo), robot control, and even stock trading, making it a versatile algorithm for real-world challenges.
- Handling High-Dimensional State Spaces:
- Deep Q Learning can efficiently process environments with complex inputs, like images or video frames, where traditional Q-learning would be impractical due to the size and complexity of the Q-table.
- Continuous Action Spaces:
- Unlike discrete action spaces, deep Q learning can handle continuous actions, making it adaptable to real-world environments like robotic manipulation or autonomous driving.
As the need for skilled professionals in reinforcement learning intensifies, gaining expertise will open up exciting opportunities. Check out these courses to develop practical skills and gain hands-on experience with industry leaders.
- Masters in Artificial Intelligence and Machine Learning
- Executive Diploma in Machine Learning and AI with IIIT-B
- DBA in Emerging Technologies with Concentration in Generative AI
To understand Deep Q-Learning, it’s important to explore its core components and how they contribute to its functionality.
Core Components of Deep Q Learning
Deep Q Learning integrates three key components to enable effective decision-making in complex environments. These components are the Q-network, the experience replay buffer, and the target network that work together to help the agent learn optimal policies while addressing challenges like instability and overfitting.
- Deep Q-Network (DQN): The backbone of Deep Q Learning, where Q-values are stored and updated in a deep neural network. This allows the agent to learn decision-making policies for complex tasks. For instance, in a game like Pong, the Q-network processes past frames to guide the agent’s actions toward achieving high rewards.
- Experience Replay Buffer: This buffer stores past experiences (state-action-reward transitions) and allows the agent to randomly sample batches of these experiences during training. By doing so, it reduces correlations between consecutive experiences and stabilizes training, enabling better learning from diverse scenarios.
- Target Network: A critical component that is a copy of the Q-network used to calculate the target Q-values during updates. The target network helps address the "moving target problem," where rapidly changing Q-values can lead to unstable learning. By periodically updating the target network, it provides a stable target for learning and reduces the variance of updates, stabilizing training.
Before moving ahead, let's understand the key differences between Q-Tables and Neural Networks in Deep Q Learning through the following comparison:
Aspect | Q-Table | Neural Networks in Deep Q Learning |
State Representation | Stores Q-values explicitly for each state-action pair, feasible only for small, discrete state spaces. | Uses neural networks to approximate Q-values for large or continuous state spaces, generalizing across states. |
Scalability | Not scalable for large or continuous state spaces due to exponential growth in table size. | Scalable to large, high-dimensional state spaces; neural networks handle high-dimensional input efficiently. |
Generalization | No generalization, limited to predefined discrete states. | Can generalize across unseen states using learned patterns and representations. |
Memory Efficiency | Memory-intensive for large state-action spaces, requires storing explicit Q-values for each pair. | More memory-efficient, storing only the neural network weights rather than all state-action pairs. |
Action Selection | Selects actions directly by looking up Q-values for state-action pairs in the table. | Selects actions based on neural network outputs that predict Q-values for each action. |
Develop your expertise in AI and Machine Learning with upGrad’s Generative AI Foundations Certificate Program. Learn how to optimize cost functions, fine-tune algorithms, and create effective models. Start today to build a strong foundation for a future in AI. Start learning today!
Also Read: Top 16 Deep Learning Techniques to Know About in 2025
Having understood the core components, let's explore how Deep Q-Learning operates through a hands-on Python implementation.
How Deep Q Learning Works? Python Implementation
-2ccf5f73c93045c483c3b4e597f76b26.png)
Deep Q Learning (DQL) merges traditional Q-learning with deep neural networks, allowing agents to learn optimal actions in complex environments with large state spaces. Unlike classic Q-learning, which uses a Q-table, DQL uses a deep Q network (DQN) to approximate Q-values for high-dimensional inputs such as images or sensor data.
Below, we’ll break down the working of deep Q learning and how they're implemented in Python.
