










This article aims to explore the connection between the game ‘Go’ and artificial intelligence. The objective is to answer the questions – What makes the game of Go, special? Why was mastering the game of Go difficult for a computer? Why was a computer program able to beat a chess grandmaster in 1997? Why did it take close to two decades to crack Go?
Best Machine Learning and AI Courses Online
“Gentlemen should not waste their time on trivial games – they should study Go”
– Confucius
In fact, artificial intelligence pundits thought computers would only be able to beat a world Go champion by 2027. Thanks to DeepMind, an artificial intelligence company under the umbrella of Google, this formidable task was achieved a decade earlier. This article will talk about the technologies used by DeepMind to beat the world Go champion. Finally, this post discusses how this technology can be used to resolve some complex, real-world problems.

Go – What is it?
Go is a 3000-year-old Chinese strategy board game, which has retained its popularity through the ages. Played by tens of millions of people worldwide, Go is a two-player board game with simple rules and intuitive strategy. Different board sizes are in use for playing this game; professionals use a 19×19 board.

The game starts with an empty board. Each player then takes turns to place the black and white stones (black goes first) on the board, at the intersection of the lines (unlike chess, where you place pieces in the squares). A player can capture the stones of the opponent by surrounding it from all sides. For each captured stone, some points are awarded to the player. The objective of the game is to occupy maximum territory on the board along with capturing your opponents’ stones.
In-demand Machine Learning Skills
Go is about creation, unlike Chess, which is about destruction. Go requires freedom, creativity, intuition, balance, strategy and intellectual depth to master the game. Playing Go involves both sides of the brain. In fact, the brain scans of Go players have revealed that Go helps in brain development by improving connections between both the brain hemispheres.
Go and the Challenge to Artificial Intelligence (AI)
Computers were able to master Tic-Tac-Toe in 1952. Deep Blue was able to beat Chess grandmaster Garry Kasparov in 1997. The computer program was able to win against the world champion in Jeopardy (a popular American game) in 2001. DeepMind’s AlphaGo was able to defeat a world Go champion in 2016. Why is it considered challenging for a computer program to master the game of Go?
Chess is played on an 8×8 board whereas Go uses a 19×19 size board. In the opening of a chess game, a player will have 20 possible moves. In a Go opening, a player can have 361 possible moves.The number of possible Go board positions is equal to 10 to the power 170; more than the number of atoms in our universe! The potential number of board positions makes Go googol times (10 to the power 100) more complex than chess.
In chess, for each step, a player is faced with a choice of 35 moves. On average, a Go player will have 250 possible moves at each step. In Chess, at any given position, it is relatively easy for a computer to do brute force search and choose the best possible move which maximises the chances of winning. A brute force search is not possible in the case of Go, as the potential number of legal moves allowed for each step is humongous.
For a computer to master chess, it becomes easier as the game progresses because the pieces are removed from the board. In Go, it becomes more difficult for the computer program as stones are added to the board as the game progresses. Typically, a Go game will last 3 times longer than a game of chess.
Due to all these reasons, a top computer Go program was only able to catch up with the Go world champion in 2016, after a huge explosion of new machine learning techniques. Scientists working at DeepMind were able to come up with a computer program called AlphaGo which defeated world champion Lee Seedol. Achieving the task was not easy. The researchers at DeepMind came up with many novel innovations in the process of creating AlphaGo.
“The rules of Go are so elegant, organic, and rigorously logical that if intelligent life forms exist elsewhere in the universe, they almost certainly play Go.”
– Edward Laskar
How AlphaGo Works
AlphaGo is a general purpose algorithm, which means it can be put to use for solving other tasks as well. For example, Deep Blue from IBM is specifically designed for playing chess. Rules of chess together with the accumulated knowledge from centuries of playing the game are programmed into the brain of the program. Deep Blue can’t be used even for playing trivial games like Tic-Tac-Toe. It can do only one specific thing, which it is very good at, i.e. playing chess. AlphaGo can learn to play other games as well apart from Go. These general purpose algorithms constitute a novel field of research, called Artificial General Intelligence.
AlphaGo uses state-of-the-art methods – Deep Neural Networks (DNN), Reinforcement Learning (RL), Monte Carlo Tree Search (MCTS), Deep Q Networks (DQN) (a novel technique introduced and popularised by DeepMind which combines neural networks with reinforcement learning), to name a few. It then combines all these methods innovatively to achieve superhuman level mastery in the game of Go.
