All courses
Agentic AI
Agentic AI
Artificial Intelligence
Degree / Exec. PG

IIIT Bangalore
Executive Diploma in Machine Learning and AI
OPJ Global University
Master’s Degree in Artificial Intelligence and Data Science
Liverpool John Moores University
Master of Science in Machine Learning & AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIExecutive Certificate

IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
IIIT Bangalore
Executive Programme in Generative AI for Leaders
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceOffline Bootcamps

upGrad
Data Science and AI-MLDoctorate
For All Domains
IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
Swiss School of Business and Management
Global Doctor of Business Administration from SSBM
Edgewood University
Doctorate in Business Administration by Edgewood UniversityGolden Gate University
Doctor of Business Administration From Golden Gate University
Rushford Business School
Doctor of Business Administration from Rushford Business School, SwitzerlandGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)-d9bdeff6165f4eb1ba2adcebde78e961.svg)
University of Waterloo
Chief Technology and AI Officer ProgramLeadership / AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIMachine Learning
Machine Learning
Data Science
Degree / Exec. PG
O.P Jindal Global University
Master’s Degree in Artificial Intelligence and Data ScienceIIIT Bangalore
Executive Diploma in Data Science & AILiverpool John Moores University
Master of Science in Data ScienceExecutive Certificate
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceupGrad | Microsoft
Gen AI Mastery Certificate for Content CreationOffline Bootcamps
upGrad
Data Science and AI-MLupGrad
Data AnalyticsMBA
Masters

Paris School of Business
Master of Science in Business Management and TechnologyO.P.Jindal Global University
MBA (with Career Acceleration Program by upGrad)Edgewood University
MBA from Edgewood UniversityO.P.Jindal Global University
MBA from O.P.Jindal Global UniversityGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)Executive Certificate

IMT, Ghaziabad
Advanced General Management ProgramMarketing
Executive Certificate
Offline Bootcamps
upGrad
Digital MarketingManagement
Degree
O.P Jindal Global University
MSc in International Accounting & Finance (ACCA integrated)Paris School of Business
Master of Science in Business Management and Technology
Golden Gate University
Master of Arts in Industrial-Organizational PsychologyExecutive Certificate

IIM Kozhikode
Human Resource Analytics Course from IIM-KupGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftEducation
Education

Northeastern University
Master of Education (M.Ed.) from Northeastern UniversityEdgewood University
Doctor of Education (Ed.D.)Edgewood University
Master of Education (M.Ed.) from Edgewood UniversityCertifications
Project Management
Certification

Knowledgehut
Leadership And Communications In ProjectsKnowledgehut
Microsoft Project 2007/2010-ae8d039bbd2a41318308f8d26b52ac8f.svg)
Knowledgehut
Financial Management For Project ManagersKnowledgehut
Fundamentals of Earned Value Management (EVM)Knowledgehut
Fundamentals of Portfolio ManagementKnowledgehut
Fundamentals of Program Management-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
Knowledgehut
CAPM® CertificationsKnowledgehut
Microsoft® Project 2016Certifications & Trainings
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)
Knowledgehut
PMP® CertificationKnowledgehut
PMI-RMP® CertificationKnowledgehut
PMP Renewal Learning PathKnowledgehut
Oracle Primavera P6 V18.8Knowledgehut
Microsoft® Project 2013Knowledgehut
PfMP® Certification CourseKnowledgehut
Project Planning and MonitoringPrince2 Certifications

Knowledgehut
PRINCE2® FoundationKnowledgehut
PRINCE2® PractitionerKnowledgehut
PRINCE2 Agile Foundation and PractitionerKnowledgehut
PRINCE2 Agile® Foundation CertificationKnowledgehut
PRINCE2 Agile® Practitioner CertificationManagement Certifications
Knowledgehut
Project Management Masters Certification ProgramKnowledgehut
Change ManagementKnowledgehut
Project Management TechniquesKnowledgehut
Product Management Certification ProgramKnowledgehut
Project Risk Management- Study abroad
- Offline centres
- uGSOT - B.Tech
More



49. Variance in ML
What Is the Drawback of Machine Learning Approaches? 21 Major Limitations Listed
Did you know? 15% of machine learning professionals say monitoring and observability are their biggest challenges in production! Keeping track of model performance in real-world scenarios is crucial but often overlooked. Without proper monitoring, even the best models can lose their edge over time.
The development of large language models (LLMs) by leading companies like Google, Meta, and OpenAI has ushered in a new era of information technology. However, machine learning (ML) approaches, despite their massive contribution to the modern world, also come with several limitations. These key drawback of machine learning approaches include dependency on large datasets. Addressing these obstacles is essential for realizing the true potential of ML in the real world.