The Q-Learning Algorithm
Q-learning is a model-free reinforcement learning algorithm that helps an agent determine the best action to take in a given state by learning the Q-function. The Q-function estimates the expected future reward for state-action pairs.
- Traditional Q-learning: Stores Q-values in a Q-table.
- Deep Q learning (DQL): Uses a neural network (DQN) to approximate Q-values for larger state spaces (e.g., visual input in games or sensor data in robotics).
The Bellman equation is key to Q-learning, updating Q-values based on the current state and future rewards:
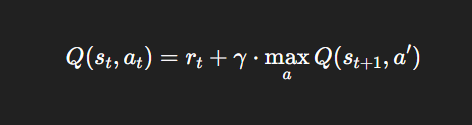
Where:
- Q(st,at): is the Q-value for the state-action pair (st,at).
- rt is the reward received at time t.
- is the discount factor, which values future rewards less than immediate ones.
In deep Q learning, instead of a Q-table, a neural network is used to approximate this function for high-dimensional state spaces.
Deepen your understanding of AI with upGrad’s Online Master’s in Artificial Intelligence and Data Science Course. Gain hands-on experience with industry experts through 15+ top AI tools like TensorFlow, Python, and Hadoop and 15+ real-world case studies in healthcare, finance, and e-commerce. Enroll now!
The Role of Neural Networks in Deep Q Learning
In deep Q learning, neural networks replace the traditional Q-table, enabling agents to handle high-dimensional state inputs like images. The Deep Q Network (DQN) outputs Q-values for each possible action, and the network is trained using backpropagation and gradient descent.
- The DQN generalizes the Q-function, learning across multiple states.
- This allows deep Q learning to scale to environments where a Q-table would be impractical.
The Q-Function and Value Iteration
The Q-function in deep Q learning estimates the expected future rewards for state-action pairs. Through value iteration, the agent iteratively refines its Q-values, converging to the optimal policy.
- Value Iteration: The agent updates the Q-values, maximizing the long-term rewards by training the DQN to predict the best action for any given state.
The DQN uses the Q-function to guide the agent towards optimal actions by considering future rewards.
Exploration vs. Exploitation in Deep Q Learning
One of the central challenges in reinforcement learning is balancing exploration and exploitation.
- Exploration: Trying new actions to discover their effects.
- Exploitation: Choosing the action with the highest Q-value based on past learning.
The decay rate of ϵ in the epsilon-greedy policy balances exploration and exploitation. Initially high, ϵ encourages exploration, and gradually decreases to promote exploitation of learned strategies. The decay can be linear, exponential, or inverse-time based, determining how quickly the agent shifts from random exploration to focused exploitation, ultimately helping it converge to an optimal policy efficiently.
Training Deep Q Learning Models
Training Deep Q-Learning models involves using neural networks to approximate the Q-function, which predicts the expected future rewards for a given state-action pair. The model is trained using the Bellman equation and experience replay. Key steps include defining the environment, choosing an exploration strategy, and optimizing the Q-network using gradient descent.
- Reward Signal and Loss Function:
- Reward Signal: The reward provides feedback to the agent on its actions. It’s crucial for training the agent by reinforcing good decisions and discouraging bad ones.
- Loss Function: The loss function minimizes the difference between predicted Q-values and actual target Q-values. Typically, Mean Squared Error (MSE) is used to quantify this difference, driving the optimization process.
- Updating Q-Values with Backpropagation:
- Backpropagation: The Q-values are updated through backpropagation in the neural network. By adjusting the network weights, the model reduces the error between predicted and target Q-values.
- Target Q-Values: The target Q-values are computed using the Bellman equation, and these are used to guide the updates in the network’s weights during training.
- Training Process Overview: Episodes and Timesteps:
- Episodes: The training occurs over many episodes, where each episode represents an interaction between the agent and the environment.
- Timesteps: Within each episode, the agent takes actions over multiple timesteps. With each action, the agent updates its Q-values, gradually refining its policy and improving its decision-making.
