All courses
Agentic AI
Agentic AI
Artificial Intelligence
Degree / Exec. PG

IIIT Bangalore
Executive Diploma in Machine Learning and AI
OPJ Global University
Master’s Degree in Artificial Intelligence and Data Science
Liverpool John Moores University
Master of Science in Machine Learning & AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIExecutive Certificate

IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
IIIT Bangalore
Executive Programme in Generative AI for Leaders
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceOffline Bootcamps

upGrad
Data Science and AI-MLDoctorate
For All Domains
IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
Swiss School of Business and Management
Global Doctor of Business Administration from SSBM
Edgewood University
Doctorate in Business Administration by Edgewood UniversityGolden Gate University
Doctor of Business Administration From Golden Gate University
Rushford Business School
Doctor of Business Administration from Rushford Business School, SwitzerlandGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)-d9bdeff6165f4eb1ba2adcebde78e961.svg)
University of Waterloo
Chief Technology and AI Officer ProgramLeadership / AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIMachine Learning
Machine Learning
Data Science
Degree / Exec. PG
O.P Jindal Global University
Master’s Degree in Artificial Intelligence and Data ScienceIIIT Bangalore
Executive Diploma in Data Science & AILiverpool John Moores University
Master of Science in Data ScienceExecutive Certificate
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceupGrad | Microsoft
Gen AI Mastery Certificate for Content CreationOffline Bootcamps
upGrad
Data Science and AI-MLupGrad
Data AnalyticsMBA
Masters

Paris School of Business
Master of Science in Business Management and TechnologyO.P.Jindal Global University
MBA (with Career Acceleration Program by upGrad)Edgewood University
MBA from Edgewood UniversityO.P.Jindal Global University
MBA from O.P.Jindal Global UniversityGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)Executive Certificate

IMT, Ghaziabad
Advanced General Management ProgramMarketing
Executive Certificate
Offline Bootcamps
upGrad
Digital MarketingManagement
Degree
O.P Jindal Global University
MSc in International Accounting & Finance (ACCA integrated)Paris School of Business
Master of Science in Business Management and Technology
Golden Gate University
Master of Arts in Industrial-Organizational PsychologyExecutive Certificate

IIM Kozhikode
Human Resource Analytics Course from IIM-KupGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftEducation
Education

Northeastern University
Master of Education (M.Ed.) from Northeastern UniversityEdgewood University
Doctor of Education (Ed.D.)Edgewood University
Master of Education (M.Ed.) from Edgewood UniversityCertifications
Project Management
Certification

Knowledgehut
Leadership And Communications In ProjectsKnowledgehut
Microsoft Project 2007/2010-ae8d039bbd2a41318308f8d26b52ac8f.svg)
Knowledgehut
Financial Management For Project ManagersKnowledgehut
Fundamentals of Earned Value Management (EVM)Knowledgehut
Fundamentals of Portfolio ManagementKnowledgehut
Fundamentals of Program Management-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
Knowledgehut
CAPM® CertificationsKnowledgehut
Microsoft® Project 2016Certifications & Trainings
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)
Knowledgehut
PMP® CertificationKnowledgehut
PMI-RMP® CertificationKnowledgehut
PMP Renewal Learning PathKnowledgehut
Oracle Primavera P6 V18.8Knowledgehut
Microsoft® Project 2013Knowledgehut
PfMP® Certification CourseKnowledgehut
Project Planning and MonitoringPrince2 Certifications

Knowledgehut
PRINCE2® FoundationKnowledgehut
PRINCE2® PractitionerKnowledgehut
PRINCE2 Agile Foundation and PractitionerKnowledgehut
PRINCE2 Agile® Foundation CertificationKnowledgehut
PRINCE2 Agile® Practitioner CertificationManagement Certifications
Knowledgehut
Project Management Masters Certification ProgramKnowledgehut
Change ManagementKnowledgehut
Project Management TechniquesKnowledgehut
Product Management Certification ProgramKnowledgehut
Project Risk Management- Study abroad
- Offline centres
- uGSOT - B.Tech
More



49. Variance in ML
What Is Entropy in Machine Learning? Meaning, Formula, and ML Use Cases
Did You Know? A study by the Association for Computing Machinery applied entropy measures to neurological time-series data, improving pattern recognition in conditions like dementia and epilepsy. The approach boosted recall, F1 score, and accuracy by 13.08%, while reducing model parameters by 3.10 times.
