All courses
Agentic AI
Agentic AI

IIIT Bangalore
Executive Programme in Generative AI for LeadersArtificial Intelligence
Degree / Exec. PG

IIIT Bangalore
Executive Diploma in Machine Learning and AI
OPJ Global University
Master’s Degree in Artificial Intelligence and Data Science
Liverpool John Moores University
Master of Science in Machine Learning & AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIExecutive Certificate

IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership ProgrammeIIIT Bangalore
Executive Programme in Generative AI for Leaders
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceOffline Bootcamps

upGrad
Data Science and AI-MLDoctorate
For All Domains
IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
Swiss School of Business and Management
Global Doctor of Business Administration from SSBM
Edgewood University
Doctorate in Business Administration by Edgewood UniversityGolden Gate University
Doctor of Business Administration From Golden Gate University
Rushford Business School
Doctor of Business Administration from Rushford Business School, SwitzerlandGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)-d9bdeff6165f4eb1ba2adcebde78e961.svg)
University of Waterloo
Chief Technology and AI Officer ProgramLeadership / AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIMachine Learning
Machine Learning
Data Science
Degree / Exec. PG
O.P Jindal Global University
Master’s Degree in Artificial Intelligence and Data ScienceIIIT Bangalore
Executive Diploma in Data Science & AILiverpool John Moores University
Master of Science in Data ScienceExecutive Certificate
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceupGrad | Microsoft
Gen AI Mastery Certificate for Content CreationOffline Bootcamps
upGrad
Data Science and AI-MLupGrad
Data AnalyticsMBA
Masters

Paris School of Business
Master of Science in Business Management and TechnologyO.P.Jindal Global University
MBA (with Career Acceleration Program by upGrad)Edgewood University
MBA from Edgewood UniversityO.P.Jindal Global University
MBA from O.P.Jindal Global UniversityGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)Executive Certificate

IMT, Ghaziabad
Advanced General Management ProgramMarketing
Executive Certificate
Offline Bootcamps
upGrad
Digital MarketingManagement
Degree
O.P Jindal Global University
MSc in International Accounting & Finance (ACCA integrated)Paris School of Business
Master of Science in Business Management and Technology
Golden Gate University
Master of Arts in Industrial-Organizational PsychologyExecutive Certificate

IIM Kozhikode
Human Resource Analytics Course from IIM-KupGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftEducation
Education

Northeastern University
Master of Education (M.Ed.) from Northeastern UniversityEdgewood University
Doctor of Education (Ed.D.)Edgewood University
Master of Education (M.Ed.) from Edgewood UniversityCertifications
Project Management
Certification

Knowledgehut
Leadership And Communications In ProjectsKnowledgehut
Microsoft Project 2007/2010-ae8d039bbd2a41318308f8d26b52ac8f.svg)
Knowledgehut
Financial Management For Project ManagersKnowledgehut
Fundamentals of Earned Value Management (EVM)Knowledgehut
Fundamentals of Portfolio ManagementKnowledgehut
Fundamentals of Program Management-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
Knowledgehut
CAPM® CertificationsKnowledgehut
Microsoft® Project 2016Certifications & Trainings
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)
Knowledgehut
PMP® CertificationKnowledgehut
PMI-RMP® CertificationKnowledgehut
PMP Renewal Learning PathKnowledgehut
Oracle Primavera P6 V18.8Knowledgehut
Microsoft® Project 2013Knowledgehut
PfMP® Certification CourseKnowledgehut
Project Planning and MonitoringPrince2 Certifications

Knowledgehut
PRINCE2® FoundationKnowledgehut
PRINCE2® PractitionerKnowledgehut
PRINCE2 Agile Foundation and PractitionerKnowledgehut
PRINCE2 Agile® Foundation CertificationKnowledgehut
PRINCE2 Agile® Practitioner CertificationManagement Certifications
Knowledgehut
Project Management Masters Certification ProgramKnowledgehut
Change ManagementKnowledgehut
Project Management TechniquesKnowledgehut
Product Management Certification ProgramKnowledgehut
Project Risk Management- Study abroad
- Offline centres
- uGSOT - B.Tech
More
%20(1)-d5498f0f972b4c99be680c2ee3b792d7.svg)



49. Variance in ML
Detailed Guide on Dataset in Machine Learning: Steps to Build Machine Learning Datasets
Did you know? Every single day, a staggering 402.74 million terabytes of data are generated! Even more mind-blowing: 90% of the world’s data has been created in just the last two years. With this explosive growth, the need for powerful dataset in machine learning has never been greater!
