










Synthetic data is a form of data that creates real-world patterns using machine learning technologies. Synthetic data has been around us for a while, but industries have realised their potential recently. Today, synthetic data is creating a worldwide impact and is upending the entire value system of artificial intelligence.
While businesses deal with a huge quantum of data daily, they need to devise an economical and uncomplicated way to extract the data and then use it to obtain insights. Here’s where synthetic data comes into play.
Let’s dive deep into the evolving future of synthetic data and how it is increasingly being used across industries.
Enrol for the Machine Learning Course from the World’s top Universities. Earn Master, Executive PGP, or Advanced Certificate Programs to fast-track your career.

What is Synthetic Data?
Synthetic data is generated with the help of artificial intelligence models that work on data samples brought to use in the real world. The essence of synthetic data is how it is generated. The AI algorithm is designed to understand different patterns and statistical relations of the data so that the model can generate synthetic data based on the understanding of the sample data.
Synthetic data generation does not alter the properties of the data. It has the same look and feels as the original data sample. Since the synthetic dataset has the same insights and correlations as the original dataset, it is an ideal substitute for the original data.
Why is Synthetic Data Used?
While several use cases of synthetic data exist, it is primarily used to replicate and replace the original data. It is quite commonly used as training data to create different machine-learning models. Several data engineers also use synthetic data as test data if they need a database for software testing.
Data engineers and scientists do not want to alter real data’s properties and constituents. Hence, they work on synthetic versions of the original data to get the same results without changing the original data. These engineers also use synthetic data to create different synthetic data assets that can be used to improve the existing machine learning modules.
Earlier, synthetic datasets were generated in the form of images. These images were then used to train computer vision algorithms. Companies across industries and even the government use techniques like data masking to generate synthetic data. However, the sensitive parts of the data get hidden during the data masking process. Hence, the companies have to trade off between utility and privacy. With synthetic data, companies and data engineers can ensure the data’s privacy and provide utility simultaneously.
How to Generate Synthetic Data?
Synthetic data generation involves different steps and can be carried out differently. There are two primary ways of synthetic data generation. Let’s have a look at these ways.

