










What is Machine Learning?
Machine learning is a division of Artificial Intelligence that learns from available data, examples, and experiences to mimic human behaviour and intelligence. A program created using machine learning can build logic on its own without a human having to manually write the code.
Top Machine Learning and AI Courses Online
It all began with The Turing Test in the early 1950s when Alan Turning concluded that for a computer to have real intelligence, it would need to manipulate or convince a human that it was human too. Machine learning is a relatively old concept but it’s only today that this emerging field is subject to realization since computers now can process complex algorithms. Machine learning algorithms have evolved over the past decade to include complex computational skills which in turn has led to an enhancement in their mimicking capabilities.
Machine learning applications have also increased at an alarming rate. From healthcare, finance, analytics, and education, to manufacturing, marketing, and government operations, every industry has seen a significant boost in quality and efficiency after implementing machine learning technologies. There have been widespread qualitative improvements all over the world, hence, driving the demand for machine learning professionals.

Trending Machine Learning Skills
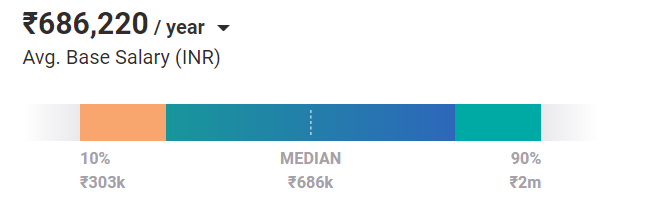
On average, Machine Learning Engineers are worth a salary of ₹686,220 /year today. And that is the case for an entry-level position. With experience and skills, they can earn up to ₹2m /year in India.
Types of Machine Learning Algorithms
Machine learning algorithms are of three types:
1. Supervised Learning: In this type of learning, training data sets guide an algorithm to making accurate predictions or analytical decisions. It employs learning from past training datasets to process new data. Here are a few examples of supervised learning machine learning models:
2. Unsupervised Learning: In this type of learning, a machine learning model learns from unlabeled pieces of information. It employs data clustering by grouping objects or understanding the relationship between them, or exploiting their statistical properties to conduct analysis. Examples of unsupervised learning algorithms are:
-
- K-means clustering
- Hierarchical clustering
3. Reinforcement Learning: This process is based on hit and trial. It is learning by interacting with space or an environment. An RL algorithm learns from its past experiences by interacting with the environment and determining the best course of action.
How to Implement Machine Learning with Java?
Java is among the top programming languages used for implementing machine learning algorithms. Most of its libraries are open-source, providing extensive documentation support, easy maintenance, marketability, and easy readability.
Depending on the popularity, here are the top 10 machine learning libraries used to implement machine learning in Java.
1. ADAMS
Advanced-Data mining And Machine learning System or ADAMS is concerned with building a novel and flexible workflow systems and to manage complex real-world processes. ADAMS employs a tree-like architecture to manage data flow instead of making manual input-output connections.
It eliminates any need for explicit connections. It is based on the “less is more” principle and performs retrieval, visualization, and data-driven visualizations. ADAMS is adept at data processing, data streaming, managing databases, scripting, and documentation.
2. JavaML
JavaML offers a variety of ML and data mining algorithms that are written for Java to support software engineers, programmers, data scientists, and researchers. Every algorithm has a common interface that is easy to use and has extensive documentation support even though there is no GUI.
It is rather simple and straightforward to implement in comparison with other clustering algorithms. Its core features include data manipulation, documentation, database management, data classification, clustering, feature selection, and so on.
Join the ML Course online from the World’s top Universities – Masters, Executive Post Graduate Programs, and Advanced Certificate Program in ML & AI to fast-track your career.
3. WEKA
Weka is also an open-source machine learning library written for Java that supports deep learning. It provides a set of machine learning algorithms and finds extensive use in data mining, data preparation, data clustering, data visualization, and regression, among other data operations.
Example: We will demonstrate this using a small diabetes dataset.
Step 1: Load the data using Weka
| import weka.core.Instances;
import weka.core.converters.ConverterUtils.DataSource; public class Main { public static void main(String[] args) throws Exception { // Specifying the datasource DataSource dataSource = new DataSource(“data.arff”); // Loading the dataset Instances dataInstances = dataSource.getDataSet(); // Displaying the number of instances log.info(“The number of loaded instances is: ” + dataInstances.numInstances()); log.info(“data:” + dataInstances.toString()); } } |
Step 2: The dataset has 768 instances. We need to access the number of attributes, i.e., 9.
| log.info(“The number of attributes (features) in the dataset: ” + dataInstances.numAttributes()); |
Step 3: We need to determine the target column before we build a model and find the number of classes.
| // Identifying the label index
dataInstances.setClassIndex(dataInstances.numAttributes() – 1); // Getting the number of log.info(“The number of classes: ” + dataInstances.numClasses()); |
Step 4: We will now build the model using a simple tree classifier, J48.
