









![Active Learning For Artificial Intelligence [Comprehensive Guide]](/__khugblog-next/image/?url=https%3A%2F%2Fd14b9ctw0m6fid.cloudfront.net%2Fugblog%2Fwp-content%2Fuploads%2F2019%2F07%2FBlog_FI_July_upGrads-Knowledge-base.png&w=1920&q=75)
Overview of active learning for artificial intelligence
In this article, we will cover the basics of active learning and its relevance in the world of Artificial Intelligence.
Introduction
In machine learning, there exist two types of learning methods — supervised and unsupervised learning. In supervised learning, we provide the model with labels for each training sample. The model learns the features of the training data samples and maps them to their corresponding labels.
Best Machine Learning and AI Courses Online

The output is a probability of a test sample belonging to a particular class. Unsupervised learning, however, requires no labels and the model classifies the test sample based on some pattern or trend it has learned during the training process.
Now in supervised learning, there is a need for images(assume as input) and its annotations. The model can learn from the images by optimizing well enough to fit the images and their annotation.
But, practically for the model to perform extremely well on test samples, a plethora of images and its annotations are required. To solve this problem, active learning was employed by many researchers.
Motivation
In many cases, there will usually be millions of data available, but annotating all of them would be infeasible and time-consuming. Few examples include:
- A video recorded by a drone during its flight
- A medical image containing millions of cells
- A CCTV recording from a traffic light signal
To deal with such heavy data, active learning is employed that tells us out of all the available data for annotation, annotating which samples make sense.
In-demand Machine Learning Skills
Join the Artificial Intelligence Course online from the World’s top Universities – Masters, Executive Post Graduate Programs, and Advanced Certificate Program in ML & AI to fast-track your career.
Basic Process
The ML engineer/Oracle specialist has access to a large pool of unlabeled data. Say, the task is to build a cat and dog classifier. Now out of this entire pool of data, the engineer chooses to train the model on only 20% of the data(labels them first) and uses the rest 80% for the testing purpose.
This is a round-based method. In every iteration, a test image is given to the model for classification. If the model performs poorly, or if the probability assigned by the model is less, say 0.6, then the model needs to be trained on this sample to improve the overall performance. The image for which the model is uncertain or not confident contains more information for the model to learn.
This sample is then labeled and selected as a training sample. This iteration is repeated until the last test sample. In this way, we assemble a new training set that is worth annotating. The model is trained on the newly collected selective training data thereby reducing overall training time. This is repeated until the annotation set is over.
How to select the image for annotation?
The above-mentioned approach is just one simple way of choosing a sample for annotation. In real practice, the following two methods are used, sometimes a combination of the two.
- Sampling based on uncertainty: Images that the model is uncertain about or, images that have been assigned low probability by the model.
- Sampling based on diversity: Images that represent the diversity, that is, variation in spatial representation, spectral representation, class representation, and so on. More the diversity, more available information for the model to learn.
A function that takes a data sample(image) as input and returns a priority/ranking score is termed as an Acquisition function.
Read: Challenges in AI
Common Acquisition Functions
1. Best-versus-Second-Best (BvSB)
This method is mostly used for a few classes(3 to 5). The formula used considers the probability values of the highest and the second-highest class. y1 and y2 indicate the highest and the second-highest probability values predicted by the model p? for a given sample x.
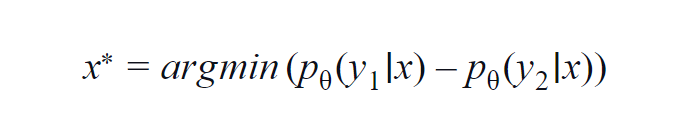
The fundamental idea is to minimize the below equation. The lower the difference, the more is the information contained in the data sample x.
For simple understanding, suppose an example where the classes involved in the data sample are dog, cat, horse, and lion. Consider the first scenario where the input to the model is a dog image and the output probability of dog class(most probable) is 0.6 and of cat class(2nd most probable) is 0.35.
The Remaining 0.5 is distributed between the other two classes. In the second scenario, for the same input, the output probabilities for the top-two classes are 0.7 and 0.2. Now from the two scenarios, we can infer that in the second scenario, the model is more certain about its prediction (0.7–0.2=0.5).
In the first scenario, the model is more uncertain regarding the prediction (0.6–0.35=0.25). Thereby minimizing the above equation, we can collect a data sample worth annotating.
2. Entropy
BvSB is suitable for fewer classes. However, with a large number of classes, entropy is used as an acquisition function. The reason being, the below formula considers the information in the remaining classes. Entropy is a measure of impurity or imbalance. In terms of machine learning, it can be defined as a measure of uncertainty of a model. A high value of entropy is an indication of high uncertainty in the class association.
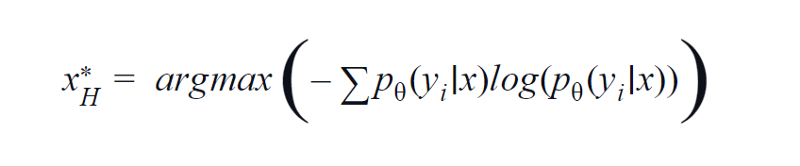
Entropy equation, Image by Author
Therefore, maximizing the above equation will yield us an image sample for which the model is highly uncertain or least confident in the classification task.
Also Read: Future Scope of AI
3. Query by committee QBC
Just like random forest makes use of ensemble learning — making use of several decision trees. Similarly, uncertainty about a data sample x is measured over an ensemble of different models(having different hyperparameters or seeds).
With this, if for a given image, the output varies a lot for different models, it means that the models are not comfortable in classifying this image. Usually, the most probable score from each model is stacked in a vector. The entropy of this vector is calculated. Again, if the entropy is high, the image is further labelled and annotated.
One Step Ahead
Until now, we have used data samples for which the model isn’t sure enough. But what about the samples for which the model is extremely sure or assigns a high probability score? Now, if we can use such samples, then the model improves its learning about the features it has already learned.
In this way, it improves its performance by polishing its learning. All in all, the engineer can take data samples that have a probability score of 0.9 and above and can assign a label to it. This can be further annotated and fed as a training sample.
The motive of such a method is to improve the model’s existing learning about the features. In this way, the ML model and the ML engineer cooperate with each other to effectively come up with data samples that are to be annotated. Such a technique is termed cooperative learning.
Popular AI and ML Blogs & Free Courses
Conclusion
It has been found that using active learning techniques, practitioners save around 80% of their time that was otherwise spent in annotation and labeling. The advantage of active learning is not only limited to decreased training time of model and efficient data annotation.
It also reduces overfitting that occurs due to the presence of a large number of samples of a single type making the model biased.
If you’re interested to learn more about machine learning, check out IIIT-B & upGrad’s PG Diploma in Machine Learning & AI which is designed for working professionals and offers 450+ hours of rigorous training, 30+ case studies & assignments, IIIT-B Alumni status, 5+ practical hands-on capstone projects & job assistance with top firms.



