Entropy in machine learning measures the uncertainty or impurity in a dataset. This is a concept that is deeply rooted in information theory. You apply it to decision trees like ID3 and C4.5 to evaluate how well a feature splits the data.
This makes your models more accurate and explainable. Understanding entropy helps you grasp how classification algorithms make decisions.
In this blog, you’ll explore its meaning, the formula used, its role in various machine learning algorithms, and practical examples showing how entropy drives model performance.
Want to master entropy in machine learning and data-driven models? upGrad’s AI & ML courses will help you understand key ML concepts. Enroll today to level up your machine learning skills and boost your career!
What is Entropy in Machine Learning? Concept and Importance
Entropy in machine learning measures the level of uncertainty or impurity in a dataset. You use it to determine how mixed the data is, especially when building decision trees. A lower entropy value indicates that the data is more homogeneous, while a higher value suggests greater diversity. In decision tree algorithms like ID3 and C4.5, entropy helps decide the best feature to split the data, aiming to create pure child nodes with minimal uncertainty.
By minimizing entropy, you enhance the model’s accuracy and predictive power. A high entropy value means the data is highly unpredictable, while a low entropy value indicates it’s more orderly or pure. It’s a core concept from information theory that helps you decide where and how to split your data for optimal learning.
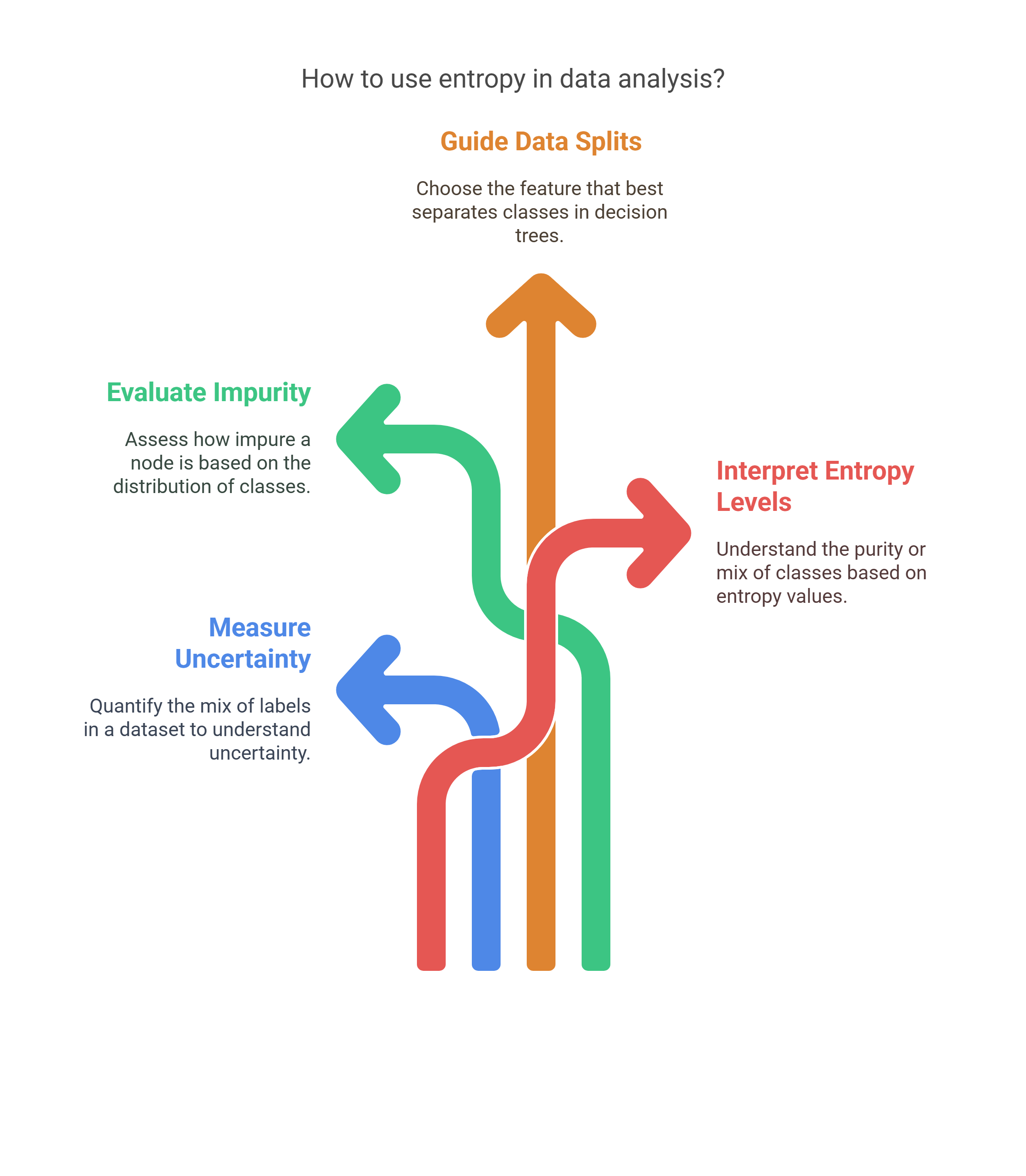
- Entropy measures uncertainty: You quantify how mixed the labels are in a dataset.