- Hyperparameters in Deep Q Learning:
- Key hyperparameters play a crucial role in the success of the training process:
- Learning Rate: Determines how much the Q-values are adjusted after each update.
- Discount Factor (Gamma): Balances the importance of immediate versus future rewards.
- Epsilon: Controls the exploration-exploitation trade-off during training.
- Carefully tuning these hyperparameters is essential for effective training and optimal performance of the deep Q learning agent.
Implementing Deep Q Learning in Python
To implement Deep Q Learning, you need a simulated environment where an agent can interact and learn. OpenAI Gym is a popular platform for this, providing several environments for training reinforcement learning agents.
Let's discuss an implementation using TensorFlow/Keras to build a simple Deep Q-Network (DQN) for the CartPole-v1 environment.
1. Setting Up the Environment
First, install the necessary libraries and create the environment:
pip install gym tensorflow numpy matplotlibThen, create and set up the environment:
import gym
import numpy as np
# Create the environment
env = gym.make('CartPole-v1')
state_size = env.observation_space.shape[0] # Number of state variables
action_size = env.action_space.n # Number of possible actions
2. Building a Simple DQN with TensorFlow/Keras
Now, define the model for the DQN. We'll use a neural network with two hidden layers to approximate the Q-function:
import tensorflow as tf
from tensorflow.keras import layers
def build_model(state_size, action_size):
model = tf.keras.Sequential([
layers.Dense(24, activation='relu', input_shape=(state_size,)),
layers.Dense(24, activation='relu'),
layers.Dense(action_size, activation='linear') # Output Q-values for each action
])
return model
model = build_model(state_size, action_size)
3. Training and Evaluating the Model
We'll train the model using an epsilon-greedy strategy and update Q-values with the Bellman equation. Here's the training loop:
def train_dqn(model, env, episodes=1000, gamma=0.99, epsilon=1.0, epsilon_decay=0.995, epsilon_min=0.01, learning_rate=0.001):
optimizer = tf.keras.optimizers.Adam(learning_rate)
for e in range(episodes):
state = env.reset()
state = np.reshape(state, [1, state_size])
done = False
total_reward = 0
while not done:
# Epsilon-greedy strategy
if np.random.rand() <= epsilon:
action = np.random.randint(action_size) # Explore
else:
q_values = model(state) # Exploit
action = np.argmax(q_values[0])
next_state, reward, done, _ = env.step(action)
next_state = np.reshape(next_state, [1, state_size])
# Update the Q-value using Bellman equation
with tf.GradientTape() as tape:
target = reward + gamma * np.max(model(next_state)[0]) * (1 - done)
q_values = model(state)
loss = tf.keras.losses.mean_squared_error(target, q_values[0][action])
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
total_reward += reward
state = next_state
# Decaying epsilon to reduce exploration over time
if epsilon > epsilon_min:
epsilon *= epsilon_decay
# Print the progress at each episode
print(f"Episode {e+1}/{episodes}, Total Reward: {total_reward}, Epsilon: {epsilon}")
# Train the model
train_dqn(model, env)
Output
When you run the training loop, the output will show the agent's progress, including the total reward per episode and the epsilon value, which decays over time. This allows the agent to shift from exploration to exploitation as training progresses.
Example output:
Episode 1/1000, Total Reward: 20, Epsilon: 0.995
Episode 2/1000, Total Reward: 25, Epsilon: 0.990025
...
Episode 1000/1000, Total Reward: 200, Epsilon: 0.01
The agent's behavior improves as it updates its Q-values based on feedback from the environment, gradually learning to balance the cartpole.
Want to master Python for machine learning? Enroll in upGrad’s free Basic Python Programming course and learn to implement cost functions, optimization algorithms, and more. Gain the skills to build robust models with Python and become a proficient ML practitioner. Start learning today!