![Artificial Intelligence Salary in India [For Beginners & Experienced] in 2024](/__khugblog-next/image/?url=https%3A%2F%2Fd14b9ctw0m6fid.cloudfront.net%2Fugblog%2Fwp-content%2Fuploads%2F2019%2F11%2F06-banner.png&w=3840&q=75)
![24 Exciting IoT Project Ideas & Topics For Beginners 2024 [Latest]](/__khugblog-next/image/?url=https%3A%2F%2Fd14b9ctw0m6fid.cloudfront.net%2Fugblog%2Fwp-content%2Fuploads%2F2020%2F04%2F280.png&w=3840&q=75)
![Natural Language Processing (NLP) Projects & Topics For Beginners [2023]](/__khugblog-next/image/?url=https%3A%2F%2Fd14b9ctw0m6fid.cloudfront.net%2Fugblog%2Fwp-content%2Fuploads%2F2020%2F05%2F513.png&w=3840&q=75)
![45+ Interesting Machine Learning Project Ideas For Beginners [2024]](/__khugblog-next/image/?url=https%3A%2F%2Fd14b9ctw0m6fid.cloudfront.net%2Fugblog%2Fwp-content%2Fuploads%2F2019%2F07%2FBlog_FI_Machine_Learning_Project_Ideas.png&w=3840&q=75)