Let’s first look at each individual piece of this puzzle before going into how these pieces are tied together to achieve the task at hand.
Deep Neural Networks
DNNs are a technique to perform machine learning, loosely inspired by the functioning of the human brain. A DNN’s architecture consists of layers of neurons. DNN can recognise patterns in data without being explicitly programmed for it.
It maps the inputs to outputs without anyone specifically programming it for the same. As an example, let us assume that we have fed the network with a lot of cat and dog photos. At the same time, we are also training the system by telling it (in the form of labels) if a particular image is of a cat or a dog (this is called supervised learning). A DNN will learn to recognise the pattern from the photos to successfully differentiate between a cat and a dog. The main objective of the training is that when a DNN sees a new picture of either a dog or a cat, it should be able to correctly classify it, i.e. predict if it is a cat or a dog.
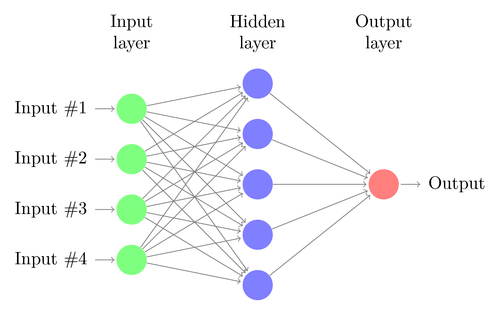
Let us understand the architecture of a simple DNN. The number of neurons in the input layer corresponds to the size of the input. Let us assume our cat and dog photos are a 28×28 image. Each row and column will consist of 28 pixels each, which makes it a total of 784 pixels for each picture. In such a case the input layer will comprise of 784 neurons, one for each pixel. The number of neurons in the output layer will depend on the number of classes into which the output needs to be classified. In this case, the output layer will consist of two neurons – one corresponding to ‘cat’, the other to ‘dog’.
There will be many neuron layers in between the input and output layers (which is the origin of using the term ‘Deep’ in ‘Deep Neural Network’). These are called “hidden layers”. The number of hidden layers and the number of neurons in each layer is not fixed. In fact, changing these values is exactly what leads to optimisation of performance. These values are called hyper-parameters, and they need to be tuned according to the problem at hand. The experiments surrounding neural networks largely involve finding out the optimal number of hyperparameters.
The training phase of DNNs will consist of a forward pass and a backward pass. First, all the connections between the neurons are initialised with random weights. During the forward pass, the network is fed with a single image. The inputs (pixel data from the image) are combined with the parameters of the network (weights, biases and activation functions) and feed-forwarded through hidden layers, all the way to the output, which returns a probability of a photo belonging to each of the classes.
Then, this probability is compared with the actual class label, and an “error” is calculated. At this point, the backward pass is performed – this error information is passed back through the network through a technique called “back-propagation”. During initial phases of training, this error will be high, and a good training mechanism will gradually reduce this error.
The DNNs are trained in this way with a forward and backward pass until the weights stop changing (this is known as convergence). Then the DNNs will be able to predict and classify the images with a high degree of accuracy, i.e. whether the picture has a cat or a dog.
Research has given us many different Deep Neural Network Architectures. For Computer Vision problems (i.e. problems involving images), Convolution Neural Networks (CNNs) have traditionally given good results. For issues which involve a sequence – speech recognition or language translation – Recurrent Neural Networks (RNN) provide excellent results.
In the case of AlphaGo, the process was as follows: first, the Convolution Neural Network (CNN) was trained on millions of images of board positions. Next, the network was informed about the subsequent move played by the human experts in each case during the training phase of the network. In the same manner as earlier mentioned, the actual value was compared with the output and some sort of “error” metric was found.
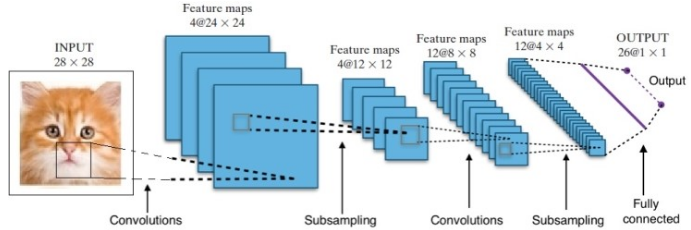
At the end of the training, the DNN will output the next moves along with probabilities which are likely to be played by an expert human player. This kind of network can only come up with a step which is played by a human expert player. DeepMind was able to achieve an accuracy of 60% in predicting the move that the human would make. However, to beat a human expert at Go, this is not sufficient. The output from the DNN is further processed by Deep Reinforcement Network, an approach conceived by DeepMind, which combines deep neural networks and reinforcement learning.