Datasets are the core of machine learning, providing the data required to train models and make accurate predictions. The success of a machine learning model heavily relies on the quality and relevance of the dataset. It directly impacts the model's performance, whether you're working on recommendation systems, image classification, or financial trend predictions.
In this blog, we will explore the fundamentals of datasets, focusing on what they are, the different types used in machine learning and artificial intelligence, and how you can effectively build and source datasets for your next project. By the end, you'll understand how to leverage datasets to optimize your machine learning models.
Advance your career with upGrad's specialised AI and Machine Learning programs. Backed by 1,000+ hiring partners and a proven 51% average salary increase, these online courses are built to help you confidently move forward.
What Is a Dataset in Machine Learning?
A dataset in machine learning is a collection of data used to train, validate, and test models. It is structured to help the model learn patterns, identify relationships, and make predictions. "Structured data" typically appears in rows and columns, where each row is an observation and each column represents a feature or attribute.
For example, if you're training a model to predict house prices, the dataset might include features such as house size (e.g., square footage), number of bedrooms, location (e.g., neighborhood or zip code), age of the house, etc. These features (inputs) help the model learn how each factor influences house prices. In supervised learning, the dataset also includes a target variable (output), which in this case is the house price that the model aims to predict.
If you’re looking to develop your skills in data management and machine learning, here are some top-rated courses:
- Masters in Artificial Intelligence and Machine Learning - IIITB Program
- Executive Diploma in Machine Learning and AI with IIIT-B
- Executive Post Graduate Certificate Programme in Data Science & AI
In simpler terms, a dataset is the input that powers the learning process. The machine learning model finds patterns and builds predictive power through the structured organization of this data. So, what makes a dataset in machine learning so important?
Why Are Datasets Important?
Datasets play a significant role in machine learning because, without the right data, a machine learning model cannot make predictions or draw conclusions. Here’s why datasets are essential for machine learning:
-8d51c2cf43c84be6afb1a78e08185223.png)
- Training: The primary purpose of a dataset is to train the machine learning model. During the training phase, the model learns to make predictions or decisions based on the data. For instance, if you are building a model to detect fraudulent transactions, the model is trained on a dataset containing examples of both fraudulent and non-fraudulent transactions. The model uses this information to recognize patterns that differentiate the two.
- Validation: After the model has learned from the training data, it needs to be validated to ensure that it's not just memorizing the data (which is called overfitting). This set is used to fine-tune the model's hyperparameters, such as learning rate or tree depth, to improve generalization. Validation helps improve the model’s accuracy and ensures that it is well-tuned for future predictions.
- Testing: Finally, once the model has been trained and validated, it’s time to test its performance using a test dataset. The test set contains data that the model has never seen before, and it's used to evaluate how well the model generalizes to real-world scenarios. If the model performs well on the test data, it’s likely ready for deployment. Keep in mind that there should be a difference between the test dataset and the training set, and it should consist of data the model has never seen before
Together, training, validation, and testing ensure that the model can perform accurately and reliably when applied to new data. A common practice is to use 60–80% of the data for training, 10–20% for validation, and the remaining 10–20% for testing. You also need to ensure that the dataset is clean, relevant, and representative of the problem you’re solving, as poor-quality data can severely limit model performance.
Now that we know the importance of a dataset in machine learning, let’s take a look at the types of datasets.
Top 6 Data Types in Machine Learning
When working with machine learning models, each data type has specific characteristics that influence how it should be preprocessed and which models work best with it. Understanding these data types and their features helps you decide how to work with the data and choose the appropriate algorithms for the task at hand.
Here's a breakdown of the key features of datasets for each common data type:
-8d85aaf958704f22adf40e72172065a4.png)
1. Numerical Data
Numerical data consists of numbers, which could represent anything from measurements (like weight or height) to continuous values (like stock prices or temperature). Numerical data is used in tasks such as regression, where the aim is to estimate a continuous value.
Features:
- Range of Values: The values may span a wide range (e.g., from 0 to 1,000,000), and it’s important to know whether the values are scaled properly (e.g., normalization or standardization).
- Mean and Standard Deviation: Statistical features like mean and standard deviation help assess the central tendency and spread of the data.
- Outliers: Numerical data often contains outliers, which can skew results, so it is essential to identify and handle outliers.
- Data Distribution: Understanding whether the data is normally distributed, skewed by outliers, or follows another distribution helps in choosing the right model and preprocessing techniques.
- Missing Values: Handling missing numerical values through imputation or removal is crucial to maintaining model integrity.
Example: In a house prices dataset, features such as square footage and number of bedrooms are numerical attributes used by the model to predict the target variable, which is the price of the house.