Also Read: Machine Learning Projects with Source Code in 2025
Now that we've covered the basics of implementing Deep Q Learning in Python, let's explore how these techniques are applied in practical scenarios.
Practical Applications of Deep Q Learning
Deep Q Learning has shown exceptional promise in solving complex decision-making problems across various industries. By using the Deep Q Network (DQN), deep Q learning allows agents to tackle environments with large state spaces and derive optimal actions based on sensory input, historical data, or real-time feedback. This adaptability has made deep Q-learning a powerful tool in robotics, gaming, finance, and healthcare.
1. Robotics and Autonomous Vehicles
Deep Q Learning has transformed robotics and autonomous vehicles by enabling real-time decision-making. With the power of DQN, robots can efficiently complete tasks like navigation, manipulation, and obstacle avoidance.
- Autonomous Driving: In self-driving cars, DQN optimizes decisions like lane changes, speed adjustments, and obstacle navigation. For example, Waymo, Google's self-driving project, integrates DQN to refine driving policies, enhancing both safety and efficiency.
- However, challenges remain, including the trade-off between exploration and exploitation, long training times, and the need to ensure safety in critical situations. Excessive exploration may lead to risky decisions, while too much exploitation can limit adaptability to unforeseen conditions.
Also Read: Machine Learning Algorithms Used in Self-Driving Cars: How AI Powers Autonomous Vehicles
- Robotic Manipulation: Robots, such as those used by Amazon in warehouses, leverage DQN to optimize actions like picking up objects and navigating around obstacles. These robots improve over time by adjusting their actions based on real-time feedback.
- Despite the advantages, challenges like the need for real-time responsiveness and balancing exploration with exploitation in dynamic environments persist.
As autonomous systems advance, deep Q learning will continue to be a key player, enabling smarter robots and vehicles that can handle increasingly complex tasks.
2. Game Playing (e.g., AlphaGo, Atari Games)
One of the most impressive applications of deep Q-learning is in game playing. The Deep Q Network (DQN) enabled AlphaGo to defeat human world champions in the game of Go, revolutionizing AI in competitive gaming.
- AlphaGo: By applying deep Q learning, AlphaGo learned from millions of simulated games, ultimately mastering the complex board game. The deep Q network helped the AI identify optimal strategies, allowing it to challenge and outperform the best human players.
- Atari Games: In the realm of classic games, DeepMind applied DQN to teach an agent how to play Atari 2600 games, such as Breakout and Space Invaders, using only raw pixel data. The agent learned to maximize its score by iterating through actions and learning from its rewards.
Gaming continues to be a benchmark for deep Q learning, pushing the limits of AI and showing how it can handle both simple and complex decision-making tasks.
3. Finance and Stock Trading
The finance industry has seen deep Q-learning transform algorithmic trading and portfolio management by allowing AI to make real-time, data-driven decisions in fast-paced environments.
- Algorithmic Trading: Deep Q learning enables high-frequency trading systems to predict market trends and optimize buy/sell decisions. Using historical market data, deep Q networks help trading algorithms make more informed decisions, leading to increased profits and reduced risks.
- Portfolio Management: In portfolio optimization, deep Q learning helps balance asset allocations based on past market behavior. It adjusts investment strategies to maximize returns and minimize risk, ensuring that portfolios stay profitable even in volatile markets.
The integration of deep Q learning into financial trading systems will only increase as markets grow more complex and require smarter algorithms to handle dynamic conditions.
4. Healthcare and Personalized Treatment
In healthcare, deep Q learning is improving patient outcomes by offering personalized treatment plans and enhancing diagnostic accuracy.
- Personalized Medicine: By analyzing patient-specific data, deep Q learning helps optimize drug prescriptions and medical treatments. The DQN adapts to each patient's unique medical history, recommending treatments most likely to be effective.
- Medical Diagnosis: In medical imaging, deep Q learning assists in identifying conditions like cancer by analyzing X-rays, MRIs, and other medical images. With deep Q learning, AI can learn to recognize subtle patterns that aid in more accurate diagnoses.