Deep Reinforcement Learning
Reinforcement learning (RL) is not a new concept. Nobel prize laureate Ivan Pavlov experimented on classical conditioning on dogs and discovered the principles of reinforcement learning in 1902. RL is also one of the methods with which humans learn new skills. Ever wondered how the Dolphins in shows are trained to jump to such great heights out of the water? It is with the help of RL. First, the rope which is used for preparing the dolphins is submerged in the pool. Whenever the dolphin crosses the cable from the top, it is rewarded with food. When it does not cross the rope the reward is withdrawn. Slowly the dolphin will learn that it is paid whenever it passes the cord from above. The height of the rope is increased gradually to train the dolphin.
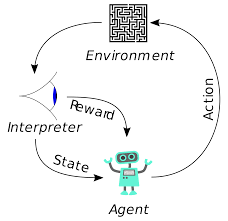
Agents in reinforcement learning are also trained using the same principle. The agent will take action and interact with the environment. The action taken by the agent causes the environment to change. Further, the agent received feedback about the environment. The agent is either rewarded or not, depending on its action and the objective at hand. The important point is, this objective at hand is not explicitly stated for the agent. Given sufficient time, the agent will learn how to maximise future rewards.
Combining this with DNNs, DeepMind invented Deep Reinforcement Learning (DRL) or Deep Q Networks (DQN) where Q stands for maximum future rewards obtained. DQNs were first applied to Atari games. DQN learnt how to play different types of Atari games just out of the box. The breakthrough was that no explicit programming was required for representing different kinds of Atari games. A single program was smart enough to learn about all the different environments of the game, and through self-play, was able to master many of them.
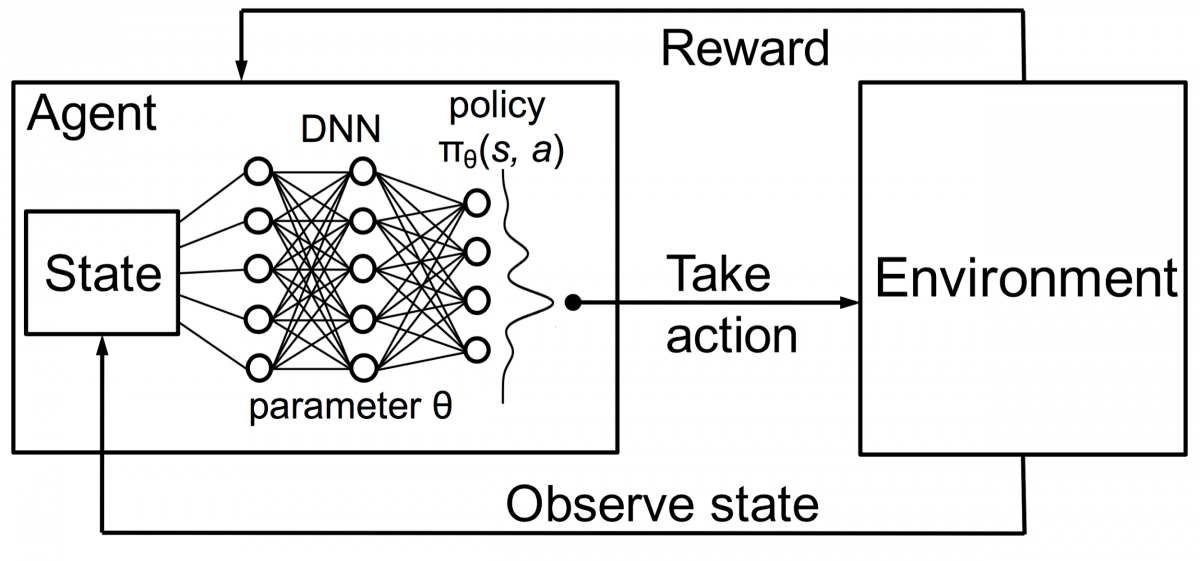
In 2014, DQN outperformed previous machine learning methods in 43 of the 49 games (now it has been tested on more than 70 games). In fact, in more than half the games, it performed at more than 75% of the level of a professional human player. In certain games, DQN even came up with surprisingly far-sighted strategies that allowed it to achieve the maximum attainable score—for example, in Breakout, it learned to first dig a tunnel at one end of the brick wall, so the ball would bounce around the back and knock out bricks from behind.