This blog will explore the technical, ethical, and practical drawbacks of machine learning, highlighting limitations of machine learning that need to be addressed as the technology continues to advance.
Are you looking to learn more about machine learning and enhance your AI skills? Upskill with top Artificial Intelligence and machine Learning programs. By learning from the best universities, you can become a part of the Gen AI generation. Enroll today!
What Is the Drawback of Machine Learning Approaches? A Detailed Overview
According to McKinsey, AI could add $4.4 trillion in productivity growth through corporate use, highlighting major progress in automating tasks and generating insights. However, challenges like biased training data, lack of transparency, and poor handling of edge cases limit adoption in sensitive fields like healthcare and finance, raising concerns about reliability and fairness.
These problems can directly impact your trust in ML systems and their ability to make accurate, ethical decisions.
If you're looking to advance your skills in AI and machine learning, these courses can help you succeed:
- Executive Programme in Generative AI for Leaders
- Master of Science in Machine Learning & AI
- Executive Diploma in Machine Learning and AI
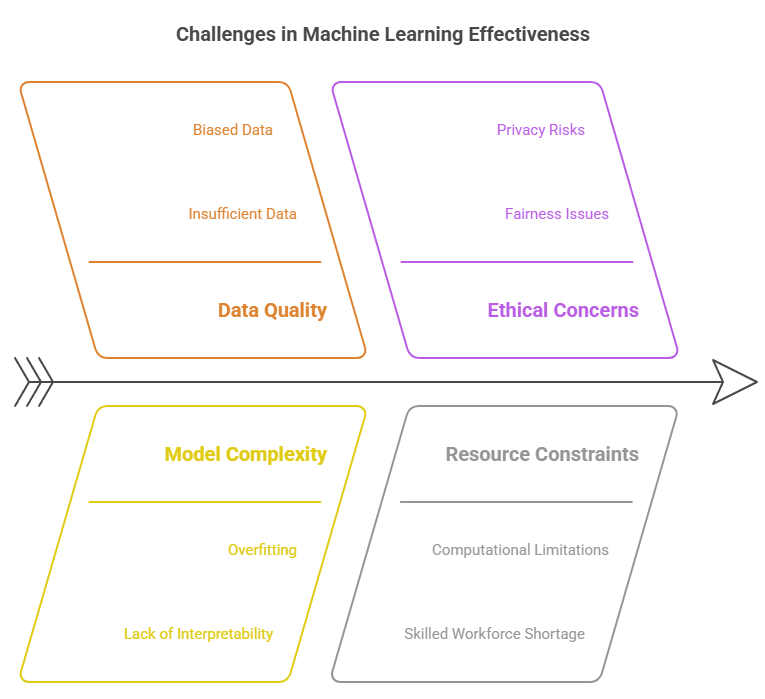
Below, you’ll explore the very first drawback of machine learning approaches that needs to be addressed by you. Concept of accuracy vs. generalization in ML models sheds light on how this trade-off influences their effectiveness in diverse scenarios.
1. Accuracy vs. Generalization in ML Models
One of the widely discussed disadvantages of machine learning is that its high performance on training data doesn't always mean that it will lead to real-world success. What truly matters is how well a model generalizes to new, unseen data. So creating the right balance between accuracy and generalization is the most important thing for building adaptable, reliable models.
- Accuracy: It measures a model's performance on training data, but doesn't reflect how well it performs on unseen data.
- Generalization: Ensuring a model performs well on new data can be improved with cross-validation, which tests consistency, and regularization, which controls model complexity to prevent overfitting.
- Feature Selection: Reducing the number of irrelevant or redundant features helps simplify the model, improving its ability to generalize while minimizing overfitting.
Example: In a fraud detection system, cross-validation can help ensure the model does not focus on specific patterns seen in past fraud cases but instead generalizes to detect new, unforeseen fraudulent behavior. These methods ensure that the model is not only accurate but also adaptable to different datasets.
2. Overfitting and Underfitting Risks
Overfitting and underfitting are two common disadvantages of machine learning that can significantly impact a model’s performance. To address these risks, techniques like cross-validation and regularization can be effective. Cross-validation helps identify overfitting by testing the model on multiple data subsets, ensuring it performs well across different sets and not just the training data. Regularization techniques, such as L1 and L2 regularization, penalize overly complex models, encouraging them to focus on the most relevant features.
- Overfitting: It occurs when a model captures noise in the training data, making it perform poorly on new, unseen data due to a lack of generalization.
- Underfitting: This happens when a model is too simplistic, failing to capture key patterns, resulting in poor performance on both training and test data.
- Decision Tree Pruning: By trimming a decision tree, it avoids excessive depth and specificity, reducing the likelihood of overfitting and improving generalization.