As healthcare systems become increasingly data-driven, deep Q-learning will continue to play a pivotal role in improving diagnosis accuracy and treatment efficacy.
Enhance your understanding of deep q learning and machine learning with upGrad’s Artificial Intelligence in the Real World free course. This course complements your studies by providing practical insights and real-world applications, helping you grow your career in AI. Start learning today!
Also Read: Explore 25 Game-Changing Machine Learning Applications!
Advancements and Variants of Deep Q-Learning
The deep Q learning advanced significantly, addressing limitations, improving efficiency, and enhancing performance. These advancements have expanded its application to more complex and dynamic environments.
Below are some key innovations in deep Q learning:
1. Double Deep Q-Learning (DDQN)
Problem: Overestimation bias, where the Q-values for certain actions are overestimated, can lead to poor decision-making.
Solution: Double Deep Q Learning (DDQN) mitigates this by using two networks:
- Network 1: Selects actions
- Network 2: Estimates Q-values
By decoupling action selection and Q-value estimation, DDQN enhances stability and reduces overestimation bias.
Example Application: In autonomous driving, DDQN ensures safer decision-making by preventing overestimation in complex traffic scenarios, improving real-time responsiveness and safety.
2. Dueling Deep Q-Networks (Dueling DQN)
Problem: In environments where actions in similar states might have vastly different outcomes, distinguishing between them can be difficult.
Solution: Dueling DQN separates the representation of state values and advantages for each action. This allows the agent to:
- Better understand the value of states, even when actions are similar but lead to different outcomes.
Example Application: In robotic control, where movements might appear similar but have different consequences, Dueling DQN boosts efficiency in decision-making by learning more effectively in ambiguous situations.
3. Prioritized Experience Replay (PER)
Problem: Traditional experience replay treats all experiences equally, which slows down the learning process.
Solution: Prioritized Experience Replay (PER) prioritizes more significant experiences, allowing the agent to focus on learning from the most important transitions, improving the training speed and effectiveness.
Example Application: In stock market trading, PER enables the model to focus on crucial market events, adapting strategies based on pivotal changes, thus improving real-time decision-making.
4. Distributional Deep Q Learning
Problem: Standard deep Q learning predicts a single expected reward, which doesn’t capture uncertainty in environments with stochastic rewards.
Solution: Distributional Deep Q Learning extends DQN by predicting the entire distribution of possible rewards instead of a single expected reward. This enhances robustness by incorporating uncertainty.
Example Application: In financial markets, where rewards can vary unpredictably, distributional DQN allows agents to make more informed decisions by considering the full range of potential outcomes, leading to cautious and better-informed actions.
Also Read: Future Scope of Artificial Intelligence in Various Industries
Despite its potential, Deep Q Learning faces challenges that must be overcome to unlock its full capabilities in practical applications.
What are the Major Challenges in Deep Q Learning?
Deep Q Learning (DQL) has revolutionized reinforcement learning by integrating deep Q-networks (DQNs), allowing agents to solve complex problems in dynamic and high-dimensional environments. However, several challenges hinder its effective implementation in real-world applications. Understanding these challenges is key to improving the stability, efficiency, and scalability of DQNs.
Below, we explore the major challenges and potential solutions.
1. Stability and Convergence Issues
Challenge: One of the primary challenges in deep Q-learning is ensuring the stability and convergence of the model during training. Unlike traditional Q-learning, which uses a Q-table, deep Q-learning uses neural networks to approximate Q-values. This introduces complexities, including:
- Non-stationary Target: The Q-values themselves are constantly updated, causing instability because the target Q-value changes with each update.
- Overestimation Bias: The model tends to overestimate Q-values, which can result in suboptimal decision-making.
Key Issues:
- Non-stationary Target: As the Q-values change, the target becomes unstable.