Also Read: Measures of Dispersion in Statistics: Meaning, Types & Examples
2. Categorical Data
Categorical data is non-numerical and involves data points that belong to distinct categories or groups. These categories can be ordinal (with a specific order) or nominal (with no inherent order).
Features:
- Number of Categories: For nominal data, there’s no ranking between categories (e.g., colors, cities), while ordinal data has a clear ranking (e.g., low, medium, high).
- Data Encoding: Machine learning algorithms often require categorical data to be encoded into a numerical format. Techniques include One-Hot Encoding for nominal data and Label Encoding for ordinal data. While tree-based models can handle label-encoded categories natively, linear models typically require one-hot encoding for better performance.
- Cardinality: The number of unique categories in the dataset. High cardinality can lead to issues in processing, especially with one-hot encoding, leading to sparse matrices that can increase memory usage and computational time..
- Balanced vs. Imbalanced Categories: It’s important to check whether all categories are equally represented or if some are underrepresented (which could lead to bias in the model).
Example: Retail dataset: "Product category" could be a categorical feature with values like "Electronics," "Clothing," and "Furniture."
Also Read: A Comprehensive Guide to Understanding the Different Types of Data in 2025
3. Textual Data
Textual data consists of natural language text, such as user generated content, emails, customer reviews, or social media posts. Text data is used in natural language processing (NLP) tasks, such as sentiment analysis or text classification.
Features:
- Length of Text: Text data can vary significantly in length, so padding or truncating the text is often needed for uniformity.
- Tokenization: Text needs to be broken down into tokens (words, subwords, or characters) that the model can understand.
- Stop Words: These are common words like "and," "the," "is," etc., that may or may not carry significant meaning depending on the context. Stop words are frequently removed in traditional models to reduce noise, but in deep learning approaches like BERT, they may be retained.
- Text Cleaning: Preprocessing steps like removing punctuation, converting to lowercase, and handling special characters are essential for text data.
- Embeddings: Textual data can be transformed into vector representations using Bag-of-Words or TF-IDF for basic models. For advanced models, Word2Vec, GloVe, or BERT are used to capture semantic meaning.
Example: A movie review dataset containing the phrase "This movie was amazing!" can be tokenized into ["this," "movie," "was," "amazing"] for sentiment analysis.
4. Image Data
Image data consists of visual information and is used in computer vision tasks. Images are often represented as matrices of pixel values, where each pixel has a specific color value. Common tasks involving image data include image recognition, image classification, object detection, and image segmentation.
Features:
- Image Resolution: The size of the image (e.g., 256x256 pixels) directly affects the amount of data and the model’s computational requirements.
- Color Channels: Images are often represented in RGB (Red, Green, Blue) channels, and different channels may require separate handling during preprocessing. Meanwhile, grayscale images contain a single intensity channel and require different handling compared to RGB images.
- Normalization: Pixel values are usually scaled to a range (e.g., 0-255 to 0-1) to make them suitable for machine learning models.
- Augmentation: Techniques like rotation, flipping, and cropping are used to artificially increase the size of the dataset and improve model robustness by making the model more invariant to transformations.
Example: For an image dataset for a dog vs. cat classifier, the images of cats and dogs will be preprocessed (resized, normalized) and labeled to help the model classify them.
5. Audio Data
Audio data includes sounds or speech. It’s used in tasks such as speech recognition, audio classification, and music recommendation systems. Audio data is typically processed into spectrograms or other representations to make it suitable for machine learning models.
Features:
- Sampling Rate: The number of samples per second (e.g., 44.1 kHz for audio CDs) defines the resolution of the sound wave.
- Frequency Range: Audio data often spans a wide range of frequencies, and it's essential to capture the relevant frequencies for analysis (e.g., human speech typically ranges from 85 Hz to 255 Hz).
- Spectrogram Representation: Audio is often converted into a spectrogram (a visual representation of frequencies over time) to make it more accessible for machine learning. A spectrogram represents sound as a two-dimensional image with time on the x-axis and frequency on the y-axis. A Convolutional Neural Network (CNN) is used to process a spectrogram as an image.
- Noise and Distortion: Raw audio often contains background noise, which may need to be removed or minimized for clearer predictions.
Example: In a speech recognition dataset, the audio recordings of people saying different phrases are transcribed into text. The aim is to train a model that can convert spoken language into written text.
6. Time-Series Data
Time-series data consists of data points indexed in time order and is used in tasks like forecasting and anomaly detection. Common models for time-series analysis include ARIMA for traditional approaches and LSTM (Long Short-Term Memory) networks for more complex, deep learning-based tasks.