Example: In a healthcare setting, suppose a hospital builds a machine learning model to predict whether a patient is at risk of developing diabetes. An overfitted model might latch onto rare combinations of symptoms present in the training data, like a specific blood sugar level paired with an unusual dietary habit. Making it highly accurate on that dataset, but unreliable for new patients with different but relevant indicators.
3. Data Dependency and Quality Concerns
Machine learning models are highly dependent on the data used for training, and their performance is directly linked to both the quantity and quality of that data. The old proverb "garbage in, garbage out" holds true in ML, meaning that if a model is trained on poor-quality data, the results will likely be inaccurate or biased, no matter how advanced the algorithm is. To overcome this drawback of machine learning approaches, the following methods can be used.
- Outlier Detection: Identifying variations in the data helps prevent rare, unrepresentative cases from skewing model predictions and affecting accuracy.
- Bias Audits: Regular audits of the dataset and model outputs help detect and mitigate biases, ensuring fair and unbiased decision-making.
- Using Diverse and Representative Datasets: Training with diverse data that mirrors real-world applications improves model fairness and reduces the risk of biased or incomplete performance.
Example: Facial recognition technology often performs poorly when primarily trained on images of people from one ethnicity, leading to inaccurate and unfair results when identifying faces from other ethnic backgrounds.
4. Explainability and Interpretability Issues
Explainability and interpretability are essential for ensuring transparency, trust, and accountability in machine learning models, particularly in high-stakes fields like healthcare and finance. To improve explainability and interpretability, tools like SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations) can provide critical insights into black-box models.
- Explainability: It focuses on understanding the rationale behind a model's decision, helping stakeholders grasp why a specific outcome occurred.
- Interpretability: It involves making the decision-making process of a model transparent and comprehensible to humans, aiding in trust and validation.
- SHAP Values: SHAP values show the contribution of each feature to a model’s prediction, helping to explain decision factors like age or income.
- LIME: LIME creates simpler, interpretable models for specific predictions, enabling users to understand the reasoning behind a model's choice.
Example: In industries such as healthcare, where AI models might predict diagnoses or recommend treatments, explainability is a must. Doctors need to trust not only the prediction but also the reasoning behind it. Suppose an AI model predicts a patient's diagnosis, but the healthcare provider cannot understand how the decision was reached. In that case, they might be hesitant to use the model, even if it’s accurate.
5. Need for Large Labeled Datasets
ML, especially deep learning, relies heavily on large labeled datasets, which can be costly and time-consuming to create, particularly in specialized fields like healthcare or law where expert annotation is required. To ease this burden, techniques like semi-supervised learning are used. This technique combines a small amount of labeled data with a larger pool of unlabeled data. This approach allows models to learn from patterns in the unlabeled data, improving performance while reducing the dependency on extensive labeled datasets.
- Active Learning: The model selects the most informative data points for labeling by human annotators, improving learning efficiency with fewer labeled examples.
- Transfer Learning: Models pre-trained on large datasets can be fine-tuned on smaller datasets from a different domain, reducing the need for extensive data and training time.
- Data Augmentation: Variations of labeled data are created through transformations like rotation or scaling, enhancing model performance, especially in image and speech recognition.
Example: Training a self-driving car's perception system requires millions of labeled images representing different driving conditions, which can be highly resource-intensive to collect. This immense labeling task poses a huge challenge, particularly for companies developing autonomous vehicles, as they need diverse, high-quality data for various road scenarios. So the above technique can come in handy during this training.
6. Resource-Intensive Training and Deployment
Training and deploying machine learning models, especially deep learning models, require substantial computational power. This makes it a one of the huge limitations of machine learning, particularly for smaller organizations or projects with limited resources. These models often require specialized hardware like Graphics Processing Units (GPUs) or Tensor Processing Units (TPUs) to process vast amounts of data in parallel and accelerate the training process.
- Cloud Computing Services: AWS, Google Cloud, and Azure provide scalable, on-demand access to powerful GPU and TPU resources, removing the need for large initial investments.
- Model Optimization Techniques: Techniques like pruning, quantization, and knowledge distillation reduce model size and complexity, improving training speed and efficiency.
- Transfer Learning: Pre-trained models can be fine-tuned for specific tasks, drastically cutting down on training time and computational resource usage.
Example: Training large language models or in image recognition tasks, instead of training a model from scratch, a pre-trained model like ResNet or VGG, which has already been trained on a large dataset like ImageNet, can be fine-tuned for a specific use case, such as medical image classification.
7. Bias Amplification from Training Data
ML models can unintentionally put existing biases in the data they are trained on, leading to biased or unfair outcomes. This issue, known as bias amplification, occurs when models learn patterns from biased training data and perpetuate or even exacerbate those biases. These biases are some limitations of machine learning, so to address this issue, several strategies can be used to detect and mitigate bias in machine learning models.
- Bias Detection Tools: These tools analyze model predictions to identify and flag biased or discriminatory patterns, ensuring fairness in outcomes.