- It helps evaluate impurity: If a node in your data has multiple classes, entropy tells you how impure that node is.
- It guides data splits in decision trees: You use entropy to choose the feature that offers the best separation between classes.
- Low entropy pure class distribution: This means most or all data points belong to a single class.
- High entropy mixed classes: This indicates the data is spread across multiple categories, making it less predictable.
In 2025, companies are actively hiring professionals with strong data science and AI skills. Are you ready to boost your career with in-demand machine learning expertise?
Here are three top-rated courses from upGrad to help you start:
- Master’s in Data Science Degree – Gain deep expertise with a globally recognized credential.
- Executive Diploma in Data Science & AI with IIIT-B – Learn from top faculty with hands-on projects and mentorship.
- Executive Post Graduate Program in Data Science & Machine Learning – Build job-ready skills with practical industry exposure.
Now, let's understand the importance of entropy in machine learning.
Importance of Entropy in ML Algorithms
You rely on entropy in machine learning to make smarter decisions during classification tasks. It helps you measure how impure or uncertain a dataset is, which directly affects how models like decision trees split data. Algorithms such as ID3 and C4.5 use entropy to calculate information gain, ensuring that each split improves the model’s predictive power.
- Drives classification decisions: Entropy quantifies uncertainty in class labels, helping the model distinguish between mixed and pure nodes.
- Power's information gain: You calculate how much “useful information” a feature provides when splitting data.
- Used in decision tree algorithms like ID3 and C4.5: These models pick the feature with the highest information gain (lowest entropy) for each split.
- Improves model accuracy: By minimizing entropy at each node, your decision tree becomes more efficient and accurate.
- Helps avoid overfitting: Proper entropy-based splits ensure the model doesn’t memorize noisy data.
Also Read: What is Quantum Machine Learning? A Complete Guide for 2025
Now that you understand what entropy in ML means and why it matters in machine learning, let’s look at how you can calculate it using a simple formula.
The Entropy Formula in Machine Learning
You use the entropy formula in machine learning to quantify uncertainty in a dataset, especially when you're building models like decision trees. This measure comes from Shannon’s Information Theory and helps you decide the most informative way to split your data.
-43f7ebddeefb4667b256ada753be7d38.png)
Shannon Entropy Formula:
H(S)=-i=1kp(i)log2(p(i))
Where:
- H(S) is the entropy of the dataset S
- p(i) is the probability of class III in the dataset
- k is the total number of classes
Breaking It Down with an Example:
Suppose you have 100 samples:
- 60 belong to Class A → p(A)=0.6
- 40 belong to Class B → p(B)=0.4
You calculate entropy as:
H(S)=−(0.6⋅log2(0.6)+0.4⋅log2(0.4)) ≈ 0.971
Now let’s explore the example of entropy calculation.
Entropy Calculation Example
In machine learning, entropy helps measure the disorder or impurity within a dataset. Let’s take the famous Iris dataset as an example, where we have three classes (Setosa, Versicolor, and Virginica) for the flower species. Entropy is used to calculate how mixed these classes are in a given split or node of a decision tree.
To calculate entropy, we first compute the probability of each class in a given subset of data, then apply the formula:
Entropy=−∑(pi×log2(pi))
Where pi is the probability of each class in the dataset. For the Iris dataset, suppose a split has 40% Setosa, 40% Versicolor, and 20% Virginica. You can compute entropy based on these probabilities to measure the impurity.