Features:
- Temporal Order: Time-series data must be ordered chronologically, as the sequence of data points is critical.
- Seasonality: Many time-series datasets exhibit seasonal patterns (e.g., sales increasing during holidays). Identifying and capturing seasonality is crucial for accurate forecasting.
- Trend: Over time, the data may consistently move upward or downward, such as in stock prices or temperature.
- Stationarity: Time-series models often assume the data’s statistical properties are constant over time. Non-stationary data (e.g., trends) may need to be transformed (e.g., differencing) to make it stationary. For example, applying first-order differencing can remove a trend and make the data stationary.
- Lag: Time-series data may require the introduction of lag features, where past values of a variable are used to predict future values.
Example: A stock price dataset contains the historical prices of a stock over time, which can be used to predict future stock movements or prices.
These are the types of datasets used in machine learning. Unlike a database, which stores and manages data for various purposes, a dataset is specifically curated for training, validating, and testing machine learning models. The table below portrays the key differences between dataset and database:
Aspect | Dataset | Database |
Purpose | Curated for ML tasks (training, testing, validation) | Stores and manages data for various purposes |
Structure | Rows (samples) and columns (features) | Organized in tables, rows, and columns |
Data | Often labeled or annotated for supervised learning | Stores data without a specific focus on ML tasks |
Usage | Used for training and evaluating ML models | Used for querying, reporting, and managing data |
Size | Typically smaller, task-specific | Can be large, handling diverse data types |
Also read: Data Structures & Algorithm in Python: Everything You Need to Know
Now, let’s move towards building a dataset in machine learning and understand each step meticulously.
How to Build Machine Learning Datasets for Your Next Project
A well-structured dataset will ensure your ML model’s optimal performance. Focus on data quality, diversity, and relevance. Use data augmentation to boost smaller datasets, address ethical concerns to avoid bias, and ensure scalability for future improvements. Below is a comprehensive step-by-step guide to help you build and prepare your dataset for a successful machine learning project!
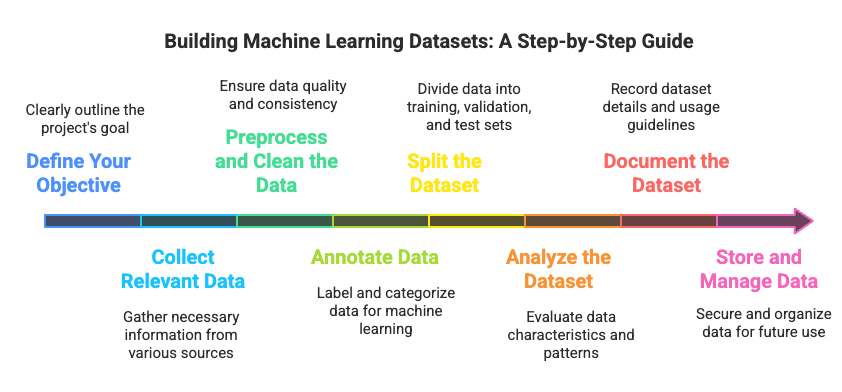
Step 1: Define Your Objective
Before you dive into collecting data, it’s crucial to have a clear understanding of the problem you're trying to solve. Your project’s objective will define what kind of data you need, how you process it, and what type of machine learning model you’ll build. Ask yourself these questions:
- What type of task am I solving? Is it a classification problem (e.g., labeling images as cats or dogs), a regression analysis problem (e.g., predicting house prices), or a recommendation system (e.g., suggesting products based on past purchases)? This is your target variable.
- What output do I want? For instance, are you predicting a continuous value, categorizing items into groups, or detecting anomalies in data?
By clearly defining your objective, you can determine the relevant features and the best way to collect, process, and analyze your data. Your problem type guides the model and preprocessing choices.
For example, if you're building a model to predict house prices, your dataset should include relevant features like square footage, number of bedrooms, neighborhood, etc.
Step 2: Collect Relevant Data
Once you've defined your objective, the next step is to gather the data that aligns with your problem. Depending on your task, you may need a combination of internal and external data sources:
- Web Scraping: If you're dealing with text data, such as reviews or articles, web scraping tools can gather large amounts of data from the web. Python libraries like BeautifulSoup or Scrapy can help extract this information from websites.
- Open-Source Datasets: Many publicly available datasets, such as the UCI Machine Learning Repository, Kaggle, or government databases, can be useful. If they are relevant to your project, these open-source datasets can save you time.