- Fairness Constraints: Explicit fairness objectives are used in the model's optimization process to ensure decisions align with fairness standards.
- Adversarial Debiasing: A second model predicts bias in the primary model’s predictions, prompting adjustments to reduce bias and promote fairer decision-making.
Example: Bias mitigation is seen in the COMPAS algorithm, which was used in the criminal justice system and has been criticized for racial bias. In response to these concerns, several organizations and researchers have worked on debiasing techniques, including bias detection tools and fairness constraints, to reduce disparities in sentencing recommendations.
8. Challenges in Updating Deployed Models
Once ML models are deployed, keeping them up-to-date with new data or changing conditions can be a huge challenge. Without regular updates, models can become outdated, leading to poor performance and unreliable predictions. This is particularly problematic in industries like finance, healthcare, or e-commerce, where data is constantly changing and models must adapt to maintain their effectiveness.
- Continuous Learning: Models are retrained with new data to continuously incorporate fresh information, improving their relevance and accuracy over time.
- Model Monitoring: Tools are set up to track performance metrics, allowing companies to detect and address issues like accuracy decline or increasing bias.
- Incremental Learning: Models are updated in smaller, manageable increments, reducing the need for full retraining and making them more efficient.
Example: In the field of financial institutions that use machine learning for credit scoring, they can deploy model monitoring and incremental learning techniques to ensure their models adapt to changing economic conditions and new consumer behaviors.
9. Lack of Causal Reasoning
While ML models excel at identifying patterns and correlations in data, they cannot inherently understand causal relationships. This is one of the huge limitations of machine learning that becomes particularly significant in industries. Especially in areas where decisions need to be made based on cause-and-effect reasoning, such as in sectors like healthcare, economics, and policy-making. Without an understanding of causality, an ML model may suggest correlations that, although accurate, do not necessarily imply a direct causal relationship.
- Causal Inference and Causal Graphs: These techniques visually represent causal relationships between variables, helping to distinguish correlation from causation and guiding decision-making.
- Causal Machine Learning Models: Unlike traditional ML models, causal machine learning approaches can assess cause-and-effect relationships, making them crucial for policy-making and understanding underlying mechanisms.
- Econometric Techniques: Methods like difference-in-differences and causal Bayesian networks allow a deeper understanding of the impact of actions and interventions, aiding in more accurate economic analysis.
Example: An ML model might predict that high temperatures correlate with increased ice cream sales. However, it cannot inherently understand the causal relationship that high temperatures cause more ice cream sales unless it's specifically designed to perform causal inference. So, the above techniques can come in handy to counter situations like these.
10. Narrow Task Specialization
ML models are typically designed to excel in specific tasks, such as image classification, speech recognition, or recommendation systems. However, this narrow task specialization can present challenges when attempting to apply these models to broader or more complex domains. Models trained for a particular purpose often lack the flexibility to adapt to tasks outside of their designated scope, leading to suboptimal performance when faced with new or diverse challenges.
- Multi-task Learning: This technique trains a model to handle multiple tasks simultaneously, enabling it to share knowledge across domains and improving flexibility.
- Transfer learning: Using pre-trained models and fine-tuning them for related tasks allows models to transfer knowledge and adapt quickly, minimizing the need for extensive data.
- Few-shot Learning: This technique enables models to learn new tasks with minimal data by using prior knowledge, helping overcome narrow task specialization with limited labeled examples.
Example: Models like BERT or GPT are initially trained on a wide range of tasks using massive amounts of text data, enabling them to adapt to a variety of natural language processing tasks such as sentiment analysis, translation, or text summarization. By using transfer learning, these models can be fine-tuned for specific tasks with smaller datasets, making them more versatile in handling different linguistic challenges.
11. Difficulty in Handling Out-of-Distribution Data
The significant drawback of machine learning approaches is that the ML model can struggle to handle data that is largely different from what they were trained on, a challenge known as out-of-distribution (OOD) data. This issue arises when a model encounters new data that falls outside the range of its training distribution, causing a decline in performance. For example, a model trained on images of urban environments may perform poorly when applied to rural or indoor settings, as the features and patterns in these environments differ from the training data.
Several techniques can help mitigate the problem of OOD data, such as domain adaptation and domain generalization.
- Domain Adaptation: This technique adjusts a model trained on one domain to perform well on another related domain by using both labeled data from the source and unlabeled data from the target.
- Domain Generalization: Unlike domain adaptation, domain generalization builds models that can generalize across multiple domains without requiring fine-tuning, enabling robustness across various data sources.
- Data Augmentation: This technique expands the training data artificially by modifying existing data (e.g., rotating images or altering lighting), making the model more robust and adaptable to diverse domains.