The Role of Entropy in Complex and Imbalanced Datasets
While entropy is effective for binary and multiclass classification, it is especially important in more complex and imbalanced datasets. If one class is overrepresented, entropy will be lower, indicating less impurity, and this might lead the decision tree to fail in capturing the patterns of minority classes.
In such cases, entropy's role in identifying useful splits becomes crucial. However, in imbalanced datasets, other metrics like Gini impurity may be preferred for faster computation and improved robustness. These alternative metrics can better handle class imbalance by focusing on reducing bias toward the majority class.
You can calculate the Entropy formula in machine learning (Python) using labeled data to see how mixed your classes are. In this example, you'll use the famous Iris dataset to compute entropy based on class distribution.
Step-by-Step Explanation:
- You load the Iris dataset, which has three classes of flowers.
- You extract the target labels (y) representing the flower categories.
- You define a function to:
- Count the number of samples in each class.
- Compute class probabilities
- Apply Shannon's entropy formula.
- You then compute and print the entropy of the entire dataset.
Code Implementation:
from sklearn.datasets import load_iris
import numpy as np
# Load iris dataset
iris = load_iris()
# Extract target labels
y = iris.target
# Define entropy calculation function
def entropy(y):
n = len(y)
_, counts = np.unique(y, return_counts=True)
probs = counts / n
return -np.sum(probs * np.log2(probs))
# Calculate the entropy of the dataset
target_entropy = entropy(y)
print(f"Target entropy: {target_entropy:.3f}")
Output:
Target entropy: 1.585
What This Means:
- The dataset has three equally represented classes, so the entropy is close to the maximum value for three classes:
Max Entropy =-i=13p(i)log2(p(i))=-i=1313log2(13)=-log2(13)=log2(3)1.585
- This high entropy indicates maximum impurity, meaning the classes are evenly mixed.
You can now use this value to compare how pure each node is when building a decision tree. With this covered, let’s learn the difference between entropy and information gain in ML.
Entropy vs. Information Gain in ML
When you're building a decision tree, entropy helps you measure the impurity in your dataset. Information gain tells you how much the impurity is reduced after splitting the data using a particular feature. These two work together to help you choose the best feature at each node.
What Is Information Gain?
Information gain is the difference between the entropy of the original dataset and the weighted entropy after a split. It quantifies how much uncertainty you remove by choosing a specific feature.
How Do You Calculate Information Gain?
You calculate it like this:
Information Gain=Entropy (Parent)−Weighted Entropy (Children)
Where,
- Entropy (Parent) is the entropy of the parent node (before the split).
- Weighted Entropy (Children) is the sum of the entropies of the child nodes (after the split), weighted by the proportion of samples in each child node.
1. First, calculate the entropy of the full dataset.
2. Then, the data will be split using a feature, and the entropy for each resulting group will be calculated.
3. Weight these group entropies by their size and subtract the result from the original entropy.
Why Does Information Gain Matters?
- It helps you decide which feature to split on at each step of building a decision tree.
- You always choose the feature with the highest information gain.
- Algorithms like ID3 and C4.5 depend on this principle to grow accurate trees.
Entropy vs. Information Gain (Comparison Table)
Entropy and Information Gain are key concepts in decision tree algorithms used in machine learning, particularly in classification problems. They help determine the best splits for a dataset by measuring the level of uncertainty (entropy) and the effectiveness of a feature in reducing that uncertainty (information gain). Understanding these concepts is crucial for building efficient models, as they guide the decision-making process when selecting the most relevant features.
Here’s a comparison between the two:
Aspect | Entropy | Information Gain |
What it Measures? | Impurity or randomness in a dataset | Reduction in impurity after a feature split |
Purpose | Evaluate how mixed the classes are | Choose the feature that best separates the data |
Value Range | 0 to log₂(k), where k is the number of classes | 0 to the maximum entropy of the parent node |
Used In | Classification, especially in decision trees | Feature selection in decision tree algorithms |
Step-by-Step Example
Suppose you have 10 samples:
- 6 are labeled Yes
- 4 are labeled No
- Entropy of parent node:
H(S)=-∑kp(i)⋅log2(p(i))
In your case, you have two probabilities: p(1)=0.6 and p(2)=0.4. The entropy for the parent node is calculated as:
H(S)=−(0.6⋅log2(0.6)+0.4⋅log2(0.4))
H(S)=−(0.6⋅(−0.736)+0.4⋅(−1.322))=−(−0.4416+−0.5288)=0.9704
- Split on Feature X:
- Group 1 (4 samples): 3 Yes, 1 No → Entropy ≈ 0.811
- Group 2 (6 samples): 3 Yes, 3 No → Entropy = 1.000
- Weighted Entropy after split:
Hchildren=i=∑k(NNi)⋅H(Si)
Where:
- Ni is the number of elements in the i-th child node.