| // Creating a decision tree classifier
J48 treeClassifier = new J48(); treeClassifier.setOptions(new String[] { “-U” }); treeClassifier.buildClassifier(dataInstances); |
The code above highlights how to create an unpruned tree that consists of the data instances required for model training. Once the tree structure is printed after the model training, we can determine how the rules were built internally.
| plas <= 127
| mass <= 26.4 | | preg <= 7: tested_negative (117.0/1.0) | | preg > 7 | | | mass <= 0: tested_positive (2.0) | | | mass > 0: tested_negative (13.0) | mass > 26.4 | | age <= 28: tested_negative (180.0/22.0) | | age > 28 | | | plas <= 99: tested_negative (55.0/10.0) | | | plas > 99 | | | | pedi <= 0.56: tested_negative (84.0/34.0) | | | | pedi > 0.56 | | | | | preg <= 6 | | | | | | age <= 30: tested_positive (4.0) | | | | | | age > 30 | | | | | | | age <= 34: tested_negative (7.0/1.0) | | | | | | | age > 34 | | | | | | | | mass <= 33.1: tested_positive (6.0) | | | | | | | | mass > 33.1: tested_negative (4.0/1.0) | | | | | preg > 6: tested_positive (13.0) plas > 127 | mass <= 29.9 | | plas <= 145: tested_negative (41.0/6.0) | | plas > 145 | | | age <= 25: tested_negative (4.0) | | | age > 25 | | | | age <= 61 | | | | | mass <= 27.1: tested_positive (12.0/1.0) | | | | | mass > 27.1 | | | | | | pres <= 82 | | | | | | | pedi <= 0.396: tested_positive (8.0/1.0) | | | | | | | pedi > 0.396: tested_negative (3.0) | | | | | | pres > 82: tested_negative (4.0) | | | | age > 61: tested_negative (4.0) | mass > 29.9 | | plas <= 157 | | | pres <= 61: tested_positive (15.0/1.0) | | | pres > 61 | | | | age <= 30: tested_negative (40.0/13.0) | | | | age > 30: tested_positive (60.0/17.0) | | plas > 157: tested_positive (92.0/12.0) Number of Leaves : 22 Size of the tree : 43 |
4. Apache Mahaut
Mahaut is a collection of algorithms to help implement machine learning using Java. It is a scalable linear algebra framework using which developers can carry out mathematics, statisticians analytics. It is usually used by data scientists, research engineers, and analytics professionals to build enterprise-ready applications. Its scalability and flexibility allows users to implement data clustering, recommendation systems, and create performant Machine learning apps quickly and easily.
5. Deeplearning4j
Deeplearning4j is a programming library that is written in Java and offers extensive support for deep learning. It is an open-source framework that combines deep neural networks and deep reinforcement learning to serve business operations. It is compatible with Scala, Kotlin, Apache Spark, Hadoop, and other JVM languages and big data computing frameworks.
It is typically used to detect patterns and emotions in voice, speech, and written text. It serves as a DIY tool that can discover discrepancies in transactions, and handle multiple tasks. It is a commercial-grade, distributed library that has detailed API documentation owing to its open-sourced nature.
Here is an example of how you can implement machine learning using Deeplearning4j.
Example: Using Deeplearning4j, we will build a Convolution Neural Network (CNN) model to classify the handwritten digits with the help of the MNIST library.
Step 1: Load the dataset to display its size.
| DataSetIterator MNISTTrain = new MnistDataSetIterator(batchSize,true,seed);
DataSetIterator MNISTTest = new MnistDataSetIterator(batchSize,false,seed); |
Step 2: Ensure that the dataset gives us ten unique labels.
| log.info(“The number of total labels found in the training dataset ” + MNISTTrain.totalOutcomes());
log.info(“The number of total labels found in the test dataset ” + MNISTTest.totalOutcomes()); |
Step 3: Now, we will configure the model architecture using two convolution layers along with a flattened layer to display the output.
There are options in Deeplearning4j which allow you to initialize the weight scheme.
| // Building the CNN model
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder() .seed(seed) // random seed .l2(0.0005) // regularization .weightInit(WeightInit.XAVIER) // initialization of the weight scheme .updater(new Adam(1e-3)) // Setting the optimization algorithm .list() .layer(new ConvolutionLayer.Builder(5, 5) //Setting the stride, the kernel size, and the activation function. .nIn(nChannels) .stride(1,1) .nOut(20) .activation(Activation.IDENTITY) .build()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // downsampling the convolution .kernelSize(2,2) .stride(2,2) .build()) .layer(new ConvolutionLayer.Builder(5, 5) // Setting the stride, kernel size, and the activation function. .stride(1,1) .nOut(50) .activation(Activation.IDENTITY) .build()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // downsampling the convolution .kernelSize(2,2) .stride(2,2) .build()) .layer(new DenseLayer.Builder().activation(Activation.RELU) .nOut(500).build()) .layer(new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD) .nOut(outputNum) .activation(Activation.SOFTMAX) .build()) // the final output layer is 28×28 with a depth of 1. .setInputType(InputType.convolutionalFlat(28,28,1)) .build(); |
Step 4: After we have configured the architecture, we will initialize the mode and the training dataset, and begin the model training.