Example: A model trained to recognize objects in clear daylight images might struggle when applied to pictures taken at night. To overcome this, data augmentation could involve creating new images by adjusting the lighting conditions. Domain adaptation might involve fine-tuning the model on a set of nighttime images (unlabeled) while using the daytime images (labeled), enabling the model to handle both lighting conditions. Lastly, domain generalization would involve training the model on a wide variety of environmental conditions.
12. Misalignment with Human Goals or Context
ML models can sometimes prioritize objectives that do not align with human values or the broader real-world context, leading to undesirable outcomes. This misalignment occurs when the model is optimized to achieve certain performance metrics, but those metrics fail to account for ethical, social, or situational considerations that are important for making well-rounded, human-centered decisions.
- Misalignment in Decision-Making: When ML models prioritize specific metrics like efficiency or profit without considering human goals, it can lead to actions that conflict with safety, fairness, or societal values.
- Addressing Misalignment: Incorporating human values into the training process, such as through value-sensitive design, ensures that ethical considerations are part of the system's design from the start.
- Human-in-the-Loop: In ML, human-in-the-loop involves using human oversight during the model's decision-making process, ensuring that humans validate final decisions to maintain ethical standards and context-specific relevance.
Example: An AI system optimized for efficiency in a factory might prioritize production speed to meet high output targets. While this improves the factory’s overall efficiency, the system could push workers to perform tasks faster than they can safely manage, ultimately leading to unsafe working conditions or higher accident rates. In such a case, the above methods can be implemented to overcome this drawback of machine learning approaches.
13. Fragility to Small Disruptions
ML models, particularly deep learning models, can be highly sensitive to small changes in the input data, a phenomenon known as fragility to small disruptions. This vulnerability is one of the major disadvantages of machine learning, as it can cause a model to produce drastically different outputs when even slight, imperceptible changes are made to the input data. In real-world applications, where data can be noisy, incomplete, or subject to fluctuations, such fragility can lead to significant performance issues, making the model unreliable and inconsistent.
- Robust Optimization: This method involves adjusting the model's training process to specifically account for potential disruptions, improving its ability to maintain performance even when faced with slight changes or noise in the input data.
- Cross-Validation: By testing the model on different subsets of the data, cross-validation ensures that the model is not overly dependent on any one specific part of the data, reducing its vulnerability to small disruptions.
- Adversarial Training: This technique involves training the model with adversarial examples, intentionally disturbed data to make the model more robust against small, unexpected changes or disruptions in input data.
Example: Autonomous driving systems, a slight change in lighting conditions, or a small obstruction in the sensor’s view can lead to the car making incorrect decisions, potentially compromising safety. Similarly, in facial detection systems, models can misclassify images if small, imperceptible alterations are made, such as adding noise to a picture or slightly shifting an object’s position. This fragility reduces the model’s robustness and its ability to operate in dynamic, real-world environments where conditions often vary unexpectedly.
14. Black-Box Behavior in Decision-Making
Deep learning models, especially complex ones, are often seen as "black boxes" because it's hard to understand how they make decisions. While they perform well in tasks like image recognition or self-driving cars, this lack of transparency is a major issue. To address this, one of the major disadvantages of machine learning, caused by black-box behavior, several techniques can be applied to improve the interpretability and transparency of deep learning models.
- Surrogate Models: Simpler models like decision trees or linear models are trained to approximate the behavior of complex black-box models, providing clearer insights into their decision-making process.
- Attention Mechanisms: In image recognition and NLP, attention mechanisms highlight important features (e.g., words or image regions), improving transparency by showing which data aspects influence the model's predictions.
- Feature Importance Techniques: Techniques like SHAP and LIME analyze the contribution of each feature to a model's decision, offering deeper insights into how individual variables impact predictions.
Example: In credit scoring, a black-box model might make loan approval decisions without clear transparency. Surrogate models, like decision trees, can be used to approximate and explain the model’s decision-making process. SHAP values can highlight which specific factors, such as credit history, income, or spending patterns, influenced the decision most. This approach ensures that both lenders and applicants understand the rationale behind the decision.
15. Absence of True Adaptability Without Retraining
As new data or changes in conditions occur, ML models need to be regularly updated to maintain their performance, which can be resource-intensive and time-consuming. This lack of true adaptability presents a challenge for long-term deployment, especially in scenarios where the environment is constantly evolving or when rapid changes in input data are expected. To address this major limitation, among other disadvantages of machine learning, several techniques can be implemented. Below are some of them.
- Online Learning: Models are trained incrementally as new data is available, enabling real-time adaptation without full retraining, making them more responsive to change.
- Reinforcement Learning: In this approach, models learn from interacting with their environment, receiving feedback in the form of rewards or penalties to improve their decision-making over time.
- Transfer Learning: Pre-trained models can be fine-tuned for new tasks, allowing them to adapt quickly with less data and fewer computational resources.