Deep Learning-Based Methods
Two deep learning methods are used to generate synthetic data: The use of GANs and the use of a variational autoencoder.
Using Generative Adversarial Networks (GANs)
The GANs are made of two neural network models. These models are known as generators and discriminators, and they co-exist in a zero-sum game where one gains and the other loses. The primary objective of these GANs is to replicate the original data and give the discriminators an impression of the real data.
Firstly, random noise is given as input to the generator module. The module then produces a replica of the original data and passes it on to the discriminator to make a comparison against the real-world data.
Post this, the discriminator compares the replica data sample and gives it either a ‘real’ or a ‘fake’ label. The entire process continues until the discriminator can no longer distinguish between the real data set and the fake one.
Using Variational Autoencoder
In the case of a variational autoencoder, the real data is compressed with the encoder and transmitted to the decoder. The decoder creates a replica of the data set that represents the real data set in every possible way. The system optimises the correlation between the data that is given as the input and the data that gets generated.
3D Rendering-Based Methods
Several data engineers and scientists use 3D rendering-based methods for synthetic data generation. Here, 3D models of different objects are prepared and generated and are then placed in a simulated environment. These are rendered into synthetic images and later used for model training.
A photorealistic virtual world is created out of which different images are extracted. The 3D renderer will automatically annotate the synthetic data once it has been 3D rendered.
Where do Data Scientists and Managers Use It?
Synthetic data has several use cases and have found interesting applications across industries. Let’s look at some areas making innovative and interesting usage of synthetic data.
Self-Driving Vehicles
Self-driving cars and other vehicles are making active use of synthetic data. Automobile engineers and manufacturers use real-world data to train these vehicles to adhere to the safety monitoring systems. Hence, once the model gets trained well, the collision rates resulting from distracted driving reduce drastically.
Most OEMs need more resources to produce original data sets that can be used to build and test millions of vehicles in different geographical setups. Hence, synthetic data solves the problem by allowing manufacturers to create several simulated environments in large numbers without deriving datasets from the real world.
Healthcare
Healthcare is one of those industries where data safety is a major challenge. Using synthetic data instead of data generated from different real-life events can help healthcare institutions to work with and share data without compromising privacy.
Retail
In retail, image recognition is becoming a widely used technique to create intelligent shopping carts. With these shopping carts, shoppers can shop from a store without waiting in a queue. Here, the synthetic images of a store item are being used to train the machine-learning algorithm, enabling shoppers to shop at ease.
Best Machine Learning and AI Courses Online
Robotics
Several robotics companies are now developing different synthetic data generation tools that aid them in creating different simulation applications. These tools are used to develop and manage different real-life working robots.
Top Synthetic Datasets
A few standard synthetic datasets are used to train and improve different machine-learning algorithms. Some of these datasets include the following:
SVIRO Dataset
The SVIRO is a synthetic dataset widely used in the automotive industry to detect the vehicle’s rear seat occupancy. SVIRO stands for Synthetic Dataset for Vehicle Interior Rear seat Occupancy. The dataset includes 25.000 scenes from ten distinct vehicles, allowing you to provide simulated sensor inputs.
SIDOD
SIDOD stands for Synthetic Image Dataset for 3D Object Pose Recognition with Distractors. NVIDIA Deep Learning Data Synthesizer has generated this dataset, and it finds its use in different object-detecting programs and applications. The dataset comprises 144k stereo images from 18 camera angles in a photorealistic virtual environment.
Top Synthetic Data Generators
If you want to generate synthetic data to train different models, several synthetic data generators can help you. Some of these data generators include the following:
Chooch AI
This tool uses OBJ 3D geometry files to generate several synthetic images along with the bounding box annotations. The generator is fast and has quite an interactive platform.
Synthesis AI
Several companies use Synthesis AI to create training datasets for different computer vision models. It is known for generating millions of images that are labelled perfectly. The tool uses a combination of multiple technologies, like generative AI, cinematic VFX rendering, etc., to develop these images.
Datagen
Datagen is another synthetic data generation platform that offers a customisable sandbox and creates dynamic environments. They provide high-performance synthetic data that can help develop different human-centric computer vision applications.
Neurolabs
Neurolabs is a data generator that is being used in the retail and consumer goods space. The platform gives you access to several image recognition datasets for thousands of objects sold in a retail store.
Challenges in Synthetic Data
While synthetic data is being increasingly used everywhere, it presents different challenges. These challenges stem from its adoption. Let’s look at the challenges that can affect synthetic data adoption:
- Factoring in outliers while generating synthetic data can be a problem. Programming rare events into the data distribution system can be quite difficult.
- The quality of the variable data heavily depends on the input data. Hence, strict quality control is important to avoid generating problematic data samples.
- Synthetic data replicate some of the statistical characteristics of the input data. So, it might overlook some unpredictable real-world data behaviour.
The Way Forward
AI is currently at a very nascent stage, but synthetic data will fuel the future of AI. As Gartner estimates, synthetic datasets will completely replace real datasets by 2030.
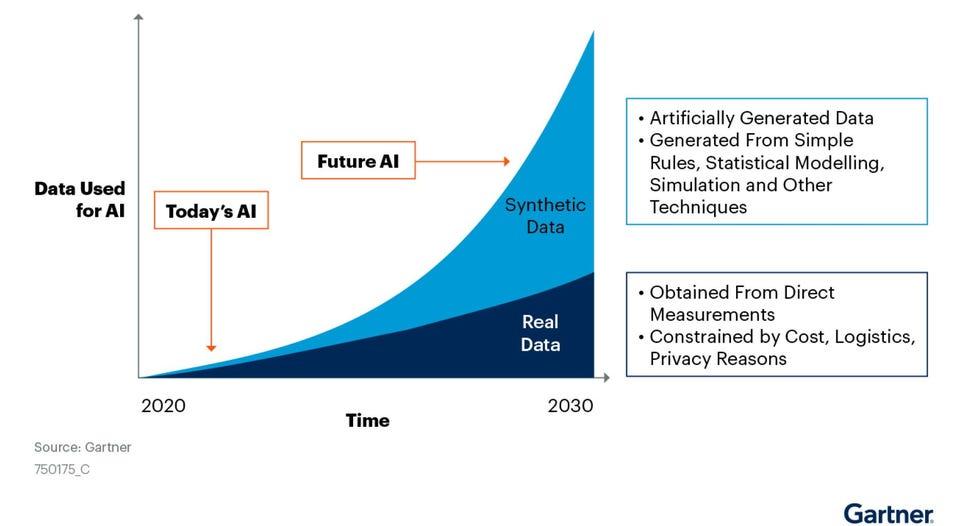
Synthetic data will undermine the value of proprietary data assets as a long-lasting competitive advantage by making high-quality training data significantly more available and affordable.
It will level the playing field by democratising access to data at scale, allowing smaller start-ups to compete with more established firms that they might otherwise have had little chance of defeating.
In-demand Machine Learning Skills
Takeaway
- Acquiring new datasets to train different computer vision models can turn out to be an expensive and cumbersome task. These issues can be easily handled by generating and using synthetic data.
- Several popular datasets are available to the public. They can use different versions of this dataset to train models.
- Compared to augmented data, synthetic data has a much greater ability to imitate natural data distribution and enhance genuine datasets.
- Synthetic data is being used across industries like autonomous driving, retail, etc.
Conclusion
Synthetic datasets are now being used increasingly across industries. While adopting this form of data comes with a few challenges, you need to understand how to work with it in a data-driven organisation.
It’s time to upskill yourself with upGrad.
upGrad’s Advanced Certificate Programme in Machine Learning & NLP offered by IIT-B creates an excellent opportunity to stay abreast with the world of synthetic data so that you can become an indispensable part of the industry.
Candidates will be endowed with all the necessary abilities to establish themselves as industry expert because they will be equipped with in-demand talents like Data Visualisation, Advanced SQL, Deep Learning, Advanced Regression, and more.
upGrad advantages, including cross-cultural peer networking, immersive learning, round-the-clock student assistance, and career boot camp, further demonstrate the program’s extraordinary value to your application.
Enrol right away to get your upGrad journey started!














![15 Interesting MATLAB Project Ideas & Topics For Beginners [2024]](/__khugblog-next/image/?url=https%3A%2F%2Fd14b9ctw0m6fid.cloudfront.net%2Fugblog%2Fwp-content%2Fuploads%2F2020%2F05%2F561-metalab-projects.png&w=3840&q=75)