- Overestimation Bias: The network may overestimate rewards, especially in high-risk environments.
Solutions:
- Target Networks: A delayed copy of the Q-network, updated less frequently, stabilizes the learning process by breaking the feedback loop.
- Double DQN: By using two networks (one for action selection and one for Q-value estimation), Double DQN reduces overestimation bias and improves stability and accuracy.
These solutions significantly improve the convergence rate and stability of the training process.
2. Overfitting and Sample Efficiency
Challenge: Deep Q-networks are prone to overfitting, especially when training data is sparse or the state space is large. Overfitting occurs when the model memorizes the training data rather than generalizing to new, unseen states.
Key Issues:
- Overfitting: The model may perform well on training data but fail to generalize to new situations.
- Inefficient Use of Experience: The model might not make optimal use of the data it has encountered, leading to slow learning and suboptimal performance.
Solutions:
- Experience Replay: Storing past experiences and sampling them randomly breaks correlations between consecutive experiences, reducing overfitting.
- Prioritized Experience Replay (PER): By prioritizing rare or important experiences, PER improves sample efficiency and accelerates learning by focusing on experiences that provide the most valuable insights.
These techniques help improve both the efficiency of learning and the model's ability to generalize.
3. Handling Large State Spaces
Challenge: As tasks become more complex, especially in environments like video games or robotics, the state space can become extremely large, sometimes containing millions of possible states. This creates significant challenges in both computation and generalization.
Key Issues:
- High Dimensionality: The model must handle a large number of variables simultaneously, making it difficult to learn an effective policy.
- Scalability: Training a DQN in large state spaces can be computationally expensive and time-consuming, limiting real-time application in critical domains like autonomous driving or robotics.
Solutions:
- Convolutional Neural Networks (CNNs): CNNs can effectively handle high-dimensional data (e.g., images or videos) by extracting hierarchical features, reducing the complexity of the state space.
- State Space Simplification: Simplifying the state space by focusing on the most relevant features can reduce the dimensionality and improve the model's efficiency.
Also Read: AI Challenges You Can't Ignore: Solutions & Future Outlook
Having understood the challenges, you can now take the next step by learning from upGrad’s expert-led Deep Q-Learning course.
Become an Expert in Deep Q Learning with upGrad!
Deep Q Learning (DQL) builds on traditional Q-learning by using a Deep Q Network (DQN) to approximate Q-values, overcoming the limitations of Q-tables. This neural network approach allows DQL to handle large, high-dimensional state spaces such as images or sensor data.
To master Deep Q Learning and make an exciting career in this growing field, upGrad offers comprehensive programs that provide hands-on experience with advanced technology.
In addition to the courses mentioned above, here are some free courses that can further strengthen your foundation in AI and ML.
- Introduction to Generative AI
- Fundamentals of Deep Learning and Neural Networks
- Learn Python Libraries: NumPy, Matplotlib & Pandas
- ChatGPT for Developers
- Analyzing Patterns in Data and Storytelling
Feeling uncertain about where to go next in your machine learning path? Consider availing upGrad’s personalized career counseling. They can guide you in choosing the best path tailored to your goals. You can also visit your nearest upGrad center and start hands-on training today!
FAQs
1. How does Deep Q Learning improve the efficiency of reinforcement learning?
Deep Q Learning enhances reinforcement learning by using a neural network to approximate Q-values instead of relying on a Q-table. This allows the algorithm to handle larger, high-dimensional state spaces, such as images and sensor data, enabling it to solve more complex real-world problems that traditional Q-learning struggles with, such as game playing and robotics.
2. What role does the epsilon-greedy strategy play in Deep Q Learning?
The epsilon-greedy strategy in Deep Q-Learning helps balance exploration and exploitation. Initially, it encourages the agent to explore more actions by selecting random actions with a probability ϵ. Over time, ϵ decays, promoting exploitation of learned actions, which helps the agent maximize rewards as it becomes more confident in its learned policy.