- N is the total number of elements in the parent node.
- H(Si) is the entropy of the i-th child node.
In your case: There are 4 samples in the first child node, and the entropy of the first child node is 0.811. There are 6 samples in the second child node, and the entropy of the second child node is 1.000.
Hchildren=0.924
- Information Gain:
IG=H(Parent)−Hchildren=0.971−0.924=0.047
Since the information gain is low, you'd check other features to see if any provide better separation.
Also Read: Top 20 IoT Interview Questions & Answers 2025 for All Levels
Now that you’ve seen how the Entropy formula in machine learning is calculated, let’s understand how it works in real-world classification tasks and why it’s essential for building effective models.
How Does Entropy Work in Classification Tasks?
When you're solving a classification problem, entropy helps you understand how mixed the class labels are in a dataset. Whether you're working with a binary or multiclass target, entropy guides the learning algorithm in selecting features that reduce uncertainty.
-043cfaea131348f183d9e666f9b46ee7.png)
Binary and Multiclass Scenarios:
- In a binary classification task, entropy is lowest (0) when all samples belong to one class (pure node), and highest (1) when both classes are equally present (most uncertain).
- In multiclass classification, entropy increases as more classes are added and the distribution becomes more even. Maximum entropy occurs when all classes have equal probability.
Class Distribution Examples
- If 100% of your samples belong to class A, → Entropy = 0
- If 50% belong to class A and 50% to class B, → Entropy = 1
- For three classes (A, B, C) with equal distribution (33.3% each) → Entropy ≈ 1.585
How Entropy Is Used in ML Libraries?
Most machine learning libraries like Scikit-learn use entropy behind the scenes when you build decision trees.
- In sklearn. tree.DecisionTreeClassifier, you can set criterion="entropy" to use entropy-based splits.
- The algorithm calculates entropy at every possible split and selects the one with the highest information gain (i.e., largest reduction in entropy).
- It continues this process recursively, making decisions that progressively simplify the dataset.
Key Takeaways
- Entropy helps you quantify impurity in both binary and multiclass settings.
- You use it to make better feature split decisions during model training.
- Libraries like Scikit-learn automate this process, but understanding entropy helps you interpret how and why your model makes decisions.
If you want to master the dominating field of AI, explore upGrad’s Advanced Generative AI Certification Program. This 5-month course is designed to teach you learn skills in generative AI. You will be able to solve complex business problems with innovative AI solutions.
Also Read: Explore 25 Game-Changing Machine Learning Applications!
Now that you’ve seen how entropy functions in different classification scenarios, it’s important to weigh its strengths and limitations within real-world machine learning applications.
Entropy in Machine Learning: Benefits and Limitations
When you use entropy-based methods in machine learning, especially for classification tasks, you're working with a well-grounded, probabilistic approach that helps improve model decisions. But like any tool, it comes with trade-offs you should be aware of.
-54fbc0e252da4fada5b6988c8566d23c.png)
Benefits of Entropy-Based Methods
Entropy-based methods, particularly in decision tree algorithms like ID3 and C4.5, are valuable tools in machine learning. By quantifying uncertainty or disorder in a dataset, entropy helps identify which features are most useful for making predictions. These methods focus on maximizing information gain to create optimal splits in the data, leading to more accurate and efficient decision trees.
As you explore the benefits of entropy-based methods, let’s look at how they contribute to better model accuracy and feature selection.
- Grounded in probability theory: Entropy is based on Shannon’s information theory, giving your model a mathematically sound way to handle uncertainty in data.
- Feature selection efficiency: Entropy helps you identify the most informative features through information gain, guiding better tree splits.
- Widespread library support: Tools like Scikit-learn and XGBoost offer native support for entropy-based criteria, making implementation seamless.