| MultiLayerNetwork model = new MultiLayerNetwork(conf);
// initialize the model weights. model.init(); log.info(“Step2: start training the model”); //Setting a listener every 10 iterations and evaluate on test set on every epoch model.setListeners(new ScoreIterationListener(10), new EvaluativeListener(MNISTTest, 1, InvocationType.EPOCH_END)); // Training the model model.fit(MNISTTrain, nEpochs); |
As the model training commences, you will have the confusion matrix of the classification accuracy.
Here’s the accuracy of the model after ten training epochs:
| =========================Confusion Matrix=========================
0 1 2 3 4 5 6 7 8 9 ————————————————— 977 0 0 0 0 0 1 1 1 0 | 0 = 0 0 1131 0 1 0 1 2 0 0 0 | 1 = 1 1 2 1019 3 0 0 0 3 4 0 | 2 = 2 0 0 1 1004 0 1 0 1 3 0 | 3 = 3 0 0 0 0 977 0 2 0 1 2 | 4 = 4 1 0 0 9 0 879 1 0 1 1 | 5 = 5 4 2 0 0 1 1 949 0 1 0 | 6 = 6 0 4 2 1 1 0 0 1018 1 1 | 7 = 7 2 0 3 1 0 1 1 2 962 2 | 8 = 8 0 2 0 2 11 2 0 3 2 987 | 9 = 9 |
6. ELKI
Environment for Developing KDD-Applications Supported by Index-structure or ELKI is a collection of built-in algorithms and programs used for data mining. Written in Java, it is an open-source library that comprises highly configurable parameters in algorithms. It is typically used by research scientists and students to gain insights into datasets. As the name suggests, it provides an environment for developing sophisticated data mining programs and databases using an index-structure.
7. JSAT
Java Statistical Analysis Tool or JSAT is a GPL3 library that uses an object-oriented framework to help users implement machine learning with Java. It’s typically used for self-education purposes by students and developers. As compared to other AI implementation libraries, JSAT has the highest number of ML algorithms and is the fastest amongst all frameworks. With zero external dependencies, it is highly flexible and efficient and offers high performance.
8. The Encog Machine Learning Framework
Encog is written in Java and C# and comprises libraries that help implement machine learning algorithms. It is used for building genetic algorithms, Bayesian Networks, statistical models like the Hidden Markov Model, and more.
9. Mallet
Machine Learning for Language Toolkit or Mallet is used in Natural Language Processing (NLP). Like most other ML implementation frameworks, Mallet also provides support for data modelling, data clustering, document processing, document classification, and so on.
Popular AI and ML Blogs & Free Courses
10. Spark MLlib
Spark MLlib is used by businesses to enhance the efficiency and scalability of workflow management. It processes copious amounts of data and supports heavy-loaded ML algorithms.
Checkout: Machine Learning Project Ideas
Conclusion
This brings us to the end of the article. For more information on Machine Learning concepts, get in touch with the top faculty of IIIT Bangalore and Liverpool John Moores University through upGrad‘s Master of Science in Machine Learning & AI program.



















![Artificial Intelligence Salary in India [For Beginners & Experienced] in 2024](/__khugblog-next/image/?url=https%3A%2F%2Fd14b9ctw0m6fid.cloudfront.net%2Fugblog%2Fwp-content%2Fuploads%2F2019%2F11%2F06-banner.png&w=3840&q=75)
![24 Exciting IoT Project Ideas & Topics For Beginners 2024 [Latest]](/__khugblog-next/image/?url=https%3A%2F%2Fd14b9ctw0m6fid.cloudfront.net%2Fugblog%2Fwp-content%2Fuploads%2F2020%2F04%2F280.png&w=3840&q=75)
![Natural Language Processing (NLP) Projects & Topics For Beginners [2023]](/__khugblog-next/image/?url=https%3A%2F%2Fd14b9ctw0m6fid.cloudfront.net%2Fugblog%2Fwp-content%2Fuploads%2F2020%2F05%2F513.png&w=3840&q=75)
![45+ Interesting Machine Learning Project Ideas For Beginners [2024]](/__khugblog-next/image/?url=https%3A%2F%2Fd14b9ctw0m6fid.cloudfront.net%2Fugblog%2Fwp-content%2Fuploads%2F2019%2F07%2FBlog_FI_Machine_Learning_Project_Ideas.png&w=3840&q=75)