Example: In the case of a smart thermostat, a model might learn a household's temperature preferences and adjust the environment accordingly. However, without retraining, it may struggle to adapt if there are significant changes, such as a change in occupancy patterns or a new energy-saving initiative. By using online learning, the thermostat system can continuously adjust to new data, such as changes in the number of people in the home or varying weather conditions, ensuring it maintains efficiency without manual updates.
16. Security Vulnerabilities and Adversarial Attacks
ML models are vulnerable to adversarial attacks, where small, carefully crafted changes to the input data can cause the model to make incorrect predictions. These attacks exploit the model's weaknesses and can lead to significant security risks, especially in high-stakes environments like autonomous driving, finance, and healthcare. Models are susceptible to adversarial attacks, where malicious alterations to input data can trick the model into making incorrect predictions or classifications. The methods below can help mitigate this drawback of machine learning approaches.
- Regularization Techniques: Methods like dropout and weight decay prevent overfitting, making models more resilient to adversarial examples by avoiding reliance on specific patterns.
- Detection and Monitoring: Adversarial example detectors identify tampered inputs, flagging suspicious data before it reaches the main model, thus protecting it from adversarial attacks.
- Adversarial Training: This technique involves training the model with adversarial examples, helping it learn to recognize and resist manipulation, making it more robust against such attacks.
Example: In autonomous vehicles, adversarial attacks could involve small, hardly visible changes to road signs, such as altering the shape or color of a stop sign, which could trick the vehicle's image recognition model into not recognizing it as a stop sign. By employing adversarial training, the vehicle’s model can be trained with these altered images, helping it learn to detect and correctly respond to such attacks. Plus, detection and monitoring systems could flag suspicious changes in the environment.
17. Ethical Concerns Around Privacy and Surveillance
ML models are increasingly used in sensitive areas like healthcare, law enforcement, and public spaces, raising ethical concerns about privacy and surveillance. As these models process personal data, they can inadvertently compromise individual privacy or enable unauthorized surveillance. Ensuring that ML systems adhere to ethical standards becomes critical to protect individuals' rights and avoid misuse of technology.
- Data Anonymization: Removes or encrypts PII from datasets, preserving privacy while still allowing effective model training.
- Consent and Transparency: Ensures individuals are informed and give consent, fostering trust and compliance with privacy regulations.
- Privacy-Preserving Techniques: Methods like federated learning and differential privacy enable model training without exposing personal data, maintaining privacy.
Example: Facial recognition systems deployed in public spaces can lead to unauthorized surveillance, infringing on personal privacy, and potentially leading to misuse. Ensuring ethical implementation requires setting clear boundaries on where and how such systems are used, along with implementing privacy-preserving techniques like data anonymization and opt-in consent mechanisms.
18. Job Displacement and Workforce Impact
The rise of machine learning-driven automation has the potential to significantly alter the job market. While it brings efficiencies, reduces costs, and enhances productivity, it also raises concerns about job displacement, particularly in industries reliant on routine or repetitive tasks.
Automation powered by ML is already making substantial inroads into sectors like manufacturing, customer service, and transportation, where machines and algorithms can perform tasks traditionally done by humans. To address these disadvantages of machine learning, reskilling programs and policy frameworks are critical for helping workers adapt to new job demands and technological advancements.
- Reskilling Programs: These programs help workers acquire new skills for emerging industries, such as robotics maintenance or AI programming, reducing job displacement from automation. Public-Private Collaboration: Governments and private companies can partner to create workforce development programs, reskilling workers in sectors like green energy, digital tech, and healthcare. Policy Frameworks: Governments can implement policies that protect workers from automation’s impact, promote responsible automation, and ensure equitable distribution of its benefits.
Example: In customer service, while AI chatbots have replaced some human agents, they also create new opportunities for workers to move into more complex roles, such as AI training, system maintenance, or customer experience design. For instance, chatbots require human oversight to ensure that they are functioning properly and improving over time, which creates a need for workers with a deep understanding of AI systems and human interaction.
19. Limitations of Deep Learning Within Machine Learning
While deep learning has shown remarkable success across various applications, such as computer vision, natural language processing, and autonomous driving, it also comes with its own set of challenges that can hinder its effectiveness. These limitations often arise in situations where resources, data availability, or interpretability are critical. Understanding these disadvantages of machine learning is important for anyone looking to deploy deep learning in real-world scenarios, where these models need to be both effective and efficient.
Opaqueness of Multi-Layered Neural Networks
Multi-layered neural networks, a core component of deep learning, are often considered "black boxes" due to their complexity.
- Their intricate architecture makes it difficult to interpret or explain how the model reaches a specific decision, which can be problematic in industries where transparency and accountability are crucial.