With this covered, let’s explore the drawbacks and possibilities of entropy not working well in ML.
When Entropy Might Not Work Well in ML
While entropy is a powerful metric for classification tasks, there are scenarios where it may fall short. Understanding its limitations helps you make better choices when selecting metrics or building decision tree models.
Here are a few:
- Sensitive to skewed class distributions: If your dataset is imbalanced, entropy might favor majority classes, leading to biased splits that overlook minority patterns.
- Ineffective with non-informative features: When features provide little or no class separation, entropy may still produce small gains, misleading the model to make weak splits.
- Computationally expensive: Compared to Gini impurity, entropy involves logarithmic calculations, which can slow down training on very large datasets.
Also Read: Bing Chat with AI and GPT-4: All You Need to Know in 2025
While entropy is widely used in decision trees, its applications in machine learning go far beyond classification tasks. Let’s explore where else you’ll encounter it.
Other Contexts Where Entropy in ML Appears
Entropy isn’t limited to decision tree algorithms; you'll find it across various machine learning workflows, from feature selection to deep learning. In many cases, it appears indirectly but still plays a critical role in optimizing performance and understanding data behavior.
Where Do You Use Entropy Beyond Classification?
- Feature selection with filter methods: You can use entropy-based scores (like mutual information) to rank features by how much they reduce uncertainty in the target variable. This helps you choose the most relevant inputs for your model.
- Information-theoretic measures in unsupervised learning: In clustering tasks, entropy helps evaluate the quality of clusters by checking how mixed class distributions are across clusters. Lower entropy within clusters usually indicates better grouping.
- Loss functions in deep learning: When you're training neural networks for classification, you often use cross-entropy loss, which is built on the concept of entropy. It measures the difference between the predicted probability distribution and the true distribution.
- Bayesian inference and model uncertainty: Entropy is used to quantify uncertainty in predictions, especially in probabilistic models or when estimating posterior distributions.
- Entropy in reinforcement learning: You apply entropy to encourage exploration by penalizing overly confident policy predictions. This keeps the model from settling into suboptimal actions too early.
Unlock your AI potential with our Free Certificate Courses! Start your journey with Intro to Natural Language Processing and explore the basics of NLP, covering key topics all in just 7 hours. Or, take it a step further with Fundamentals of Deep Learning of Neural Networks and harness the power of ChatGPT to automate tasks and boost productivity. Enroll for free today!
From decision trees to deep learning and feature selection, entropy quietly powers some of the most critical steps in machine learning workflows. Now, let’s wrap up with a quick summary of why understanding entropy truly matters.
Master Machine Learning with Expert Guidance on upGrad!
Entropy in ML has many benefits. Whether you're training decision trees or working with probability-based models, understanding entropy gives you a clear edge in building smarter systems.
Yet many professionals struggle to apply entropy effectively in their models, especially when dealing with complex, unstructured data or industries that require rapid, accurate predictions like healthcare and e-commerce. The ability to choose the right features and reduce uncertainty can be a game-changer in building models that generalize well.
upGrad solves this by offering advanced programs that provide hands-on learning, real-world projects, and 1:1 mentorship. Join 10M+ learners across 200+ programs, with backing from 1,400+ hiring partners including Microsoft, Flipkart, and Google Cloud, and take the next step in mastering machine learning concepts like entropy.
Explore These Additional upGrad Courses to Boost Your ML Skills:
- Executive Diploma in Data Science & AI – Offered by IIIT-Bangalore Get placement support and dive into practical AI, ML, and analytics workflows.
- Executive PG Program in Data Science – 12-month industry-ready curriculum Learn applied machine learning, statistics, and business applications.
- MS in Data Science – From Liverpool John Moores University Earn dual credentials with international exposure in just 17 months.
- Executive PG Programme in Business Analytics – In partnership with Loyola Institute. Designed for working professionals looking to make data-driven business decisions.
Ready to take the next step in your AI and Data Science journey? Connect with an upGrad counselor today or visit one of our offline centers to discover the perfect program tailored to your career goals and aspirations.
FAQs
1. How do decision trees use entropy to select features effectively in real-world tasks?
In a customer churn prediction model, decision trees use entropy to identify features that best separate churners from non-churners. For example, if "last login date" drastically reduces entropy, it's considered highly informative. This allows the tree to prioritize features that reduce uncertainty, improving predictive performance. By continuously selecting such attributes, the model becomes both interpretable and highly tailored to the dataset.
