









![Dataset Augmentation: Creating Artificial Data [Explained Simply]](/__khugblog-next/image/?url=https%3A%2F%2Fd14b9ctw0m6fid.cloudfront.net%2Fugblog%2Fwp-content%2Fuploads%2F2019%2F07%2FBlog_FI_July_upGrads-Knowledge-base.png&w=1920&q=75)
Introduction
While designing any machine learning algorithm, one always needs to maintain the trade-off between optimization and generalization. These words may seem too intricate for novices, but knowing the difference between them at an early stage during their journey to master machine learning will definitely help them understand the underlying working of why their model behaves in a particular way.
Best Machine Learning and AI Courses Online
The aspect of optimization refers to tuning the model such that its performance on the training data is at its peak. On the other hand, generalization pertains to a learning model’s performance on data that it has never seen before, i.e. on a validation set.
There often comes a time when after a certain number of epochs on the training data, the model’s generalization stops improving and the validation metrics begin to degrade, this is the case where the model is said to overfit, i.e. where it starts learning information specific to the training data but not useful for correlating to new data.

To address the problem of overfitting the best solution is to gather more training data: the more data the model has seen, the better is its probability to learn representations of the new data too. However, gathering more training data may be more expensive than solving the master problem that one needs to tackle. To get around this limitation, we can create fake data and add it to the training set. This is known as data augmentation.
In-demand Machine Learning Skills
Get Machine Learning Certification from the World’s top Universities. Earn Masters, Executive PGP, or Advanced Certificate Programs to fast-track your career.
Data Augmentation in Depth
The premise of learning visual representations from images have helped solve many computer vision problems. However, when we have a smaller dataset to train on, then these visual representations may be misleading. Data augmentation is an excellent strategy to overcome this drawback.
During augmentation, the images in the training set are transformed by certain operations like rotation, scaling, shearing, etc. For example: if the training set consists of images of humans in a standing position only, then the classifier that we are trying to build may fail to predict the images of humans lying down, so augmentation can simulate the image of humans lying down by rotating the pictures of the training set by 90 degrees.
This is a cheap and significant way of extending the dataset and increasing the validation metrics of the model.
Data augmentation is a powerful tool especially for classification problems like object recognition. Operations like translating the training images a few pixels in each direction can often greatly improve generalization.
Another advantageous feature of augmentation is that images are transformed on the flow, which means that existing dataset is not overridden. Augmentation will take place when the images are being loaded into the neural network for training and hence, this will not increase the memory requirements and preserve the data too for further experimentation.
Applying translational techniques like augmentation is very useful where gathering new data is expensive, although one must keep in mind to not apply transformation that may change the existing distribution of the training class. For example, if the training set includes images of handwritten digits from 0 to 9, then flipping/rotating digits “6” and “9” is not an appropriate transformation as this will render the training set obsolete.
Also Read: Top Machine Learning Datasets Project Ideas
Using Data Augmentation with TensorFlow
Augmentation can be achieved by using the ImageDataGenerator API from Keras using TensorFlow as a backend. The ImageDataGenerator instance can perform a number of random transformations on the images at training point. Some of the popular arguments available in this instance are:
- rotation_range: An integer value in degrees between 0-180 to randomly rotate pictures.
- width_shift_range: Shifting the image horizontally around its frame to generate more examples.
- height_shift_range: Shifting the image vertically around its frame to generate more examples.
- shear_range: Apply random shearing transformations on the image to generate multiple examples.
- zoom_range: Relative portion of the image to randomly zoom.
- horizontal_flip: Used for flipping the images horizontally.
- fill_mode: Method for filling newly created pixels.
Below is the code snippet which demonstrates how the ImageDataGenerator instance can be used to perform the aforementioned transformation:
- train_datagen = ImageDataGenerator(
- rescale=1./255,
- rotation_range=40,
- width_shift_range=0.2,
- height_shift_range=0.2,
- shear_range=0.2,
- zoom_range=0.2,
- horizontal_flip=True,
- fill_mode=’nearest’)
It is also trivial to see the result of applying these random transformations on the training set. For this we can display some randomly augmented training images by iterating over the training set:

Figure 1: Images generated using augmentation
(Image from Deep Learning with Python by Francois Chollet, Chapter 5, page 140)
Figure 1 gives us an idea of how augmentation can produce multiple images from a single input image with all the images being superficially different from each other only because of the random transformations that were performed on them at training time.
Popular AI and ML Blogs & Free Courses
To understand the true essence of using augmentation strategies, we must comprehend its impact on the training and validation metrics of the model. For this, we will train two models: one will not use data augmentation and the other will. To validate this, we will use the Cats and Dogs dataset which is available at:
https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
The accuracy curves that were observed for both the models are plotted below:
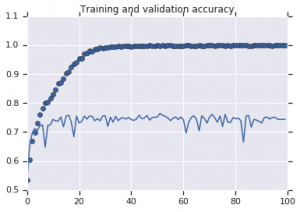
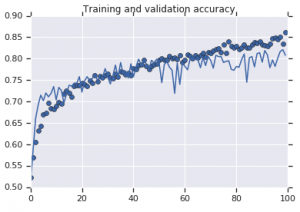
Figure 2: Training and validation accuracy. Left: Model with no augmentation. Right: Model with random data augmentation transforms.
Must Read: Top Estabilished Datasets For Sentiment Analysis
Conclusion
It is evident from Figure 2 that the model trained without augmentation strategies displays low generalization power. The performance of the model on the validation set is not at par with that on the training set. This means that the model has overfitted.
On the other hand, the second model that uses augmentation strategies show excellent metrics with the validation accuracy climbing as high as the training accuracy. This demonstrates how useful it becomes to employ dataset augmentation techniques where a model shows signs of overfitting.
If you’re further interested in learning about sentiment analysis and the technologies associated, such as artificial intelligence and machine learning, you can check our PG Diploma in Machine Learning and AI course.














![15 Interesting MATLAB Project Ideas & Topics For Beginners [2024]](/__khugblog-next/image/?url=https%3A%2F%2Fd14b9ctw0m6fid.cloudfront.net%2Fugblog%2Fwp-content%2Fuploads%2F2020%2F05%2F561-metalab-projects.png&w=3840&q=75)