- Internal Data: If you're working for a business or have access to proprietary data, internal datasets from customer transactions, log data, or product information may be invaluable. However, it’s crucial to ensure that this data is legally compliant, especially in fields like healthcare or finance.
When collecting data, ensure it is representative of real-world scenarios and reflects the distributions and edge cases that your model will encounter in its target use case. The more diverse and comprehensive the data, the better the model will perform on new, unseen information.
Step 3: Preprocess and Clean the Data
Data cleaning and preprocessing are some of the most time-consuming steps in building a machine learning dataset. Raw data is rarely ready for immediate use in a model, and improper preprocessing can negatively impact the model’s performance. Here's what to do:
- Handle Missing Data: Missing values can distort your model's predictions. You can either impute missing values using statistical methods (e.g., filling missing entries with the mean or median) or remove rows/columns with too many missing values.
- Remove Duplicates: Duplicate records can skew the learning process, leading to biased patterns in training. Check for and remove duplicate records in your dataset.
- Handle Outliers: Outliers are the values that remarkably differ from the rest of the data and can skew model results. Depending on the context, you can remove or adjust analyzed outliers.
- Standardize/Normalize Data: Some machine learning models (e.g., k-means, neural networks) perform better if numerical data is scaled to a standard range. Standardization (scaling to zero mean and unit variance) or normalization (scaling to a 0-1 range) can help improve model performance.
- Encode Categorical Data: Machine learning algorithms typically require numerical data, so categorical data needs to be converted into a numerical format. Use one-hot encoding for nominal categories (which have no inherent order) or label encoding for ordinal categories (which have a defined order). Avoid applying label encoding to nominal variables, as it may imply false ordinal relationships.
By making sure that your data is clean and properly formatted, you help reduce errors and improve the accuracy of your model.
Step 4: Annotate Data
For supervised machine learning tasks (like classification), annotating your data is essential. This process involves labeling the data so the model knows what it’s supposed to predict. For instance:
- In an image classification project, images of cats and dogs need to be labeled as "cat" or "dog."
- In a sentiment analysis task, text data must be labeled as "positive," "neutral," or "negative."
The process of annotation can be done manually or via semi-automated tools, depending on the scale. If working with large datasets, consider using crowd-sourcing platforms (e.g., Amazon Mechanical Turk) to annotate your data.
Properly labeled data is critical for the model’s learning process and enables the model to learn accurate mappings between inputs and outputs.
Step 5: Split the Dataset
In this step, you'll split your dataset into three distinct subsets: training, validation, and test sets. Each subset plays a key role in training your model effectively. The training set helps your model learn, the validation set tunes the model’s hyperparameters, and the test set ensures an unbiased evaluation of its performance.
This division is crucial for building a robust and generalizable model:
- Training Set: This subset is used to train the model, allowing it to learn patterns and relationships from the data. It should be large enough to provide sufficient information for the model to generalize effectively. Typically, around 70-80% of your data is allocated to this set.
- Validation Set: This set is used during training to tune hyperparameters (e.g., learning rate, batch size). It helps prevent the model from overfitting to the training data, ensuring it generalizes well. About 10-15% of the data is used for validation.
- Test Set: The test set is crucial for evaluating the final model. This data should never be seen during training or validation, as it offers an unbiased evaluation of the model's performance on unseen data. The test set typically makes up the remaining 10-15%.
Ensure that the split is done randomly, or stratified (if the data is imbalanced across classes), to maintain the appropriate distribution of classes in each subset.
Step 6: Analyze the Dataset
After splitting the dataset, it’s crucial to spend time analyzing it. Exploratory Data Analysis (EDA) to gain a deeper understanding of the data. EDA helps uncover patterns, correlations, and potential issues that could affect model performance. Some ways to analyze your dataset include:
- Statistical Summary: Calculate basic statistics like mean, median, standard deviation, and range to understand the data's central tendency and spread.
- Correlation Analysis: Identify relationships between variables (e.g., does house size correlate with price?). This can help you understand which features are most important for predictions.
- Data Visualization: Use plots (e.g., histograms, scatter plots, box plots) to visually inspect the data. Visualizations can reveal patterns, trends, and outliers that might not be immediately obvious in raw data.
This analysis provides insight into the data and can help in feature selection, transformation, or engineering steps.
Step 7: Document the Dataset
Good documentation is key to making your dataset understandable to others (and even to yourself later). Adding details on assumptions, such as exclusions or preprocessing choices, to avoid confusion during deployment. Your documentation should include:
- Data Collection Method: How and where the data was collected, and the rationale for its selection.
- Feature Description: A clear explanation of each feature (column) in the dataset, including its type (numerical, categorical), meaning, and any preprocessing applied.