Policy and Value Networks
There are two main types of networks inside AlphaGo:
One of the objectives of AlphaGo’s DQNs is to go beyond the human expert play and mimic new innovative moves, by playing against itself millions of times and thereby incrementally improving the weights. This DQN had an 80% win rate against common DNNs. DeepMind decided to combine these two neural networks (DNN and DQN) to form the first type of network – a ‘Policy Network’. Briefly, the job of a policy network is to reduce the breadth of the search for the next move and to come up with a few good moves which are worth further exploration.
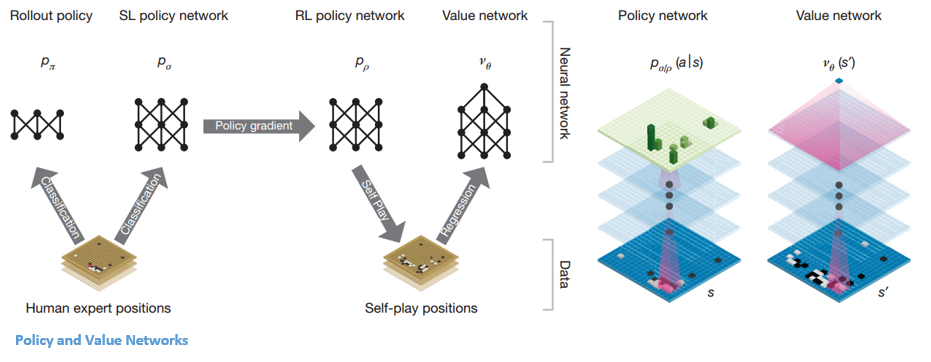 Once the policy network is frozen, it plays against itself millions of times. These games generate a new Go dataset, consisting of the various board positions and the outcomes of the games. This dataset is used to create an evaluation function. The second type of function – the ‘Value Network’ is used to predict the outcome of the game. It learns to take various board positions as inputs and predict the outcome of the game and the measure of it.
Once the policy network is frozen, it plays against itself millions of times. These games generate a new Go dataset, consisting of the various board positions and the outcomes of the games. This dataset is used to create an evaluation function. The second type of function – the ‘Value Network’ is used to predict the outcome of the game. It learns to take various board positions as inputs and predict the outcome of the game and the measure of it.
Combining the Policy and Value Networks
After all this training, DeepMind finally ended up with two neural networks – Policy and Value Networks. The policy network takes the board position as an input and outputs the probability distribution as the likelihood of each of the moves in that position. The value network again takes the position of the board as input and outputs a single real number between 0 and 1. If the output of the network is zero, it means that white is completely winning and 1 indicates a complete win for the player with black stones.
The Policy network evaluates current positions, and the value network evaluates future moves. The division of tasks into these two networks by DeepMind was one of the major reasons behind the success of AlphaGo.
Combining Policy and Value networks with Monte Carlo Tree Search (MCTS) and Rollouts
The neural networks on their own will not be enough. To win the game of Go, some more strategising is required. This plan is achieved with the help of MCTS. Monte Carlo Tree Search also helps in stitching the two neural networks together in an innovative way. Neural networks assist in an efficient search for the next best move.
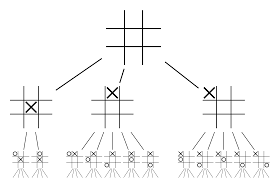
Let’s try constructing an example which will help you visualise all of this much better. Imagine that the game is in a new position, one which has not been encountered before. In such a situation, a policy network is called upon to evaluate the current situation and possible future paths; as well as the desirability of the paths and the value of each move by the Value networks, supported by Monte Carlo rollouts.
Policy network finds all the possible “good” moves and value networks evaluate each of their outcomes. In Monte Carlo rollouts, a few thousand random games are played from the positions recognised by the policy network. Experiments were done to determine the relative importance of value networks against Monte Carlo rollouts. As a result of this experimentation, DeepMind assigned 80% weightage to the Value networks and 20% weightage to the Monte Carlo rollout evaluation function.