3. How does the Deep Q Network (DQN) handle large state spaces in Deep Q-Learning?
The Deep Q Network (DQN) enables Deep Q Learning to handle large state spaces by approximating Q-values using a neural network. Instead of storing Q-values in a Q-table, DQN learns the value of state-action pairs directly from high-dimensional inputs, such as pixel data or sensor readings, which allows it to scale efficiently to complex environments like video games and robotics.
4. Why is experience replay important in Deep Q Learning?
Experience replay in Deep Q Learning stores past experiences in a buffer, which are randomly sampled during training. This helps break correlations between consecutive experiences and prevents the model from overfitting to recent observations. By using diverse samples from various stages of the learning process, experience replay stabilizes training and accelerates the agent's ability to learn optimal policies.
5. How do target networks contribute to the stability of Deep Q Learning?
Target networks in Deep Q-Learning are used to stabilize training. The target network is a copy of the DQN that is updated less frequently. This prevents the model from rapidly changing its Q-values during training, reducing the risk of oscillations and instability. By using a target network, the updates to the Q-values become more stable and reliable.
6. How does Deep Q Learning deal with high-dimensional inputs, like images?
Deep Q-Learning can process high-dimensional inputs, like images, by using convolutional neural networks (CNNs) as part of the DQN. These CNNs extract spatial features from images and use them to approximate Q-values. This ability allows Deep Q Learning to make decisions based on raw visual inputs, such as in game-playing or robot navigation, where state representation is highly complex.
7. What is the significance of the discount factor in Deep Q Learning?
The discount factor (γ) in Deep Q Learning determines how much future rewards are considered when making decisions. A value close to 1 prioritizes long-term rewards, while a value near 0 focuses on immediate rewards. Tuning γ influences the agent’s ability to plan ahead, and a proper setting helps the agent find an optimal balance between short-term and long-term reward maximization.
8. Can Deep Q Learning be used for real-time decision-making in autonomous vehicles?
Yes, Deep Q Learning can be used for real-time decision-making in autonomous vehicles. By continuously learning from interactions with its environment, a Deep Q Network (DQN) can optimize decisions like steering, speed control, and obstacle avoidance. Deep Q Learning's ability to process sensor data and adapt to dynamic driving conditions makes it ideal for autonomous vehicle systems.
9. How does Deep Q Learning optimize complex strategies in game environments?
In game environments, Deep Q Learning optimizes strategies by using Deep Q Networks (DQNs) to approximate the Q-values for various actions in the game. The agent learns through trial and error by exploring different strategies, adjusting its policy over time based on the rewards it receives. Games like AlphaGo use Deep Q Learning to train agents that excel at complex decision-making, refining strategies to win over time.
10. What are the benefits of using deep learning in Q-learning for robotics?
Using deep learning in Q-learning for robotics enables robots to learn complex tasks from sensory inputs like camera images and environmental data. Traditional Q-learning struggles with such high-dimensional data, but Deep Q Learning allows the robot to generalize across various states, making it more adaptable to dynamic environments and capable of performing intricate tasks like navigation and object manipulation.
11. How do advancements like Double DQN and Dueling DQN improve Deep Q Learning?
Double DQN addresses the issue of overestimation bias by decoupling the action selection and Q-value estimation steps. Dueling DQN improves efficiency by learning separate value and advantage functions for each action, which helps the agent focus on important states. Both advancements enhance the Deep Q Learning process by improving stability, reducing biases, and enabling faster convergence to optimal policies.

Author|418 articles published





upGrad Learner Support
Talk to our experts. We are available 7 days a week, 10 AM to 7 PM
Indian Nationals
Foreign Nationals
Disclaimer
The above statistics depend on various factors and individual results may vary. Past performance is no guarantee of future results.
The student assumes full responsibility for all expenses associated with visas, travel, & related costs. upGrad does not .