










The pace of the data world is neck breaking and with the number of solutions it is putting out, data remains a conduit commodity. To manage and maintain it, there needs to be a storage space. That’s the purpose of data lakes and data warehouses, to be the central repository to store all structured or unstructured data, as-is.
Modern datalakes have taken it to the clouds enabling greater capacity and efficiency in managing, storing and generating value of the data by consolidating it in the correct manner so that it’s more accessible to organisations.
Every technology however, comes without its unique set of challenges.
The process of loading the data itself
Most cloud big data storage systems don’t quite get how to handle incremental changes to data. As a result, rather than loading data incrementally, many organizations constantly reload entire, very large tables into their data lake which can be cumbersome. Doing so on a cloud platform can get even trickier!
Lack of proper planning for ad-hoc and/or production ready data
Several companies may prefer open source solutions as they quite frankly, save money, but these tools have their flaws and they can, in the end, cost more than other non-open source solutions. This also hinders in creating an organisational data pipeline(s).
Learn data science courses from the World’s top Universities. Earn Executive PG Programs, Advanced Certificate Programs, or Masters Programs to fast-track your career.
Keeping up with constant data evolution
Data needs to transcend the cloud/on-premise choices. With the speed of change, companies need to switch between and/or incorporate more than one cloud vendor and simply be more adaptive.
Managing hybrid environments
Because companies will have multi and hybrid cloud environments as some already do, they have to be able to build and manage data workflows.
Trying to find the optimum way of storing data that includes saving money by switching from Hadoop, which is already a less expensive data management platform than traditional data warehouses to companies are moving towards more open source platforms like MinIO, Presto and several others.
MinIO can be thought of as an alternate storage compared to HDFS/Hadoop. While MinIO is an object store, HDFS aka Hadoop Distributed File System is appropriate for block storage. Which means that we cannot use HDFS to store the streaming data – one the reasons for the shift towards MinIO as a data lake. Let’s take a deep dive into other pros and cons of the same.
1. Speed
In a test run by Min.io itself, both systems were run in the Amazon public cloud. There was an initial data generation procedure and then three Hadoop process execution times were examined – Sort, Terasort and Wordcount – first using Hadoop Distributed File System (HDFS) and then MinIO software. MinIO demonstrated its storage can run up to 93 per cent faster than a Hadoop system.

2. Market adoption
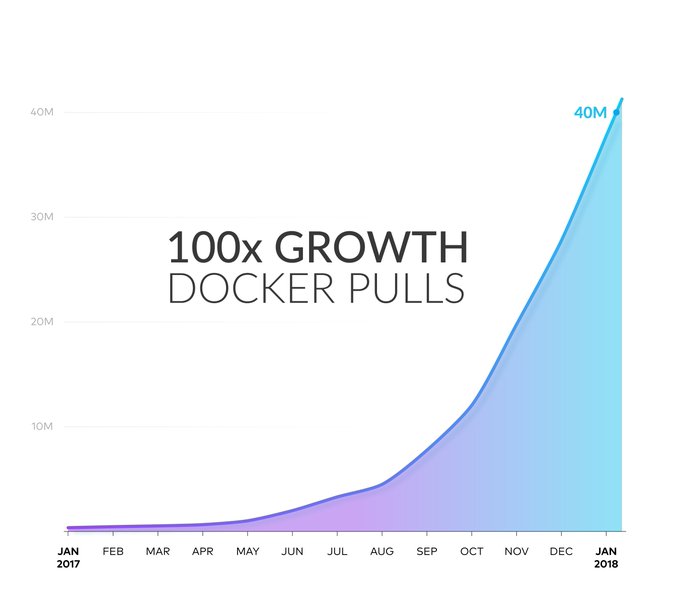
Although Hadoop’s market share has been steadily declining, due to multi channel data processing in most companies, Hadoop saw an uptick this year. At the same time, there has been a meteoric rise in Minio’s growth with a record number of more than 42 million docker pulls as their official handle on Twitter in 2018.
Explore our Popular Data Science Certifications
Since it became publicly available in 2017, MinIO has become one of the more popular open source projects, with more than 400 contributors. The software averages 85,000 downloads per day. It has more than 247 million Docker pulls now and nearly 18,000 stars on GitHub. It’s safe to say it’s popular!

Our learners also read: Learn Python Online for Free
3. Ease of use
With higher user approval, the Apache Hadoop framework allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. On the other hand, Minio is an object storage server compatible with Amazon S3 and licensed under Apache 2.0 License.

Source : atscale, datanami, stackshare, blocksandfiles, infoworks
Top Data Science Skills to Learn
| SL. No | Top Data Science Skills to Learn | |
| 1 | Data Analysis Programs | Inferential Statistics Programs |
| 2 | Hypothesis Testing Programs | Logistic Regression Programs |
| 3 | Linear Regression Programs | Linear Algebra for Analysis Programs |
upGrad’s Exclusive Data Science Webinar for you –
ODE Thought Leadership Presentation
Read our popular Data Science Articles
Conclusion
Data warehousing technology to be fair has been burning out and modern data lakes are powered by cloud services which offer cheaper and more competent ways of storing data and unifying all under one service for facilitating data analytics. Most likely, organizations that already have many data warehouses that consolidation is not an option and they absolutely have to explore the next generation of emerging data virtualization technologies.






































![Data Mining Techniques & Tools: Types of Data, Methods, Applications [With Examples]](/__khugblog-next/image/?url=https%3A%2F%2Fd14b9ctw0m6fid.cloudfront.net%2Fugblog%2Fwp-content%2Fuploads%2F2020%2F04%2F437.png&w=3840&q=75)
![17 Must Read Pandas Interview Questions & Answers [For Freshers & Experienced]](/__khugblog-next/image/?url=https%3A%2F%2Fd14b9ctw0m6fid.cloudfront.net%2Fhttps%3A%2F%2Fec2-3-7-241-34.ap-south-1.compute.amazonaws.com%2Fblog%2Fwp-content%2Fuploads%2F2020%2F07%2F780.png&w=3840&q=75)



![Most Common Binary Tree Interview Questions & Answers [For Freshers & Experienced]](/__khugblog-next/image/?url=https%3A%2F%2Fd14b9ctw0m6fid.cloudfront.net%2Fugblog%2Fwp-content%2Fuploads%2F2020%2F12%2F1529.png&w=3840&q=75)