- Data Quality: An assessment of the dataset’s completeness, consistency, and accuracy.
- License/Usage Terms: If you use external datasets, include the licensing terms for their use, especially if you share them with others.
Proper documentation ensures that anyone working with the dataset can easily understand it, replicate your results, or build upon it.
Step 8: Store and Manage Data
Once your dataset is prepared, it’s crucial to store and manage it properly. Using structured folder hierarchies (e.g., raw/, processed/, final/) aids reproducibility and clarity. Consider the following options:
- Local Storage: If the dataset is small, it may be feasible to store it on your local system. However, this is not scalable for large datasets.
- Cloud Storage: For scalability, accessibility, and security, cloud storage solutions like Amazon S3, Google Cloud Storage, or Azure Blob Storage are excellent options. These platforms provide reliable storage and easy sharing capabilities.
- Data Versioning: As you update and refine your dataset, keep track of versions to ensure reproducibility. Tools like DVC (Data Version Control) or Git LFS (Large File Storage) can help you version control large datasets.
Effective storage ensures your data remains accessible, scalable, and secure.
Advance your career with upGrad’s 12-month program in Master of Science in AI and Data Science in partnership with Jindal Global University. Gain hands-on experience, industry-relevant skills, and a degree from a top-ranked university, all while enjoying flexible online learning and personalized mentorship. Enroll today and start building the skills needed to excel in the AI field.
Meanwhile, using a dataset in machine learning has its own set of benefits and drawbacks. Let’s zoom in on them.
Benefits and Challenges in Working with Dataset in Machine Learning
Working with dataset in machine learning offers many advantages, but it also presents its own set of challenges. Let's examine the benefits and challenges of handling datasets for machine learning projects in more detail.
Aspect | Benefit | Challenge |
Dataset Quality |
|
|
Business Decision Support |
|
|
Model Adaptability |
|
|
Real Life Use Case |
|
|
Increased Model Robustness |
|
|
Also read: The Role of Machine Learning and AI in FinTech Innovation
All right! Now that you have a clearer picture of dataset in machine learning, here’s a small quiz for you.
Quiz to Test Your Knowledge on a Dataset in Machine Learning
Test your understanding of datasets with the following questions:
1. What is the role of a training dataset in machine learning?
a) To evaluate the final performance of the model
b) To provide new, unseen data for the model to predict
c) To help the model learn patterns and relationships in the data
d) To tune the model’s hyperparameters
Answer: c) To help the model learn patterns and relationships in the data
2. How does a validation set help prevent overfitting?
a) By ensuring the model doesn't memorize the training data
b) By providing final evaluation data for the model
c) By increasing the dataset size during training
d) By replacing the training data with fresh data
Answer: a) By ensuring the model doesn't memorize the training data
3. Why is it important to split a dataset into training, validation, and test sets?
a) To increase the model's computation speed
b) To prevent the model from overfitting and evaluate performance on new data
c) To improve data collection efficiency
d) To ensure that all data points are used for training
Answer: b) To prevent the model from overfitting and evaluate performance on new data
4. What are the different types of data used in machine learning models?
a) Numerical, categorical, and image
b) Numerical, categorical, textual, image, audio, time-series
c) Structured, semi-structured, and unstructured
d) Integer, floating-point, and string
Answer: b) Numerical, categorical, textual, image, audio, time-series
5. What is the significance of data preprocessing?
a) To speed up the model training process
b) To ensure the data is clean, consistent, and ready for use by the model
c) To increase the dataset size without adding more data
d) To optimize the model’s architecture
Answer: b) To ensure the data is clean, consistent, and ready for use by the model
6. How can you ensure the quality of a machine learning dataset?
a) By collecting as much data as possible
b) By using data from a single source only
c) By cleaning, handling missing values, removing duplicates, and ensuring relevance
d) By using only publicly available data
Answer: c) By cleaning, handling missing values, removing duplicates, and ensuring relevance
7. What are the challenges you might face when working with machine learning datasets?
a) Data redundancy and overfitting
b) Finding high-quality data, privacy concerns, and data cleaning
c) Too much data availability
d) Data compression and storage issues
Answer: b) Finding high-quality data, privacy concerns, and data cleaning
8. How do open-source and paid datasets differ in terms of accessibility and quality?
a) Open-source datasets are typically more accurate, while paid datasets are harder to access
b) Paid datasets are generally more accessible, and open-source datasets require payment
c) Open-source datasets are free but may be of lower quality, while paid datasets are often curated and of higher quality
d) There is no difference; both types offer the same quality and accessibility
Answer: c) Open-source datasets are free but may be of lower quality, while paid datasets are often curated and of higher quality