Example: A deep neural network used for image classification might make accurate predictions, but it's hard to explain why a specific image was classified in a certain way.
Need for Massive Computation Power
Training deep learning models demands substantial computational resources, often making it difficult for smaller organizations to participate in cutting-edge AI research.
- The need for specialized hardware, such as GPUs or TPUs, increases the cost and complexity of model development, limiting accessibility for those without advanced infrastructure.
Example: Training large-scale neural networks for tasks like natural language processing (NLP) can require specialized hardware like GPUs or TPUs, which are expensive.
Poor Performance on Small or Noisy Datasets
Deep learning models rely on large, high-quality datasets to achieve optimal performance.
- When trained on small or noisy datasets, these models struggle to generalize and often fail to make accurate predictions, limiting their usefulness in scenarios where data is scarce or unreliable.
Example: In medical imaging, deep learning models may not perform well if trained on a small dataset with inconsistent labeling, leading to poor generalization to new images.
Also read: Advanced AI Technology and Algorithms Driving DeepSeek: NLP, Machine Learning, and More
While these limitations highlight machine learning's inherent challenges, it's crucial to understand how these drawbacks play out in modern use cases. Let’s explore this below.
Scope and Limitations of Machine Learning in Modern Use Cases
Machine learning has proven to be a powerful tool across various industries, offering innovative solutions and automating complex tasks. However, there are huge drawback of machine learning approaches that can limit their effectiveness in certain use cases. These include a reliance on large, high-quality data sets, a lack of model interpretability, challenges in generalization, and high computational costs.
Understanding the limitations of machine learning is important for effectively implementing machine learning while ensuring its reliability and scalability in real-world scenarios. Let’s explore more about both the scope and limitations below.
-86bd5afc678c4d8980f754d45e91d211.png)
Where ML Excels: Pattern Recognition and Automation
Machine learning thrives in tasks that involve pattern recognition and automating repetitive processes. Here’s where it performs best:
- Pattern Recognition: ML algorithms can spot complex patterns in large datasets that humans might miss, enabling accurate predictions and insights.
- Automation: By automating repetitive tasks, ML frees up human resources for more creative and strategic activities.
- Large-Scale Data Analysis: ML is ideal for processing and analyzing massive datasets, providing valuable insights in fields like finance, healthcare, and e-commerce.
- Specific Applications: Common use cases include spam detection, product recommendations, customer segmentation, image recognition, and fraud detection.
Where ML Falls Short: Judgment, Context, and Common Sense
Despite its many advantages, ML has notable shortcomings in understanding complex, nuanced situations:
- Judgment: ML models can't make subjective decisions or understand the differences in specific contexts.
- Context: ML struggles to comprehend the broader implications or the context behind its decisions.
- Common Sense: Lacking inherent common-sense reasoning, ML models often fail in tasks that require human-like intuition and problem-solving.
- Bias: ML models can unintentionally perpetuate biases from the training data, leading to unfair or skewed outcomes.
- Data Dependency: The effectiveness of ML models is contingent on the availability of high-quality, sufficient training data, which can be costly and time-consuming to acquire.
Trade-offs in Scalability, Accuracy, and Interpretability
As ML continues to evolve, there are trade-offs that must be considered for optimal performance:
- Scalability: The more complex the model, the greater the need for data and computational resources. Scaling ML systems can become resource-intensive.
- Accuracy: High accuracy is often achievable, but it depends heavily on the quality and quantity of data. The performance of ML models can fluctuate based on the task’s complexity.
- Interpretability: Complex ML models, such as deep learning systems, are often seen as black boxes, making it challenging to explain how they arrive at certain predictions.
- Explainability: The lack of interpretability in some ML models can hinder their adoption, especially in fields that require transparency and accountability, such as healthcare and finance.
Read More: Top 48 Machine Learning Projects [2025 Edition] with Source Code
As you continue to enhance your understanding of machine learning and its applications, you might be wondering how to translate that expertise into a successful career. Here’s how upGrad can support you in advancing your skills and achieving your career objectives in the rapidly evolving field of AI and machine learning.
Conclusion
Understanding machine learning's limitations, like data dependency, limited adaptability, sensitivity to small changes, and more, is essential for applying it effectively and ethically in real-world scenarios. While ML holds vast potential, addressing these challenges is crucial for long-term success.
upGrad’s advanced programs in AI, ML, and deep learning are designed to help learners with both the theory and practical skills needed to overcome these challenges and growing in the tech landscape.
Here are some top course options to help you take the next step in mastering the future of technology:
- Generative AI Mastery Certificate for Managerial Excellence: Learn to use Claude, M365 Copilot, & more.
- Generative AI Mastery Certificate for Content Creation: Learn to use ChatGPT, DALL·E, &
- Generative AI Mastery Certificate for Data Analysis: Learn to use ChatGPT, Power BI, & more.
