










Regular expressions also referred to as regex, are a vital element of Python and other programming languages. We use these expressions to search or replace specific patterns of text. A search pattern in the regular expressions is formed by a set of characters. This text pattern is called the regex pattern. Memorizing the syntax and forming patterns as per the requirements are the skills to be mastered to use regex in Python. The subsequent sections of this page discuss more about regex cheat sheets in Python.
Basic Characters:
| Expression | Description |
| ^ | The expression is matched at the string’s start towards its right before a line break is experienced. |
| $ | The expression is matched to its left at the string’s end before a line break is experienced. |
| . | Any character is matched except a newline. |
| a | Only one character ‘a’ is matched. |
| xy | The ‘xy’ string is matched |
| a|b | Either expression a or b is matched. If one expression is matched first, the other one is left untried. |
The code below gives an idea of using basic characters in the regex cheat sheet.

The output of the above code is as follows.

Check Out upGrad’s Data Science Courses
What is Regex Cheat Sheet Quantifiers?
| Expression | Description |
| + | The expression is matched to its left 1 or more times. |
| * | The expression is matched to its left 0 or more times. |
| ? | The expression is matched 0 or 1 times to its left. |
| {p} | The expression is matched p times and not less than, to its left |
| {p,q} | An expression is matched p and q times to its left, and not less than |
| {p, } | An expression is matched p or more times to its left. |
| { , q} | An expression is matched up to q times to its left. |
These searching methods are Greedy by Default. However, a non-greedy search can be performed by adding ? to the quantifiers. Look at the code below to understand the usage of quantifiers in the Regex cheat sheet of Python.

The output of the above code is as follows:

Character class in Python’s Regex cheat sheet:
| Expression | Description |
| \w | It is used to match alphanumeric characters and underscore. The alphanumeric character includes all characters of uppercase and lowercase alphabet letters and digits 0 to 9. |
| \W | It is used to match all the characters that are not alphanumeric and underscore. |
| \d | It is used to match digits from 0 to 9. |
| \D | It is used to match the characters that are not digits. i.e., the characters other than 0 to 9. |
| \s | It is used to match the whitespace characters, including \t, \n, \r and the space characters. |
| \S | It is used to match the characters that are not whitespaces. |
| \A | Matches the expression at the absolute string’s start to its right either in single or multiline mode. |
| \Z | Matches the expression at the absolute string end to its left in a single or multiline mode. |
| \n | It is used to match a newline character. |
| \t | It is used to match a tab character. |
| \b | It is used to match the word boundary at the end and start of a word. The word boundary refers to an empty string in most cases. |
| \B | It matches where the \b does not, i.e., non-word boundary. |
Look at the example below to understand the use of character class expressions in Python code.

The output of the above code is mentioned below.

Expressions related to Sets in Regex cheat sheet:
| Expression | Description |
| [abc] | It matches either of the characters among a, b and c but will not match abc as a whole. |
| [a-z] | It matches any alphabet letter from a to z. |
| [A-Z] | It matches any of the alphabet letters from A to Z. |
| [a\-p] | It matches either a or – p or p. – is matched because \ escapes it. |
| [-z] | It is used to match either – or z. |
| [a-z0-9] | It is used to match the alphabet letters from a to z or digits from 0 to 9. |
| [(+*)] | Special characters are literals within a set. So, this character matches (, *, + or ). |
| [^ab5] | Any character of the set can be excluded by adding ^. In this expression, any characters that are not ‘a’ or ‘b’ or ‘5’ are matched. |
| \[a\] | It matches [a] as both the parentheses escape. |
The code below reflects the use of the regular expressions related to sets.

The output of the above code is as follows:

Regular expressions concerned to groups:
| Expression | Description |
| ( ) | It is used to match the expression within the parenthesis and group it such that we can capture it as per the requirement. |
| (?#…) | It is used to read a comment. |
| (?PAB) | It is used to match the expression AB that can be retrieved with the name of the group. |
| (?:A) | It is used to match the expression as denoted by A. However, it cannot be retrieved later. |
| (?P=group) | It is used to match the expression that is already matched by a former group named ‘group’. |
The Python code below shows an example of how the group expressions can be used while scripting the code.

The output of the above code is as follows.
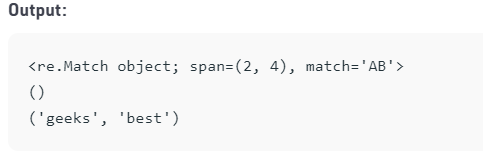
Use of Regular expressions related to Assertions:
| Expression | Description |
| A(?=B) | An expression A is matched only if it is trailed by the expression B. This is referred to as the positive look ahead assertion. |
| A(?!B) | An expression A is matched only if it is not trailed by the expression B. This is referred to as the negative look ahead assertion. |
| (?<=B)A | The expression A is matched only if the expression B is to its immediate left. It is referred to as the positive look behind assertion. |
| (?<!B)A | The expression A is matched only if the expression B is not to its immediate left. It is referred to as the negative look behind assertion. |
| (?()|) | It is used to match the If else conditional expression. |
The code below shows the implementation of expressions related to assertions in Python programs.

The output of the above code is as follows.

Regex Cheat Sheet – Flags
| Expression | Description |
| A | It matches only ASCII. |
| i | It is used to ignore a case |
| L | It refers to the classes of the Locale characters. |
| M | ^ matches the start and $ matches the end of the line in a multiline scenario. |
| S | Everything is matched, including the new line. |
| U | It matches classes of Unicode characters. |
| X | It permits comments and spaces (Verbose). |

The output of the above code is as follows.

If you are curious to learn about tableau, data science, check out IIIT-B & upGrad’s Executive PG Programme in Data Science which is created for working professionals and offers 10+ case studies & projects, practical hands-on workshops, mentorship with industry experts, 1-on-1 with industry mentors, 400+ hours of learning and job assistance with top firms.
Also, Check out all trending Python tutorial concepts in 2024.




































![Top 13 Highest Paying Data Science Jobs in India [A Complete Report]](/__khugblog-next/image/?url=https%3A%2F%2Fd14b9ctw0m6fid.cloudfront.net%2Fugblog%2Fwp-content%2Fuploads%2F2020%2F08%2F904-scaled.jpg&w=3840&q=75)
![Most Common PySpark Interview Questions & Answers [For Freshers & Experienced]](/__khugblog-next/image/?url=https%3A%2F%2Fd14b9ctw0m6fid.cloudfront.net%2Fugblog%2Fwp-content%2Fuploads%2F2020%2F09%2F991.png&w=3840&q=75)



![Inheritance in Python | Python Inheritance [With Example]](/__khugblog-next/image/?url=https%3A%2F%2Fd14b9ctw0m6fid.cloudfront.net%2Fugblog%2Fwp-content%2Fuploads%2F2020%2F12%2F1434.png&w=3840&q=75)


![Sorting in Data Structure: Categories & Types [With Examples]](/__khugblog-next/image/?url=https%3A%2F%2Fd14b9ctw0m6fid.cloudfront.net%2Fugblog%2Fwp-content%2Fuploads%2F2020%2F05%2F493-Sorting-in-Data-Structure.png&w=3840&q=75)