2. When should I prefer entropy over Gini impurity in real-time systems?
Entropy is ideal when you need more fine-grained control in feature selection, like in fraud detection models where every bit of uncertainty matters. However, it's computationally heavier than Gini, so it might slow down training in real-time systems. If accuracy gains are marginal, Gini is a better choice for fast execution. Use entropy when you can afford the cost for slightly better splits.
3. How can entropy help with feature selection in high-dimensional datasets?
In high-dimensional tasks like text classification, entropy helps select the most informative words by measuring their uncertainty-reducing power. Techniques like mutual information scoring rank features based on how much they clarify the target label. This helps reduce dimensionality without significant loss in performance. It's especially useful in filtering out irrelevant or noisy features from sparse datasets.
4. Can I use entropy in unsupervised tasks like clustering evaluation?
Yes, entropy can assess cluster purity in unsupervised learning, such as evaluating customer segments in marketing. After clustering, entropy quantifies how mixed or homogeneous each cluster is in relation to a known label. Low entropy indicates high consistency within clusters, which is desirable. This helps validate clustering quality and guides further tuning of algorithms like K-means or DBSCAN.
5. Can I use entropy in unsupervised tasks like clustering evaluation?
Yes, entropy can assess cluster purity in unsupervised learning, such as evaluating customer segments in marketing. After clustering, entropy quantifies how mixed or homogeneous each cluster is in relation to a known label. Low entropy indicates high consistency within clusters, which is desirable. This helps validate clustering quality and guides further tuning of algorithms like K-means or DBSCAN.
6. How does cross-entropy loss help in training neural networks for image classification?
In image classifiers like CNNs, cross-entropy measures how well predicted probabilities align with the correct class labels. It penalizes confident but wrong predictions more heavily, guiding the network to learn better weight adjustments. This is essential when distinguishing between visually similar classes, like cats and dogs. The loss drives the model to maximize probability for the correct label during each training iteration.
7. How do I use entropy in Python to compare model splits manually?
When building a custom decision tree or evaluating model splits, calculate entropy by tallying class distributions and applying the formula -sum(p * log2(p)) using NumPy. For example, use it to compare how well “region” or “purchase amount” splits the data in a sales prediction model. Scikit-learn’s DecisionTreeClassifier also supports entropy via the criterion='entropy' parameter. This makes it easy to experiment with different split criteria.
8. How is entropy applied in NLP for feature scoring and selection?
In text classification, entropy helps identify high-value features like keywords that strongly predict sentiment or intent. For example, mutual information uses entropy to score which words reduce label uncertainty, helping prune irrelevant tokens. This improves model accuracy while reducing computation. It's commonly used in preprocessing steps before training models like Naive Bayes or SVMs.
9. How does entropy guide decision-making in A/B testing platforms?
Entropy can evaluate uncertainty in user behavior between two groups in A/B testing, such as click-through rates or conversions. A lower entropy in Group B may suggest more consistent behavior, making it a better candidate. This helps product teams interpret not just averages, but confidence in performance. It adds another dimension to statistical significance by capturing data variability.
10. What are real-world signs that entropy might not be the best fit for your model?
If your dataset is extremely large, noisy, or requires real-time decisions—like in ad targeting—entropy may slow training without significant accuracy gains. You may also find that Gini or heuristic-based methods perform similarly with less computation. Models struggling with imbalance may misinterpret entropy-based splits. In such cases, switching to simpler criteria or pre-processing class weights helps balance performance and efficiency.
11. How is entropy used to improve decision-making in medical diagnosis models?
In medical diagnosis tasks, entropy helps select features that best distinguish between conditions—like “chest pain type” for predicting heart disease. Reducing entropy in splits ensures the model focuses on the most diagnostically relevant factors. This results in clearer, more interpretable rules that physicians can trust and validate. Entropy-based models like decision trees are often used in clinical decision support systems for this reason.





upGrad Learner Support
Talk to our experts. We are available 7 days a week, 10 AM to 7 PM
Indian Nationals
Foreign Nationals
Disclaimer
The above statistics depend on various factors and individual results may vary. Past performance is no guarantee of future results.
The student assumes full responsibility for all expenses associated with visas, travel, & related costs. upGrad does not .