Curious which courses can help you gain expertise in ML? Contact upGrad for personalized counseling and valuable insights, or visit your nearest upGrad offline center for more details.
FAQs
1. How can the drawback of machine learning approaches affect autonomous vehicles?
Autonomous vehicles rely on ML to make split-second decisions, such as navigating roadways and interpreting obstacles. However, if the model encounters data that differs from its training, such as in unusual weather conditions like heavy rain or fog, it might fail to make accurate predictions. This highlights a major disadvantage of machine learning because the model is not able to generalize effectively to new, unseen environments, leading to potential safety risks.
2. What is a major limitation of machine learning when applied in healthcare?
In healthcare, ML models are often trained on specific datasets, which may be limited in size or biased. For example, a model trained on data from one demographic may not perform well in diverse patient populations. This is one of the major limitations of machine learning that can result in incorrect diagnoses or treatment recommendations, emphasizing the need for larger, more representative datasets and improved data preprocessing to ensure fairness and accuracy in healthcare applications.
3. Why is machine learning not suitable for all real-time applications?
Real-time applications, such as emergency response systems or stock trading, often require immediate decisions. While ML models can be highly accurate, they are often slow and resource-intensive, especially for complex models. That becomes clear when models require long training times and significant computational resources, making them unsuitable for environments that demand instant decision-making.
4. How does overfitting impact machine learning models in finance?
In finance, models are trained on historical data to predict market trends or assess risks. Overfitting occurs when a model learns not only the underlying patterns but also the noise in the data, which does not generalize well to future data. This drawback of machine learning approaches can result in poor performance in volatile financial markets, where models need to adapt to ever-changing conditions rather than rely on past data that may no longer be relevant.
5. What are the risks of using machine learning in criminal justice?
Machine learning models used in criminal justice can perpetuate existing biases if they are trained on historical data that reflects past societal inequalities. For example, models used for risk assessment or parole decisions may be biased toward certain demographic groups, leading to unfair treatment. This in such high-stakes sectors underscores the importance of ensuring fairness and eliminating bias in model training to avoid discrimination in legal proceedings.
6. Can machine learning models in marketing misinterpret customer behavior?
In marketing, machine learning models are used to analyze customer data and predict behavior. However, if the models are not properly trained or monitored, they may misinterpret customer preferences, leading to ineffective marketing campaigns or misdirected advertising. This is one of the major disadvantages of machine learning, highlighting the need for continuous monitoring and fine-tuning to ensure that models remain aligned with evolving customer behavior and preferences.
7. How does a lack of interpretability affect machine learning in healthcare?
ML models, especially deep learning models, are often criticized for their "black-box" nature, where it is difficult to understand how decisions are made. In healthcare, this lack of interpretability can create significant challenges, as doctors need to trust the model's decisions to make critical treatment choices. It can lead to hesitations in using AI-driven tools, particularly in high-risk areas like diagnosis or patient care, where transparency is crucial.
8. What’s the impact of machine learning on job automation in the manufacturing sector?
ML and automation technologies are hugely contributing to the manufacturing sector by improving efficiency, reducing costs, and increasing productivity. However, one disadvantage is that it can lead to job displacement. As machines take over repetitive tasks, workers who were previously employed in those roles may face unemployment. This shift calls for reskilling initiatives and a focus on creating new opportunities for displaced workers in emerging fields.
9. How does machine learning face challenges in handling unstructured data?
Unstructured data, such as text, images, or audio, poses a significant challenge for ML models. These types of data are often messy and difficult to process in their raw form, requiring substantial preprocessing and cleaning. This limitation complicates model training, as unstructured data must be converted into a usable format before any meaningful analysis can take place, which can be time-consuming and computationally expensive.
10. Can machine learning models in finance be biased?
Yes, ML models in finance can be biased, especially if they are trained on historical data that contains biases related to race, gender, or socio-economic factors. For instance, models used for loan approval or credit scoring may unintentionally discriminate against certain demographic groups. This can maintain systemic inequalities, highlighting the need for more ethical training practices and continuous auditing to identify and correct biases.
11. How does data scarcity impact machine learning in remote areas?
In remote or underserved areas, there may be limited access to high-quality, representative data, which can significantly impact the performance of ML models. Without sufficient data, models struggle to make accurate predictions, and the drawback of machine learning approaches become evident. This can hinder progress in sectors like healthcare, where data availability is critical to train accurate models for diagnosing diseases or recommending treatments.





upGrad Learner Support
Talk to our experts. We are available 7 days a week, 10 AM to 7 PM
Indian Nationals
Foreign Nationals
Disclaimer
The above statistics depend on various factors and individual results may vary. Past performance is no guarantee of future results.
The student assumes full responsibility for all expenses associated with visas, travel, & related costs. upGrad does not .