9. What are some common sources for finding machine learning datasets?
a) YouTube and social media platforms
b) Kaggle, UCI Machine Learning Repository, and government databases
c) GitHub repositories and company websites
d) Only proprietary data from paid sources
Answer: b) Kaggle, UCI Machine Learning Repository, and government databases
10. How does the size of a dataset impact model accuracy?
a) Larger datasets always lead to better accuracy, regardless of quality
b) The size of a dataset doesn’t matter as long as it’s clean
c) Larger datasets provide more examples for the model to learn from, improving its generalization and accuracy
d) Smaller datasets lead to better accuracy as they are easier to handle
Answer: c) Larger datasets provide more examples for the model to learn from, improving its generalization and accuracy
Also read: Clustering in Machine Learning: Learn About Different Techniques and Applications
How Can upGrad Help You Become an Expert in Machine Learning?
To work effectively with datasets in machine learning, start by understanding data types, handling missing values, and identifying outliers. Use tools like pandas for exploration, scikit-learn for preprocessing, and visualize patterns with matplotlib or seaborn. Always split your data into training and testing sets and ensure consistency in feature scaling. These steps help build reliable, accurate ML models and form the core of any data-driven project.
Machine learning offers exciting opportunities, but mastering datasets and model performance can be challenging. upGrad offers hands-on experience, expert mentorship, and flexible online learning to help you build the skills needed to succeed.
With access to industry-relevant knowledge and a strong alumni network, upGrad equips you to excel in AI and machine learning. Apart from the courses mentioned throughout the blog, here are some other courses offered by upGrad:
- Master’s in Artificial Intelligence and Machine Learning from IIITB
- Executive Diploma in Machine Learning and AI with IIIT-B
- Executive Post Graduate Certificate Programme in Data Science & AI
Struggling to excel at machine learning concepts and unsure where to start? Contact upGrad for a personalized career counseling session or visit the nearest upGrad center to explore your options today!
FAQs
1. What is the difference between a dataset and a database in machine learning?
A dataset in machine learning is a curated collection of data used specifically for training, validating, and testing machine learning models. It is typically structured in rows (samples) and columns (features). A database, on the other hand, is a broader system used to store and manage data for general purposes, including querying, updating, and reporting. Datasets are focused on modeling tasks, while databases are designed for data retrieval and storage.
2. How do I ensure that my machine learning dataset is representative of real-world data?
To ensure your dataset is representative, you should gather data from diverse sources, ensuring it covers all possible scenarios your model might encounter. It's crucial to capture variations in the data (e.g., seasonal trends, different customer demographics) and ensure the sample size is large enough to reflect the complexity of the real-world problem you're solving. This prevents your model from being biased toward specific types of data.
3. How do I handle missing values in a dataset?
Missing values can be handled in multiple ways depending on the situation. You can impute missing values using statistical methods like the mean, median, or mode. Alternatively, you can drop rows or columns with missing values if they are not essential or if the dataset is large enough to afford the loss of data. Another approach is to use machine learning models that can handle missing data, such as tree-based models, which can often deal with missing values internally.
4. How do I know if my dataset is balanced or imbalanced?
To determine if your dataset is balanced or imbalanced, check the distribution of your target variable (the variable you are trying to predict). In a balanced dataset, the classes (or categories) should have roughly equal representation. If one class significantly outnumbers the other, it’s an imbalanced dataset. This imbalance can lead to biased model predictions, so techniques like resampling, SMOTE, or using class weights can help address this issue.
5. What are the key steps in cleaning a dataset before training a machine learning model?
The key steps in cleaning a dataset include: Handling missing values by imputing or removing them.Removing duplicates to avoid skewing the results.Identifying and handling outliers, which can distort the model's performance.Standardizing or normalizing numerical features to ensure consistency.Encoding categorical features into a numerical format (e.g., one-hot encoding or label encoding). Handling missing values by imputing or removing them. Removing duplicates to avoid skewing the results. Identifying and handling outliers, which can distort the model's performance. Standardizing or normalizing numerical features to ensure consistency. Encoding categorical features into a numerical format (e.g., one-hot encoding or label encoding). By ensuring the data is clean and consistent, you improve the accuracy and efficiency of the model.
6. Can a small dataset still be useful for machine learning?
While larger datasets generally lead to more accurate models, a small dataset can still be useful if it’s of high quality and representative of the problem you’re solving. Techniques like data augmentation (for image data), transfer learning (using pre-trained models), and cross-validation can help maximize the performance of models trained on small datasets. However, it's important to be aware that small datasets can sometimes lead to overfitting, where the model memorizes the data rather than generalizing.