The policy network reduces the width of the search from 200-odd possible moves to the 4 or 5 best moves. The policy network expands the tree from these 4 or 5 steps which need consideration. The value network helps in cutting down the depth of the tree search by instantly returning the outcome of the game from that position. Finally, the move with the highest Q value is selected, i.e. the step with maximum benefit.
“The game is played primarily through intuition and feel, and because of its beauty, subtlety and intellectual depth it has captured the human imagination for centuries.”
– Demis Hassabis
Application of AlphaGo to real-world problems
The vision of DeepMind, from their website, is very telling – “Solve intelligence. Use this knowledge to make the world a better place”. The end goal of this algorithm is to make it general-purpose so that it can be used to solve complex real-world problems. DeepMind’s AlphaGo is a significant step forward in the quest for AGI. DeepMind has used its technology successfully to solve real-world problems – let’s look at some examples:
Reduction in energy consumption
DeepMind’s AI was successfully utilised to reduce Google’s data centre cooling cost by 40%. In any large-scale energy consuming environment this improvement is a phenomenal step forward. One of the primary sources of energy consumption for a data centre is cooling. A lot of heat generated from running the servers needs to be removed for keeping it operational. This is accomplished by large-scale industrial equipment like pumps, chillers and cooling towers. As the environment of the data centre is very dynamic, it is challenging to operate at optimal energy efficiency. DeepMind’s AI was used to tackle this problem.
First, they proceeded using historical data, which was collected by thousands of sensors within the data centre. Using this data, they trained an ensemble of DNNs on average future Power Usage Effectiveness (PUE). As this is a general-purpose algorithm, it is planned that it will be applied to other challenges as well, in the data centre environment.
The possible applications of this technology include getting more energy from the same unit of input, reducing semiconductor manufacturing energy and water usage, etc. DeepMind announced in its blog post that this knowledge would be shared in a future publication so that other data centres, industrial operators and ultimately the environment can greatly benefit from this significant step.
Popular AI and ML Blogs & Free Courses
Radiotherapy planning for head and neck cancers
DeepMind has collaborated with the radiotherapy department at University College London Hospital’s NHS Foundation Trust, a world leader in cancer treatment.
One in 75 men and one in 150 women are diagnosed with oral cancer in their lifetime. Due to the sensitive nature of the structures and organs in the head and neck area, radiologists need to take extreme care while treating them.
Before radiotherapy is administered, a detailed map needs to be prepared with the areas to be treated and the areas to be avoided. This is known as segmentation. This segmented map is fed into the radiography machine, which will then target cancer cells without harming healthy cells.
In the case of cancer of the head or neck region, this is a painstaking job for the radiologists as it involves very sensitive organs. It takes around four hours for the radiologists to create a segmented map for this area. DeepMind, through its algorithms, is aiming to reduce the time required for generating the segmented maps, from four to one hour. This will significantly free up the radiologist’s time. More importantly, this segmentation algorithm can be utilised for other parts of the body.
To summarise, AlphaGo successfully beat the 18-time world Go champion, Lee Seedol, four times in a best-of-five tournament in 2016. In 2017, it even beat a team of the world’s best players. It uses a combination of DNN and DQN as a policy network for coming up with the next best move, and one DNN as a value network to evaluate the outcome of the game. Monte Carlo tree search is used along with both the policy and value networks to reduce the width and depth of the search – they are used to improve the evaluation function. The ultimate aim of this algorithm is not to solve board games but to invent an Artificial General Intelligence algorithm. AlphaGo is undoubtedly a big step ahead in that direction.
Of course, there have been other effects. As the news of AlphaGo Vs Lee Seedol became viral, the demand for Go boards jumped tenfold. Many stores reported instances of Go boards going out of stock, and it became challenging to purchase a Go board.
Fortunately, I just found one and ordered it for myself and my kid. Are you planning to buy the board and learn Go?
Learn ML courses from the World’s top Universities. Earn Masters, Executive PGP, or Advanced Certificate Programs to fast-track your career.














![15 Interesting MATLAB Project Ideas & Topics For Beginners [2024]](/__khugblog-next/image/?url=https%3A%2F%2Fd14b9ctw0m6fid.cloudfront.net%2Fugblog%2Fwp-content%2Fuploads%2F2020%2F05%2F561-metalab-projects.png&w=3840&q=75)