7. Why is feature engineering important when building a machine learning dataset?
Feature engineering is the process of selecting, modifying, or creating new features from raw data to improve the model’s performance. It’s important because well-engineered features can significantly enhance the model's ability to learn patterns and make accurate predictions. For example, converting raw time data into meaningful features like hour of day, day of week, or holiday indicators can improve predictive models for demand forecasting or sales predictions.
8. How can I evaluate the quality of a machine learning dataset?
To evaluate the quality of a dataset, you should check for the following: Completeness: Ensure there are no missing or incomplete data points.Consistency: Verify that the data follows the same format and structure throughout.Relevance: Ensure the data is closely aligned with the problem you are solving.Balance: Ensure that there is an adequate representation of all categories (especially in classification tasks).Accuracy: The data should be error-free and correct. Completeness: Ensure there are no missing or incomplete data points. Consistency: Verify that the data follows the same format and structure throughout. Relevance: Ensure the data is closely aligned with the problem you are solving. Balance: Ensure that there is an adequate representation of all categories (especially in classification tasks). Accuracy: The data should be error-free and correct.
9. What tools can I use to preprocess and clean datasets?
There are several tools and libraries available to preprocess and clean datasets. For instance: Pandas: Used for data manipulation and handling missing values.NumPy: Useful for numerical operations and handling large datasets.Scikit-learn: Provides tools for data scaling, encoding, and splitting datasets.OpenRefine: A powerful tool for data cleaning and transformation.TensorFlow Data: TensorFlow offers preprocessing utilities for machine learning tasks, especially for deep learning. Pandas: Used for data manipulation and handling missing values. NumPy: Useful for numerical operations and handling large datasets. Scikit-learn: Provides tools for data scaling, encoding, and splitting datasets. OpenRefine: A powerful tool for data cleaning and transformation. TensorFlow Data: TensorFlow offers preprocessing utilities for machine learning tasks, especially for deep learning.
10. How do I split my dataset into training, validation, and test sets?
The typical approach for splitting a dataset is: Training Set (60-80%): Used to train the model.Validation Set (10-20%): Used to fine-tune hyperparameters and tune the model.Test Set (10-20%): Used for final evaluation to assess how well the model performs on unseen data. Training Set (60-80%): Used to train the model. Validation Set (10-20%): Used to fine-tune hyperparameters and tune the model. Test Set (10-20%): Used for final evaluation to assess how well the model performs on unseen data. You can use functions from libraries like Scikit-learn to split your dataset randomly or using stratified sampling (for imbalanced datasets).
11. What are some best practices for handling large datasets?
When working with large datasets, it’s important to: Use batch processing: Break the dataset into smaller chunks to reduce memory usage and improve efficiency.Use cloud storage and computation: Platforms like AWS, Google Cloud, and Azure allow you to store and process large datasets without running into local resource limitations.Optimize data types: Convert data types (e.g., integers vs. floats) to save memory.Sampling: Use random or stratified sampling to work with a smaller, manageable subset of the data if the full dataset is too large to handle efficiently. Use batch processing: Break the dataset into smaller chunks to reduce memory usage and improve efficiency. Use cloud storage and computation: Platforms like AWS, Google Cloud, and Azure allow you to store and process large datasets without running into local resource limitations. Optimize data types: Convert data types (e.g., integers vs. floats) to save memory. Sampling: Use random or stratified sampling to work with a smaller, manageable subset of the data if the full dataset is too large to handle efficiently.
12. How do I document a machine learning dataset for future use or sharing?
Documenting a machine learning dataset involves providing a detailed explanation of: Data collection methods: How the data was gathered and its sources.Feature descriptions: Explanation of each column/attribute in the dataset.Data preprocessing steps: Any cleaning, transformation, or encoding done on the data.License/Usage terms: If using an external dataset, include licensing information to ensure compliance. Data collection methods: How the data was gathered and its sources. Feature descriptions: Explanation of each column/attribute in the dataset. Data preprocessing steps: Any cleaning, transformation, or encoding done on the data. License/Usage terms: If using an external dataset, include licensing information to ensure compliance. Documentation ensures that others (or even your future self) can understand, use, and replicate your work effectively.





upGrad Learner Support
Talk to our experts. We are available 7 days a week, 10 AM to 7 PM
Indian Nationals
Foreign Nationals
Disclaimer
The above statistics depend on various factors and individual results may vary. Past performance is no guarantee of future results.
The student assumes full responsibility for all expenses associated with visas, travel, & related costs. upGrad does not .